[論文レビュー] Directed Diffusion: Direct Control of Object Placement through Attention Guidance
Directed Diffusion は、ユーザー提供のバウンディングボックスを使用してクロスアテンションマップを編集することにより、テキスト指向拡散における指向オブジェクトの粗い位置制御を追加し、モデル訓練を必要としません。
Text-guided diffusion models such as DALLE-2, Imagen, eDiff-I, and Stable Diffusion are able to generate an effectively endless variety of images given only a short text prompt describing the desired image content. In many cases the images are of very high quality. However, these models often struggle to compose scenes containing several key objects such as characters in specified positional relationships. The missing capability to ``direct'' the placement of characters and objects both within and across images is crucial in storytelling, as recognized in the literature on film and animation theory. In this work, we take a particularly straightforward approach to providing the needed direction. Drawing on the observation that the cross-attention maps for prompt words reflect the spatial layout of objects denoted by those words, we introduce an optimization objective that produces ``activation'' at desired positions in these cross-attention maps. The resulting approach is a step toward generalizing the applicability of text-guided diffusion models beyond single images to collections of related images, as in storybooks. Directed Diffusion provides easy high-level positional control over multiple objects, while making use of an existing pre-trained model and maintaining a coherent blend between the positioned objects and the background. Moreover, it requires only a few lines to implement.
研究の動機と目的
- 拡散生成されたシーンにおける明示的なオブジェクト配置を可能にすることで、物語性と構図性を動機づける。
- 単一の画像内または関連画像群における複数のオブジェクトの位置を、訓練を必要とせずに簡易に制御する方法を提供する。
- 拡散過程を通じて、配置されたオブジェクトと背景との一貫性を拡散過程を通じて保つ。
- 事前学習済みの拡散モデルと統合可能な軽量な実装を提供する。
- 特注の再訓練を要せず、キャラクターやオブジェクトのオープンセット・ゼロショット配置をサポートする。
提案手法
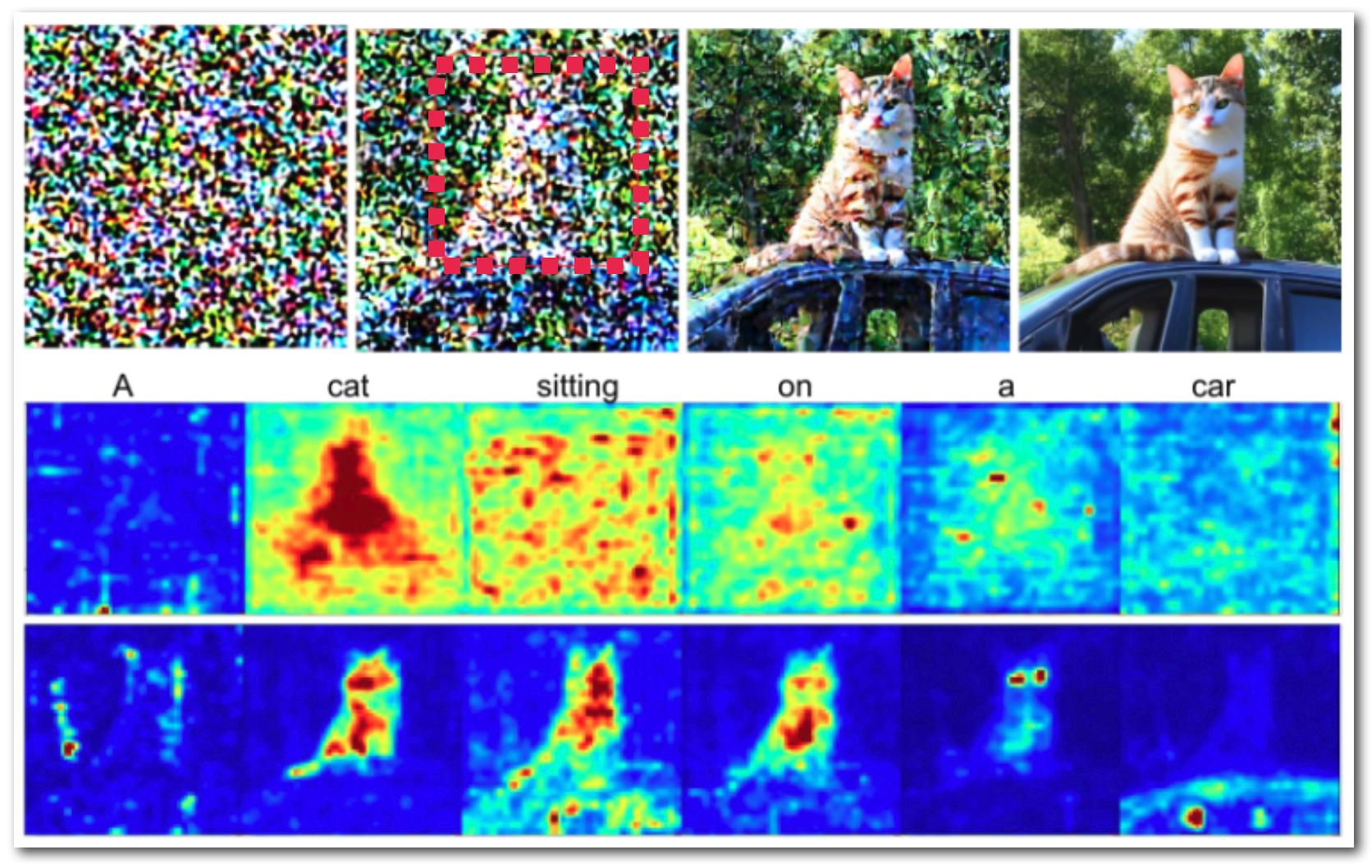
- 事前学習済みの拡散モデルのクロスアテンションマップを活用して、プロンプト語を空間領域と関連付ける。
- デノイジング過程の初期段階でオブジェクト配置を導くため、バウンディングボックスと指向プロンプト語を定義する。
- バウンディングボックス内でガウス重みを用いて後続のクロスアテンションマップを調整するアテンション編集段階を導入する。
- 学習済みの文と画像の関連付けを保持しつつ、 directed アテンションマップをガウシアンターゲットマップと整列させる小さな重みベクトル a を最適化する。
- 初期のデノイジング段階でのアテンション編集を用い、次に分類器フリー指導を伴う従来の拡散デノイジングを行う2段階パイプラインを用いる。
- 最小限のコード変更とモデルのファインチューニングなしで、配置と相互作用の制御を可能にする。

実験結果
リサーチクエスチョン
- RQ1粗いバウンディングボックスベースの指針により、再訓練なしで事前学習済みの拡散モデルに特定オブジェクトの配置を誘導できますか?
- RQ2アテンション誘導配置は、複数の指向オブジェクトとそれらの場の相互作用をどの程度うまく扱えますか?
- RQ3配置されたオブジェクトと背景との間で、文脈的一貫性(照明、影など)を維持しますか?
- RQ4Directed Diffusion は既存のオープンセット配置手法とどう比較されますか(使いやすさと品質の観点で)?
主な発見
- この手法は、事前学習済みモデルのファインチューニングを行うことなく、複数のオブジェクトに対して容易で高次の位置制御を提供します。
- 配置されたオブジェクトは背景と整合的に統合され、影などの文脈的相互作用を示します。
- この手法は、バウンディングボックス内のガウシアンターゲットマップと指向クロスアテンションマップを整列させるために、重みベクトルの小さな最適化を用います。
- このパイプラインは実装に数行のコードしか要せず、事前学習済みモデルのテキストと画像の整合性を維持します。
- シーンやフレームを横断する指向オブジェクトの配置と相互作用を有効にすることで、構成性と物語性の能力が向上します。
- 実験では、プロンプトと合成画像との間のCLIPベースの類似度は、競合手法と同等かそれよりも優れている(論文に記載のとおり)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。