[論文レビュー] Distilling a Neural Network Into a Soft Decision Tree
論文は、訓練済みニューラルネットワークから階層的な意思決定を行うソフト決定木へ知識を蒸留する方法を提示し、解釈可能性を高めつつ合理的な精度を保持する。
Deep neural networks have proved to be a very effective way to perform classification tasks. They excel when the input data is high dimensional, the relationship between the input and the output is complicated, and the number of labeled training examples is large. But it is hard to explain why a learned network makes a particular classification decision on a particular test case. This is due to their reliance on distributed hierarchical representations. If we could take the knowledge acquired by the neural net and express the same knowledge in a model that relies on hierarchical decisions instead, explaining a particular decision would be much easier. We describe a way of using a trained neural net to create a type of soft decision tree that generalizes better than one learned directly from the training data.
研究の動機と目的
- 深層ネットの一般化と解釈性の間の緊張感を動機づける。
- ニューラルネットから蒸留されたソフト階層的意思決定木を提案する。
- 蒸留木は生データで訓練した木より一般化性能が良いことを示す。
- MNISTやその他データセットで定性的な解釈性の利点を示す。
提案手法
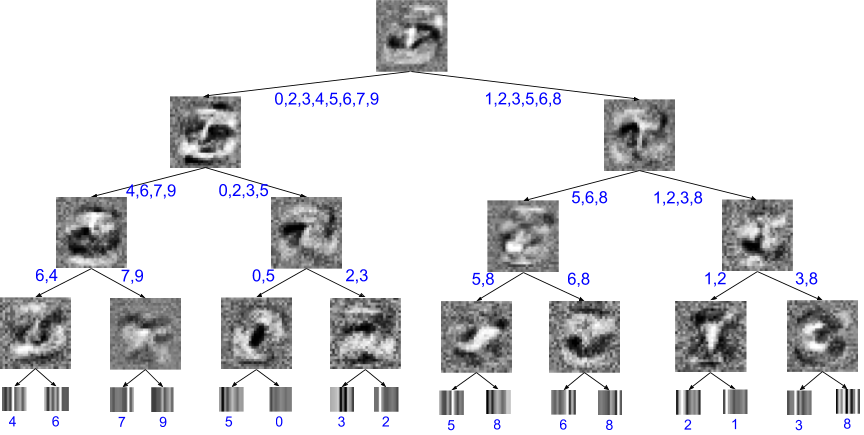
- 内ノードに学習したフィルタを持ち、葉のクラス分布 Q_ell over classes.
- 各 inner node i は p_i(x) = sigma(beta(x w_i + b_i)) を右へ進む確率として計算する。
- 葉はクラス分布 Q^ell_k = exp(phi^ell_k) / sum_k' exp(phi^ell_k').
- ミニバッチ勾配降下法によって L(x) = -log( sum_ell P^ell(x) sum_k T_k log Q^ell_k ) を最小化することで木を訓練する。
- ノード i への平均経路確率 alpha_i に結びつけた深さ依存のクロスエントロピーペナルティを介して部分木のバランスのとれた利用を奨励する正則化。
- 任意でニューラルネットの予測から蒸留する際、真のラベルとNN出力を混ぜ合わせたソフトターゲット T を用いる。
- テスト時には、経路確率が最大の葉を用いて最終予測分布を得る。

実験結果
リサーチクエスチョン
- RQ1ソフト決定木は解釈可能なままニューラルネットの入力-出力関数を模倣できるか?
- RQ2ニューラルネットからの蒸留はデータ上で直接訓練した木よりソフト決定木の精度を改善するか?
- RQ3正則化項と深さに関連するペナルティは学習と一般化にどう影響するか?
主な発見
- MNIST では、真 targets で訓練した深さ8のソフト決定木はテスト精度 94.45% に達する。
- CNN 層を持つニューラルネットは MNIST で 99.21% を達成し、ソフト木より高い。
- ニューラルネットからのソフトターゲットは木を 96.76% のテスト精度に改善し、真のターゲットで訓練した木と NN の間の中間となる。
- ソフトツリーはデータ分布の低階層でのスパース性のため、データ上直接訓練された木より一般化能力が高い。
- データセット全体で蒸留により解釈可能なモデルでも合理的な精度を達成可能であり、例えば Connect4: 80.60% vs 78.63% (NN-free baseline); Letter: 78.0% (depth 9, raw) and 81.0% (distilled from NN ensemble).
- このアプローチは意思決定経路と学習フィルターの解釈可能な可視化を提供し、個々の予測の説明を補助する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。