[論文レビュー] Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
本論文は Distilled Feature Fields (DFFs) を提案し、2D 視覚言語 priors と 3D 幾何を NeRFs を介して融合することで、ファew-shot および言語指向の 6-DOF ロボット操作をファインチューニングなしで実現します。CLIP/DINO の特徴を 3D 特徴場へ蒸留し、オープンセットの物体把持と言語駆動タスクを示します。
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
研究の動機と目的
- vision-language モデルの 2D セマンティック priors を 3D 幾何と結びつけ、混雑したオープンセット環境で堅牢なロボット操作を実現する。
- 事前学習済みの 2D モデルから蒸留した 3D 特徴場を活用して few-shot 把持・配置を可能にする。
- タスク固有のファインチューニングなしで、自由文の言語ガイダンスにより新規物体の選択と操作を可能にする。
提案手法
- 視覚基盤モデルから密な 2D 特徴を蒸留して 3D NeRF-風の体積へ蒸留することで Distilled Feature Field (DFF) を構築する。
- 3D 蒸留のために CLIP の言語空間に aligned な密なパッチレベル特徴を得るため MaskCLIP を使用する。
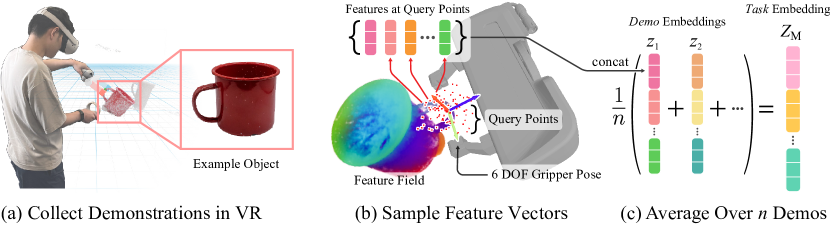
- 6-DOF の把持/配置姿勢を、グリッパフレーム内のクエリ点の集合をサンプリングし、シーンの特徴場から alpha 加重特徴を集約して表現する。
- タスク執行執行の候補把持を、デモの平均化されたタスク執行表現 Z_M と、 transformed 点でクエリされた特徴場とのコサイン類似性を用いて推定し、姿勢最適化と衝突フィルタを行う。
- 言語ガイダンスを組み込むことで、CLIP 埋め込みを介して言語クエリ closest なデモを取得し、姿勢目的関数へ言語ガイダンス項を追加して、再学習なしに自由文本による操作を可能にする。

実験結果
リサーチクエスチョン
- RQ1 Distilled Feature Fields は 2D 視覚言語 priors と 3D 幾何を融合して、混雑したシーンでの開放的・few-shot 操作を可能にするか。
- RQ2 言語による記述は、見たことのない物体カテゴリ・表現への一般化をどの程度導くか。
- RQ3 DFFs を DINO および CLIP の特徴から蒸留した場合、基準手法と比較して 6-DOF 把持/配置の性能はどうなるか。
- RQ4 新規物体カテゴリでのファインチューニングなしのゼロショット言語条件付き操作パイプラインはどれほど有効か。
主な発見
- DFFs は未見の物体シーンでの 6-DOF 把持・配置のためのオープンエンドなシーン理解を可能にする。
- DINO ViT と CLIP ベースの特徴の融合は幾何的・意味的 priors を補完的に提供し、密度・色・中間 NeRF 特徴に依存する基準手法より操作成功率を向上させる。
- CLIP に aligned した特徴場を用いた言語ガイド付き操作は、自由文本クエリによる物体の選択・操作を可能にし、分布外および新規カテゴリへの一般化を促す。
- 混雑環境で複数のタスクと物体に対して成功した把持・配置を示すが、把持回転の精度と関係的・序数的言語詳細を捉える CLIP の限界に起因するいくつかの失敗がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。