[論文レビュー] DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task
本論文は、バイリンガルの中国語医療対話モデル(ChatGLM-6B)を LoRA およびその他の効率化技術を用いて DoctorGLM にファインチューニングすることを示し、控えめなハードウェアでの医療分野向けファインチューニングを実現します。多言語医療 LLM の低コストパイプラインを提供し、実用的な結果と制限を共有します。
The recent progress of large language models (LLMs), including ChatGPT and GPT-4, in comprehending and responding to human instructions has been remarkable. Nevertheless, these models typically perform better in English and have not been explicitly trained for the medical domain, resulting in suboptimal precision in diagnoses, drug recommendations, and other medical advice. Additionally, training and deploying a dialogue model is still believed to be impossible for hospitals, hindering the promotion of LLMs. To tackle these challenges, we have collected databases of medical dialogues in Chinese with ChatGPT's help and adopted several techniques to train an easy-deploy LLM. Remarkably, we were able to fine-tune the ChatGLM-6B on a single A100 80G in 13 hours, which means having a healthcare-purpose LLM can be very affordable. DoctorGLM is currently an early-stage engineering attempt and contain various mistakes. We are sharing it with the broader community to invite feedback and suggestions to improve its healthcare-focused capabilities: https://github.com/xionghonglin/DoctorGLM.
研究の動機と目的
- 医療分野や非英語言語に特化した言語モデルの開発を促進する。
- 中国語医療対話モデルをファインチューニングするための低コストでエンドツーエンドのパイプラインを説明する。
- 手頃なハードウェアで医療に焦点を当てた LLM を実現する技術を紹介する。
提案手法
- A100 80G GPU を用いて、中国語医療対話データに LoRA で ChatGLM-6B をファインチューニングする。
- 英語の医療データセットを ChatGPT で中国語に翻訳し、BART ベースのモデルで蒸留する。
- 応答を導くために、疾病知識(Merck Manual由来)を用いたプロンプト設計モジュールを組み込む。
- パラメータ効率の高いファインチューニングのために LoRA と P-tuning V2 を比較する。
- 出力の多様性を管理するために top-p および温度設定で生成を評価する。
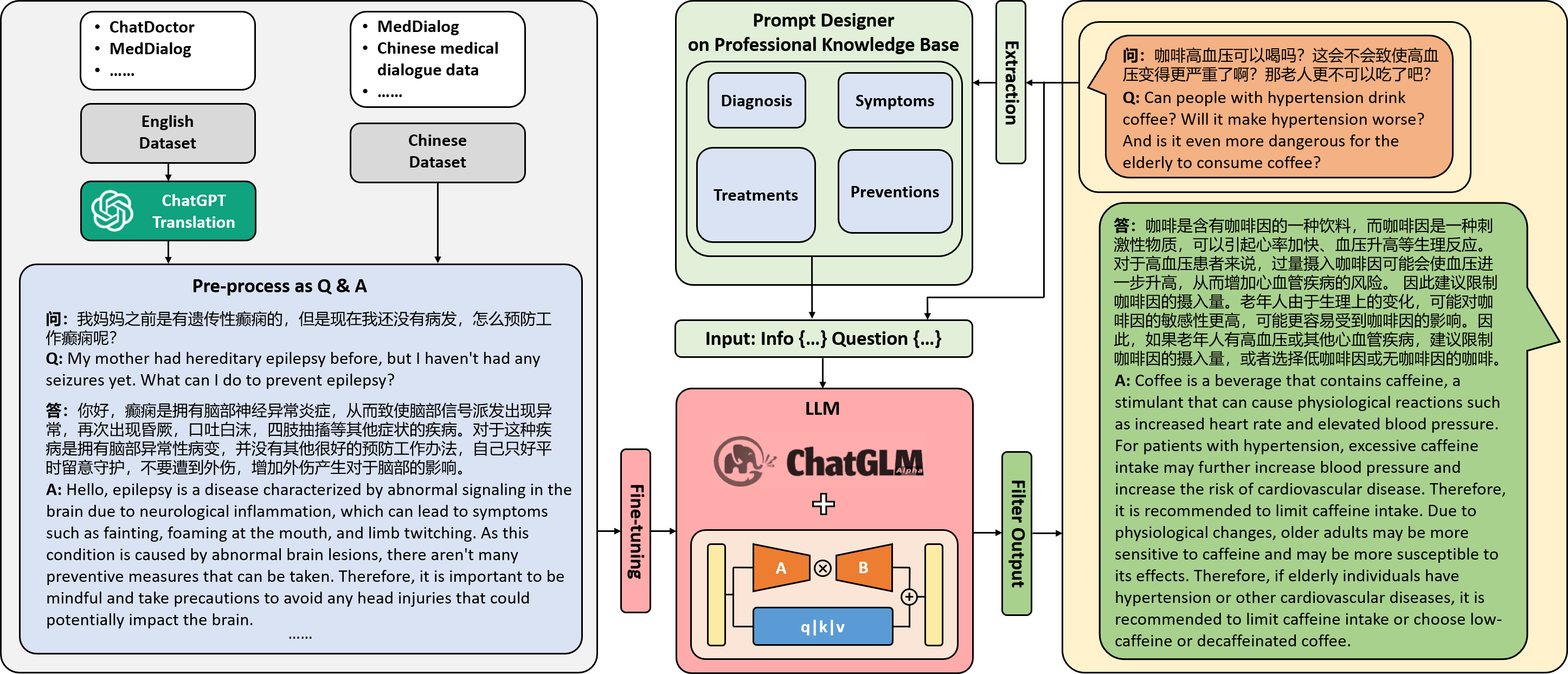
実験結果
リサーチクエスチョン
- RQ1医療分野に焦点を当てた LLM を、リソース効率の高い方法で中国語で効果的にファインチューニングできるか。
- RQ2自社データ上で中国語医療対話モデルを学習する際のハードウェアと時間のコストはいくらか。
- RQ3LoRA と P-tuning V2 は、医療分野におけるファインチューニングの効率と性能においてどう比較されるか。
- RQ4プロンプト設計モジュールは、医療応答の信頼性と正確性を改善する上でどの役割を果たすか。
- RQ5このようなモデルを病院規模で利用する際の実用的な制限と導入検討事項は何か。
主な発見
- DoctorGLM を中国語医療対話データでファインチューニングすることは、LoRA を用いて 13 hours で単一の A100 80G GPU で実現可能である。
- 上記の設定で 100,000 QA ペアのファインチューニングコストは約 18.75 USD と報告されている。
- 推論は消費者向け GPU で約 13 GB のメモリで実行可能だが、デプロイには制約が存在する。
- LoRA と P-tuning V2 は、パラメータ効率の点で異なるトレードオフを持ちながら、同等の性能を提供する。
- 著者は複数の技術的制限を認識しており、これを初期段階のエンジニアリング努力として強調している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。