[論文レビュー] DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
DiverseVul は、18,945 の脆弱な関数を含む大規模で多様な C/C++ 脆弱コードデータセットを 150 の CWE にまたがって導入し、4 つのファミリーにわたる 11 の DL アーキテクチャを分析することで、データ規模とコード特有の事前学習が脆弱性検出性能の鍵となる要因であると指摘しています。
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 18,945 vulnerable functions spanning 150 CWEs and 330,492 non-vulnerable functions extracted from 7,514 commits. Our dataset covers 295 more projects than all previous datasets combined. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. We show that increasing the volume of training data may not further improve the performance of deep learning models for vulnerability detection, but might be useful to improve the generalization ability to unseen projects. We also identify hopeful future research directions. We demonstrate that large language models (LLMs) are a promising research direction for ML-based vulnerability detection, outperforming Graph Neural Networks (GNNs) with code-structure features in our experiments. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.
研究の動機と目的
- 実世界のプロジェクトとセキュリティ問題から、脆弱な関数と非脆弱な C/C++ 関数の大規模で多様なオープンデータセットを作成する。
- このデータセットと既存データセットを用いて、脆弱性検出のための幅広い深層学習アーキテクチャをベンチマークする。
- トレーニングデータ量、モデルアーキテクチャ、事前学習タスクが脆弱性検出性能に与える影響を調査する。
- ラベルノイズと一般化の課題を評価し、未見のプロジェクトでの性能も含めて検討する。
- 大型言語モデルとコード特化の事前学習を用いた機械学習ベースの脆弱性検出を進める有望な方向性を特定する。
提案手法
- セキュリティ問題のウェブサイトをクロールして脆弱性レポートと修正コミットを取得する。
- クローン済みプロジェクトから、修正前のバージョンを脆弱とラベル付けして非脆弱とすることで、脆弱な関数と非脆弱な関数を抽出する。
- 利用可能な場合にはプロジェクトと CWE アノテーションを保持したまま、MD5 で関数の重複を排除する。
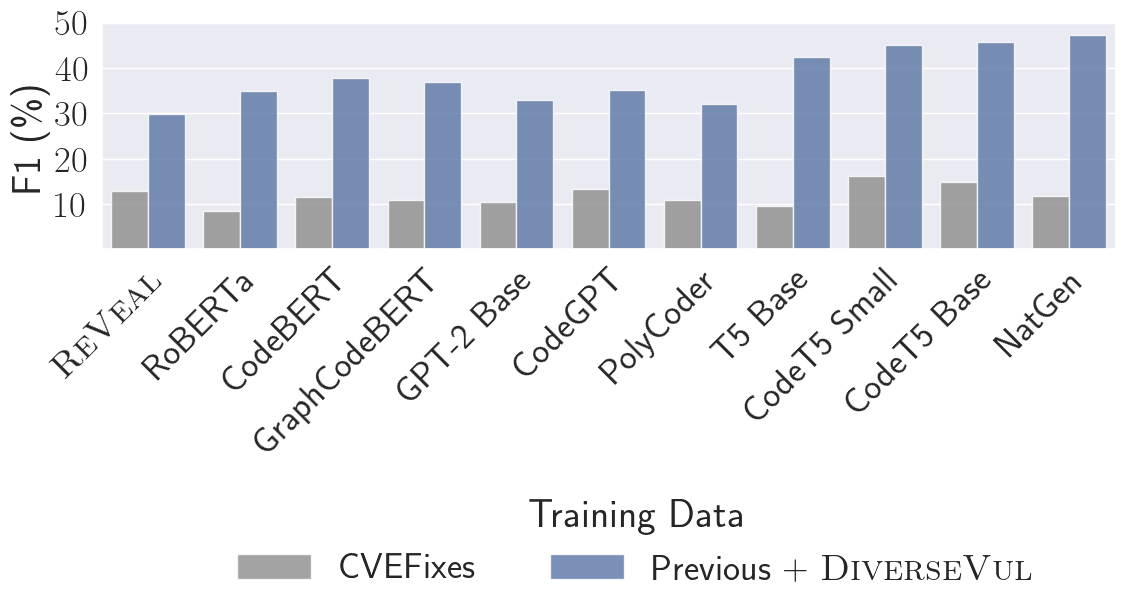
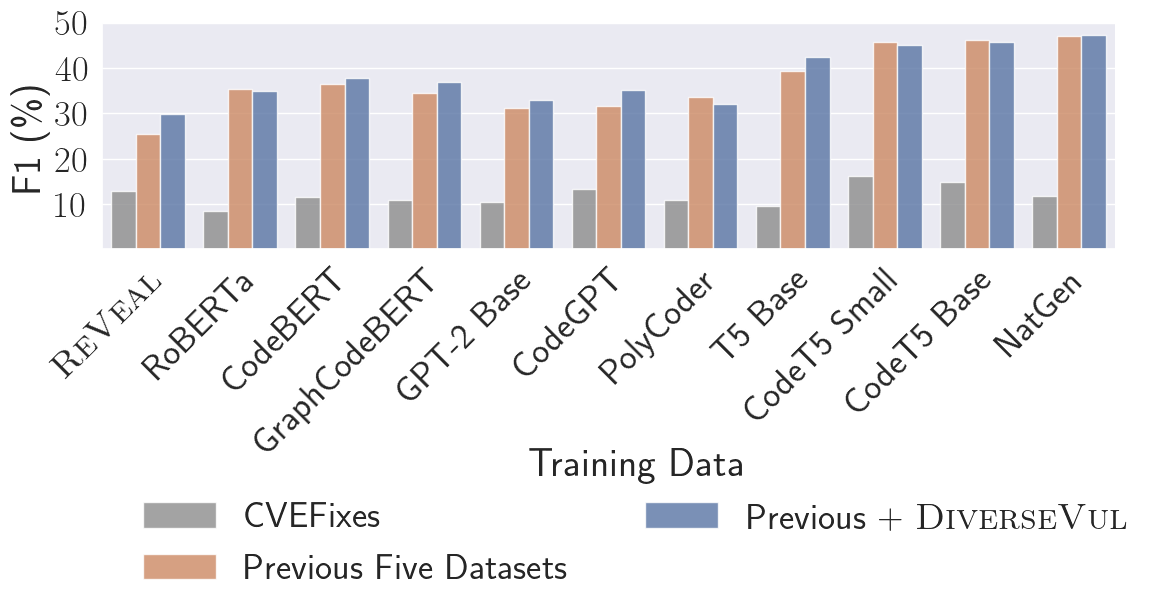
- GNN や Transformer/LLMs を含む 4 ファミリーの 11 モデルアーキテクチャを、3 つのデータ設定(CVEFixes、Previous、Previous+DiverseVul)で評価する。
- 手動サンプリングによるラベルノイズを検査して、ラベル精度を推定する(DiverseVul では約60%)。
- DiverseVul の有無によるモデル性能を比較して、F1、TP レート、FP レートへのデータ規模効果を研究する。
実験結果
リサーチクエスチョン
- RQ1トレーニングデータを増やす(DiverseVul や他のデータセットを通じて)ことで、モデルファミリー間の脆弱性検出性能にどのような影響が生じるか?
- RQ2大規模で多様な脆弱性データセットを学習する際、LLMs はグラフベースのモデルより優れているのか?
- RQ3コードの脆弱性検出を改善するために、どのような事前学習目標が最も効果的か?
- RQ4未見のプロジェクトに対してモデルはどの程度一般化できるのか、一般化のギャップを埋める手法は何か?
- RQ5脆弱性データセットにおけるラベルノイズの程度と影響はどの程度で、モデル評価にどう影響するか?
主な発見
- DiverseVul は 7,514 コミット、150 CWE にわたる脆弱な関数 18,945 および非脆弱な関数 330,492 を追加し、797 プロジェクトにまたがる。
- CVEFixes のみではアーキテクチャ間の差は小さいが、データセットが大きくなるとLLMsがGNNsを大幅に上回る。
- Previous+DiverseVul の統合テストセットでの最高 F1 スコアは 47.2%、真陽性率 43.3%、偽陽性率 3.5% である。
- コード特化タスクで事前学習された LLMs(例: CodeT5 Small/Base, NatGen)は、GNNs に対する最も大きな性能向上をもたらす。
- 未見のプロジェクトでの性能は著しく低下する(例: 見たことのあるプロジェクトでは F1 が 49% だが、未見では 9.4%)と示され、一般化の課題を強調している。
- ラベルの脆弱性ラベルの精度は commit-based signaling によるもので DiverseVul で約60%、データセット全体で顕著なラベルノイズを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。