[論文レビュー] "Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
この研究は、6,387件のin-the-wild promptsを4つのプラットフォームから6か月間にわたり収集・分析し、 jailbreak promptsを特徴づけ、攻撃戦略を特定し、その進化を追跡し、5つのLLMと3つのセーフガードに対する有効性を評価します。
The misuse of large language models (LLMs) has drawn significant attention from the general public and LLM vendors. One particular type of adversarial prompt, known as jailbreak prompt, has emerged as the main attack vector to bypass the safeguards and elicit harmful content from LLMs. In this paper, employing our new framework JailbreakHub, we conduct a comprehensive analysis of 1,405 jailbreak prompts spanning from December 2022 to December 2023. We identify 131 jailbreak communities and discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from online Web communities to prompt-aggregation websites and 28 user accounts have consistently optimized jailbreak prompts over 100 days. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 107,250 samples across 13 forbidden scenarios. Leveraging this dataset, our experiments on six popular LLMs show that their safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify five highly effective jailbreak prompts that achieve 0.95 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and the earliest one has persisted online for over 240 days. We hope that our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.
研究の動機と目的
- 複数のプラットフォームに Across イン・ザ・ wild jailbreak prompts の普及率と特徴を測定する。
- jailbreak prompts を可能にする主要な攻撃戦略とコミュニティ構造を特定する。
- 複数のLLMおよび外部モデレーション セーフガードに対する jailbreak prompts の効果を評価する。
- jailbreak prompts の時間的推移とプラットフォーム間の拡散を分析し、より安全なLLM展開を促進する。
提案手法
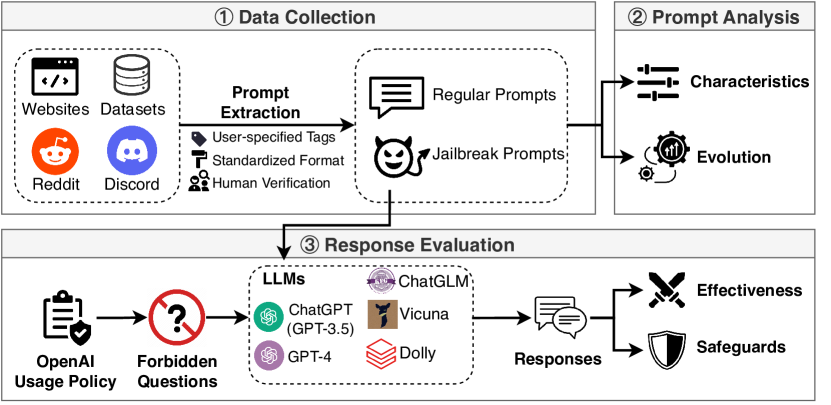
- Reddit、Discord、ウェブサイト、およびオープンソースデータセットからDec 2022–May 2023にまたがる6,387 promptsを収集する。
- 人間による検証で666 jailbreak promptsを特定し、高い評定者間一致を示す(Fleiss’ Kappa = 0.925)。
- NLP指標(長さ、毒性、意味論)とグラフベースのコミュニティ検出を用いて jailbreak promptsを特徴づけ、8つの主要コミュニティを特定する。
- 46,800サンプルの禁断質問セットを13のシナリオで作成し、LLMの抵抗とセーフガードの有効性を評価する。
- 5つのLLM(ChatGPT GPT-3.5、GPT-4、ChatGLM、Dolly、Vicuna)と3つのセーフガード(OpenAI moderation、OpenChatKit、Nemo-Guardrails)を禁断セットで評価する。
- jailbreak promptsの進化、拡散、攻撃有効性を研究するための時間的およびプラットフォーム横断分析を実施する。

実験結果
リサーチクエスチョン
- RQ1現場の jailbreak prompts は通常の prompts と比べて特徴はどうか。
- RQ2Jailbreak prompts を支配する attack strategy とコミュニティはどれで、プラットフォーム間でどう異なるか。
- RQ3現在のLLMと外部セーフガードは、禁断シナリオ全体で jailbreak prompts に対してどれだけ抵抗できるか。
- RQ4 jailbreak prompts は時間とともにどう進化し、プラットフォーム間でどう拡散するか。
- RQ5どのモデルとセーフガードが jailbreak prompts に対してより脆弱か。
主な発見
- Jailbreak prompts は通常の prompts より長く、より毒性が高い傾向がある一方で、意味論的には通常の prompts と同程度の空間を占める。
- 8つの主要な jailbreak コミュニティが prompts の substantial portion(約30%)を説明しており、戦略には prompt injection、privilege escalation、deception、virtualization が含まれる。
- Discord優位の3つのコミュニティは、ターゲット化された目標(下品さの誘発、ポルノ/ヘイトスピーチセーフガードの回避)を示す。
- いくつかの jailbreak prompts は ChatGPT(GPT-3.5)および GPT-4 で ASR が0.99に達することがあり、オンライン上で100日を超えて存続する。
- Dolly(オープンソース、商用利用可能)は禁断シナリオ全般で最小限の抵抗を示し、オープンソースモデルの安全性リスクを浮き彫りにしている。
- 外部セーフガードはASRの削減が限定的で(OpenAI moderation、OpenChatKit、Nemo-Guardrails でそれぞれ0.032、0.058、0.019)、より強力な防御が必要であることを示唆している。
- jailbreak prompts はより短く、より毒性が高く、意味論的に締まる方向へ進化しており、公開プラットフォームから私的プラットフォーム(例: Discord)への移行により検知性が低下する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。