[論文レビュー] Disentangled Sequential Autoencoder
時系列データについて、時に不変な内容と時間変化するダイナミクスを分離して、分離表現を学習する変動オートエンコーダが、動画と音声の制御生成と特徴交換を可能にする。
We present a VAE architecture for encoding and generating high dimensional sequential data, such as video or audio. Our deep generative model learns a latent representation of the data which is split into a static and dynamic part, allowing us to approximately disentangle latent time-dependent features (dynamics) from features which are preserved over time (content). This architecture gives us partial control over generating content and dynamics by conditioning on either one of these sets of features. In our experiments on artificially generated cartoon video clips and voice recordings, we show that we can convert the content of a given sequence into another one by such content swapping. For audio, this allows us to convert a male speaker into a female speaker and vice versa, while for video we can separately manipulate shapes and dynamics. Furthermore, we give empirical evidence for the hypothesis that stochastic RNNs as latent state models are more efficient at compressing and generating long sequences than deterministic ones, which may be relevant for applications in video compression.
研究の動機と目的
- 高次元の逐次データ(動画/音声)の分離表現を学習する動機づけ。
- 時間不変な内容と時間変動するダイナミクスを分離する生成モデルを提案する。
- 制御されたシーケンス生成と特徴交換(内容またはダイナミクス)を実現する。
- 確率的潜在ダイナミクスが長いシーケンスのモデリングと圧縮を改善することを実証的に示す。
- ラベルなしでの動画と音声データへの応用を示す。
提案手法
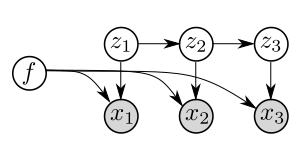
- グローバルな内容潜在変数fとフレームごとのダイナミカル潜在変数z_tを持つVAEベースの生成モデルを提案する。
- p_theta(x_{1:T}, z_{1:T}, f) = p(f) prod_t p(z_t|z_{<t}) p(x_t|z_t, f) と定義する。
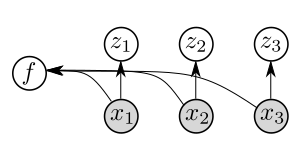
- q(z_{1:T}, f|x_{1:T})を近似するために、因子化されたqと完全なqの2つのエンコーダ設計を用いた近似変分推論を行う。
- 生成をfまたはz_{1:T}のいずれかで条件付けし、シーケンス間で特徴を入れ替えることで、内容-ダイナミクスの分離を探索する。
- 無条件生成と、内容の入れ替え(例: ボイスコンバージョン、アイデンティティとポーズの交換を含む)を含む条件付き生成を実証する。
- 確定的なRNNベースのダイナミクスと比較して、確率的なフレームごとの潜在ダイナミクスは長いシーケンスの生成と再構成において形状と物理をよりよく保持し、欠落フレームがある場合の品質を改善する。
実験結果
リサーチクエスチョン
- RQ1シーケンスにおいて時系列で不変な内容と時間変動するダイナミクスを潜在変数モデルは分離できるか。
- RQ2内容またはダイナミクスで条件付けすることで、動画と音声において制御可能な生成と特徴交換を実現できるか。
- RQ3確率的な per-frame 潜在ダイナミクスは、決定論的ダイナミクスと比較して長いシーケンスの再構成とリアリズムを向上させるか。
- RQ4学習した内容因子fは、シーケンス全体を通じて頑健な話者/アイデンティティや対象アイデンティティ表現として機能するか。
- RQ5明示的なラベルなしでのビデオと音声データに対する分離学習はどの程度うまく機能するか。
主な発見
- モデルは内容とダイナミクスの入れ替えを可能にし、生成シーケンスにおけるアイデンティティと動作の制御を提供する。
- 静的属性(アイデンティティ)は固定された内容をサンプリングしたときに時間を超えて保持され、ダイナミクスは独立して変化できる。
- シーケンス間でfを入れ替えると、ダイナミクスを保持しつつ内容を交換した新しいシーケンスを生成でき、逆も同様である。
- Sprite動画データでは、髪の色や服装などの静的属性を時間とともに保持しつつ、行動を多様化できる。行動トラジェクトリは多モーダル性を示し、未知のケースへの一般化も見られる。
- TIMIT音声データでは、内容潜在を入れ替えることでボイスコンバージョンを実現し、話者変更に対応する分譜のスペクトログラムを得られ、話者認証性能も競合レベルに達した。
- 決定論的なLSTMベースのダイナミクスと比較して、確率的なフレームごとの潜在ダイナミクスは長いシーケンスにおいて形状と物理をより良く保持し、フレーム欠落時の再現/予測品質を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。