[論文レビュー] DocLLM: A layout-aware generative language model for multimodal document understanding
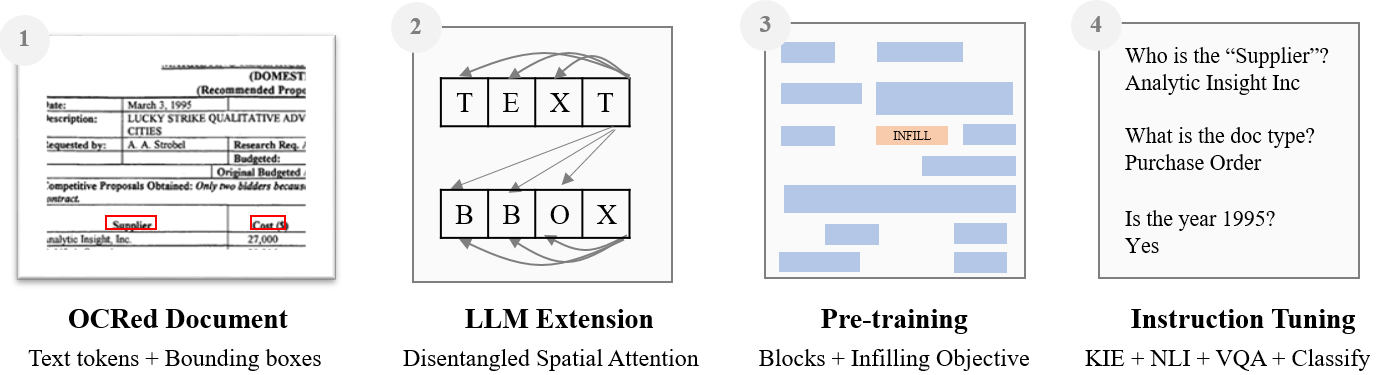
DocLLMは因果型LLMsを分離された空間的注意機構と拡張し、視覚文書におけるテキストとレイアウトを共同でモデル化する。ブロック・インフィリング事前学習と指示調整を用いて、重いビジョンエンコーダなしでVRDUタスクで優れた性能を発揮する。
Enterprise documents such as forms, invoices, receipts, reports, contracts, and other similar records, often carry rich semantics at the intersection of textual and spatial modalities. The visual cues offered by their complex layouts play a crucial role in comprehending these documents effectively. In this paper, we present DocLLM, a lightweight extension to traditional large language models (LLMs) for reasoning over visual documents, taking into account both textual semantics and spatial layout. Our model differs from existing multimodal LLMs by avoiding expensive image encoders and focuses exclusively on bounding box information to incorporate the spatial layout structure. Specifically, the cross-alignment between text and spatial modalities is captured by decomposing the attention mechanism in classical transformers to a set of disentangled matrices. Furthermore, we devise a pre-training objective that learns to infill text segments. This approach allows us to address irregular layouts and heterogeneous content frequently encountered in visual documents. The pre-trained model is fine-tuned using a large-scale instruction dataset, covering four core document intelligence tasks. We demonstrate that our solution outperforms SotA LLMs on 14 out of 16 datasets across all tasks, and generalizes well to 4 out of 5 previously unseen datasets.
研究の動機と目的
- 視覚的に豊かな文書において、レイアウトとテキストの意味論が絡み合う問題を動機づけ、解決する。
- 重いビジョンエンコーダを用いずに空間レイアウトを組み込む軽量モデルを開発する。
- テキストとバウンディングボックス情報間の横断モーダル依存関係を捉える、分離された空間的注意機構を提案する。
- 不規則なレイアウトやテキストのずれを扱うためのブロックレベルのインフィリング事前学習目的を導入する。
- 複数のDocAIタスクにまたがる指示調整データでモデルをファインチューニングし、ロバストなゼロショット汎用性を可能にする。
提案手法
- 因果デコーダLLMを、境界ボックスを介した空間レイアウトを表現する第2のモダリティで拡張する。
- 専用の射影を用いて、text-to-text、text-to-spatial、spatial-to-text、及び spatial-to-spatial のスコアを計算する分離された空間的注意を実装する。
- 前後の文脈の両方を用いて、それらを再構築するようモデルを訓練する、ランダムなテキストブロックをマスクするブロックインフィリング事前学習目的を導入する。
- IIT-CDIPとDocBankの文書コレクションで事前学習を行い、総計3.8Bトークン、1,670万ページ。
- VQA、NLI、KIE、CLS にまたがる16のDocAIデータセット上でテンプレートを用いて指示調整を行い、ゼロショット性能を向上させる。
- ゼロショットおよび指示調整済みベースラインと比較し、レイアウト集約型および文書理解タスクに焦点を当てる。
実験結果
リサーチクエスチョン
- RQ1境界ボックスによるレイアウト情報を付加した軽量LLMは、ビジョンエンコーダなしで競争力のあるVRDU性能を達成できるか。
- RQ2注意機構における空間的モダリティとテキストモダリティを分離することは、視覚的に豊かな文書におけるモーダル間推論を改善するか。
- RQ3ブロックレベルのインフィリング事前学習は、文書の不規則なレイアウトやずれたテキストをより適切に処理できるか。
- RQ4指示調整後、DocLLMは未知のデータセットや主要なDocAIタスクに対してどれだけ一般化できるか。
主な発見
- DocLLM-7BはSDDS設定で16データセット中12データセットで最先端の性能を達成し、いくつかのベースラインを上回る。
- DocLLM-7BおよびDocLLM-1Bは、非ビジョンエンコーダ系のベースラインに対して強い改善を示し、複数タスクでGPT-4 OCRと競合する結果を示す一方、一部のVQAケースではGPT-4が先行する。
- 本モデルはKIEやCLSなどのレイアウト集約型タスクで特に優れ、STDD設定での held-outデータセットへの良好な一般化を示す。
- 16のDocAIデータセットでの指示調整は、VQA、KIE、CLS、NLIタスク全般のゼロショット汎化を改善する。
- 小型のDocLLM-1Bは7B版に近い性能を達成しており、アーキテクチュア設計による効率向上を示す。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。