[論文レビュー] Do Membership Inference Attacks Work on Large Language Models?
本研究は、Pileで事前学習した大規模言語モデル(LLMs)に対する複数の membership inference attack(MIA)を系統的に評価し、MIAの性能は領域と規模を問わず概ねランダムに近いことを示す。データ重複、訓練ダイナミクス、分布シフトに起因する例外がいくつかある。
Membership inference attacks (MIAs) attempt to predict whether a particular datapoint is a member of a target model's training data. Despite extensive research on traditional machine learning models, there has been limited work studying MIA on the pre-training data of large language models (LLMs). We perform a large-scale evaluation of MIAs over a suite of language models (LMs) trained on the Pile, ranging from 160M to 12B parameters. We find that MIAs barely outperform random guessing for most settings across varying LLM sizes and domains. Our further analyses reveal that this poor performance can be attributed to (1) the combination of a large dataset and few training iterations, and (2) an inherently fuzzy boundary between members and non-members. We identify specific settings where LLMs have been shown to be vulnerable to membership inference and show that the apparent success in such settings can be attributed to a distribution shift, such as when members and non-members are drawn from the seemingly identical domain but with different temporal ranges. We release our code and data as a unified benchmark package that includes all existing MIAs, supporting future work.
研究の動機と目的
- 大規模言語モデル(LLMs)の事前訓練データに対する既存のMIAの有効性を、複数の領域と規模にわたって評価する。
- LLM事前訓練におけるMIAの効果が低い根本原因を特定し、データ量、エポック数、領域の重複といった要因を分析する。
- 統一されたベンチマークと分析手法を提案し、MIAがLLMsから情報を漏らしうる場合とそうでない場合を理解する。
提案手法
- Pileで訓練されたPythiaおよびPythia-dedupモデル(160M〜12Bパラメータ)に対して5つのMIA(LOSS、参照ベース、zlibエントロピー、近傍、最小k%確率)を評価する。
- 主指標としてAUC ROCを用い、信頼度の高い性能を評価するために補助的にTPR@low-FPRを用いる。
- モデルサイズ、デデュプリケーション、参照モデルの選択が攻撃の有効性に及ぼす影響を分析する。
- メンバーと非メンバーデータのn-gram重複がMIAの識別性にどう影響するかを検討する。
- 非メンバーの時間的シフトやメンバーのデータの修正がMIAの結果に与える影響を調査する。
- Mimirという統一MIAベンチマークパッケージを提供し、言語モデル向けの攻撃実装を含める。
実験結果
リサーチクエスチョン
- RQ1Pile上で事前学習された大規模言語モデルの幅広いサイズに対して、 membership inference attack はランダム推測を有意に上回るか。
- RQ2LLM pre-trainingデータにおけるMIAの有効性に影響を与える要因(モデルサイズ、データデデュプリケーション、訓練エポック、参照モデルの選択)は何か。
- RQ3メンバーと非メンバーのn-gram重複はMIAの性能にどう影響し、重複分析は観測結果を説明できるか。
- RQ4時間的にシフトした非メンバーや意味的・語彙的に近い改変レコードはMIAの結果を意味的に変えるか。
- RQ5生成モデルのためのMIAベンチマークを評価・解釈するのに役立つ principled guidelines(原理的ガイドライン)は何か。
主な発見
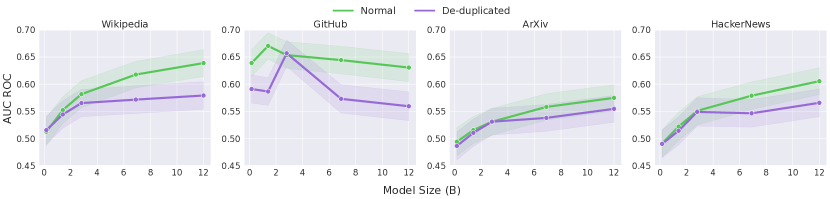
- MIAはほとんどの領域とモデルサイズ(最大12Bパラメータ)で概ねランダムに近い性能(AUC ROC < 0.6)を示す。
- モデルサイズの増加はMIAの性能をわずかに向上させる一方、デデュプリケーションはMIAの有効性を低下させる傾向がある。
- 参照ベースの攻撃は評価されたMIAの中で一部の設定で最も良好な性能を示すが、攻撃間の差は全体的に控えめである。
- メンバーと非メンバーの高いn-gram重複は自然言語ドメインで一般的であり、MIAの識別性を低下させる;重複が少ないほど攻撃性能は向上する可能性がある。
- 非メンバーの時間的シフト(例:新しいデータ)はMIAの性能を高くする傾向があり、分布シフトが漏洩の見かけ上の大きさを膨らませることを示唆する。
- 修正された(語彙的/意味的に近い)メンバー記録でもMIAによって誤分類される可能性があり、生成モデルのメンバーシップを定義する際の曖昧さを強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。