[論文レビュー] DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving
DistServe は prefill と decoding を別々の GPU に分離し、それらのリソースを共最適化し、配置を最適化して TTFT および TPOT の SLO の下で GPU あたりの良好なグッドプットを向上させ、最先端システムを上回る。
DistServe improves the performance of large language models (LLMs) serving by disaggregating the prefill and decoding computation. Existing LLM serving systems colocate the two phases and batch the computation of prefill and decoding across all users and requests. We find that this strategy not only leads to strong prefill-decoding interferences but also couples the resource allocation and parallelism plans for both phases. LLM applications often emphasize individual latency for each phase: time to first token (TTFT) for the prefill phase and time per output token (TPOT) of each request for the decoding phase. In the presence of stringent latency requirements, existing systems have to prioritize one latency over the other, or over-provision compute resources to meet both. DistServe assigns prefill and decoding computation to different GPUs, hence eliminating prefill-decoding interferences. Given the application's TTFT and TPOT requirements, DistServe co-optimizes the resource allocation and parallelism strategy tailored for each phase. DistServe also places the two phases according to the serving cluster's bandwidth to minimize the communication caused by disaggregation. As a result, DistServe significantly improves LLM serving performance in terms of the maximum rate that can be served within both TTFT and TPOT constraints on each GPU. Our evaluations show that on various popular LLMs, applications, and latency requirements, DistServe can serve 7.4x more requests or 12.6x tighter SLO, compared to state-of-the-art systems, while staying within latency constraints for > 90% of requests.
研究の動機と目的
- TTFTとTPOTの低遅延要件を満たすために、LLM提供を最適化する必要性を動機づける。
- 同一ノード上でのプリフェイルとデコードの干渉とリソース結合を主要なボトルネックとして特定する。
- フェーズ特異的な最適化を可能にするために、prefillとdecodingの分離を提案する。
- 実際のワークロードの下でGPUあたりのグッドプットを最大化するための配置とスケジューリングアルゴリズムを開発する。
- 複数のモデルと待機時間目標にわたって、DistServeを既存システムと比較評価する。
提案手法
- prefillとdecodingのフェーズを別々のGPUへ分離することで干渉を除去する。
- TTFTとTPOTの要件に基づいて、各フェーズのリソース割り当てと並列性を共最適化する。
- 高ノード親和性と低ノード親和性を含む配置アルゴリズムを開発し、GPUあたりのグッドプットを最大化し、レプリケーションを用いてトラフィックレートを満たす。
- メモリ圧力とパイプラインバブルを低減するために、プル型KVキャッシュ伝送を備えたオンラインスケジューリング層を導入する。
- ワークロードを考慮したシミュレーションを用いてSLO達成を推定し、設定探索を導く。
- 最適化された各フェーズの構成をより高いトラフィックへスケールさせるためのレプリケーション戦略を提供する。
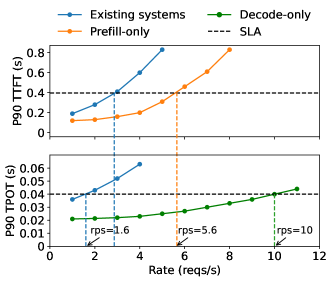
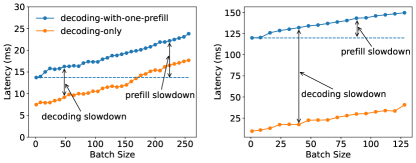
実験結果
リサーチクエスチョン
- RQ1TTFTとTPOTの制約下で、prefillとdecodingのフェーズを分離することでGPUあたりのグッドプットを改善できるか?
- RQ2クラスターのトポロジと帯域幅を考慮して、各フェーズのグッドプットを最大化する配置と並列性の構成はどれか?
- RQ3DistServeは、異なるLLMサイズ、アプリケーション、遅延目標に対して、最先端システムと比較してどのように性能を発揮するか?
- RQ4実用的な課題(例: KVキャッシュ転送、非均一なプロンプト)とは何で、デプロイメントでどのように緩和できるか?
- RQ5オンラインリプランニングは workload の変化に適応するために必要か、そしてそれはどれくらい効果的か?
主な発見
- DistServeは、最先端システムと比較して、待機時間制約下で最大で4.48×多くのリクエストを達成する。
- DistServeは、待機時間制約を最大で10.2×厳格化し、90%超のリクエストで遅延目標を超えずに維持する。
- prefillとdecodingを分離することで、prefill-decodingの干渉を排除し、フェーズ特異的な並列性を可能にする。
- 配置アルゴリズムとレプリケーションは、トラフィックレートを効率的に満たすように、各フェーズのグッドプットをスケールさせる。
- KVキャッシュ伝送は、メモリ圧力とパイプラインバブルを低減するためにプル型機構で管理されている。
- 複数のLLM、アプリケーション、およびレイテンシ要件に対して性能向上が持続する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。