[論文レビュー] Divergence-Augmented Policy Optimization
強化学習の目的関数に発散量ベースの正則化項を追加することで方針最適化に発散度拡張を導入する;状態-行動分布間のBregman発散から導出し、データが不足するオフポリシー再利用においてAtariで性能が向上することを示す。
In deep reinforcement learning, policy optimization methods need to deal with issues such as function approximation and the reuse of off-policy data. Standard policy gradient methods do not handle off-policy data well, leading to premature convergence and instability. This paper introduces a method to stabilize policy optimization when off-policy data are reused. The idea is to include a Bregman divergence between the behavior policy that generates the data and the current policy to ensure small and safe policy updates with off-policy data. The Bregman divergence is calculated between the state distributions of two policies, instead of only on the action probabilities, leading to a divergence augmentation formulation. Empirical experiments on Atari games show that in the data-scarce scenario where the reuse of off-policy data becomes necessary, our method can achieve better performance than other state-of-the-art deep reinforcement learning algorithms.
研究の動機と目的
- オフポリシーデータを再利用する際のポリシー最適化の安定化を動機づける。
- 状態-行動分布の発散に基づく正則化として発散度拡張を導入する。
- Bregman発散とミラーデセント原理に基づいて手法を導出する。
- 発散度拡張更新のための実用的な勾配ベースの最適化スキームを提案する。
提案手法
- 現在の状態-行動分布と以前の分布間のBregman発散を用いて発散度拡張を定義する。
- 発散度拡張をKLベースの更新およびミラー降下(ミラーデセント)ベースの最適化に関連づける。
- 発散度拡張を組み込んだポリシー損失の勾配式を導出する(∇_θ L_π および ∇_θ D_F 項を含む)。
- オフポリシーデータのために V-trace を用いて Q 値と発散項を推定する。
- 勾配ベースの更新を実装する: theta <- theta - alpha_t (∇_θ L_π + b ∇_θ L_v)。
- 軌道収集、オフポリシーサンプリング、勾配更新を交互に実行する実用的なアルゴリズム(DAPO)を提供する。
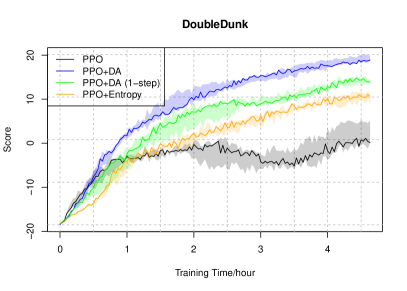
実験結果
リサーチクエスチョン
- RQ1オフポリシー データを再利用する際、発散度拡張はポリシー最適化を安定化させるか。
- RQ2状態-行動分布間のBregman発散をポリシー勾配更新にどのように組み込めるか。
- RQ3データ不足の強化学習設定における発散度拡張の性能影響は何か。
- RQ4DAPO は PPO、TRPO、MPO、MARWIL など既存手法とどのように関連し、どのように異なるか。
主な発見
- データが不足した状況で、DAPO は標準的な PPO より性能を改善できる。
- 発散度拡張は、状態-行動空間に対してBregman発散制約を課すことに対応する。
- 発散項の勾配は、ポリシー勾配法と同様にQ演算子を用いて推定できる。
- 前述のAtari実験によれば、オフポリシー データの再利用時に発散度拡張は有効である。
- このアプローチはオンラインミラー降下と関連し、KLベースのポリシー更新を一般化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。