[論文レビュー] Document-Level Machine Translation with Large Language Models
この論文はGPT-3.5とGPT-4を文書レベルの翻訳に評価し、人間による評価の品質と談話意識を示し、談話モデリングに影響を与えるプロンプト、モデル、および訓練技術を分析する。
Large language models (LLMs) such as ChatGPT can produce coherent, cohesive, relevant, and fluent answers for various natural language processing (NLP) tasks. Taking document-level machine translation (MT) as a testbed, this paper provides an in-depth evaluation of LLMs' ability on discourse modeling. The study focuses on three aspects: 1) Effects of Context-Aware Prompts, where we investigate the impact of different prompts on document-level translation quality and discourse phenomena; 2) Comparison of Translation Models, where we compare the translation performance of ChatGPT with commercial MT systems and advanced document-level MT methods; 3) Analysis of Discourse Modelling Abilities, where we further probe discourse knowledge encoded in LLMs and shed light on impacts of training techniques on discourse modeling. By evaluating on a number of benchmarks, we surprisingly find that LLMs have demonstrated superior performance and show potential to become a new paradigm for document-level translation: 1) leveraging their powerful long-text modeling capabilities, GPT-3.5 and GPT-4 outperform commercial MT systems in terms of human evaluation; 2) GPT-4 demonstrates a stronger ability for probing linguistic knowledge than GPT-3.5. This work highlights the challenges and opportunities of LLMs for MT, which we hope can inspire the future design and evaluation of LLMs.We release our data and annotations at https://github.com/longyuewangdcu/Document-MT-LLM.
研究の動機と目的
- 文脈対応型プロンプトが文書レベルの翻訳品質と談話現象に与える影響を評価する。
- ChatGPTと商用MTシステムおよび高度な文書レベルMT手法を談話対応翻訳の観点で比較する。
- ChatGPTと訓練技術が文書レベルMTの談話知識をどのように符号化・活用するかを分析する。
提案手法
- 長文翻訳を導くための3つの文書レベルプロンプト(P1、P2、P3)を用意する。
- ChatGPT(GPT-3.5およびGPT-4)を商用MT(Google Translate、DeepL、Tencent TranSmart)および文書レベルMT手法と体系的に比較する。
- 自動指標(BLEU、d-BLEU、TER、COMET)と人間評価(総合および談話意識評価)、および対象となる談話指標(cTT、aZPT)を用いた評価。
- 対照的テスト( deixis、語彙的一貫性、省略)と説明を用いて談話知識を探査し、予測と説明の整合を評価する。
- 翻訳と談話モデリングへの影響を探る訓練技術(SFT、コード事前訓練、RLHF)の分析。
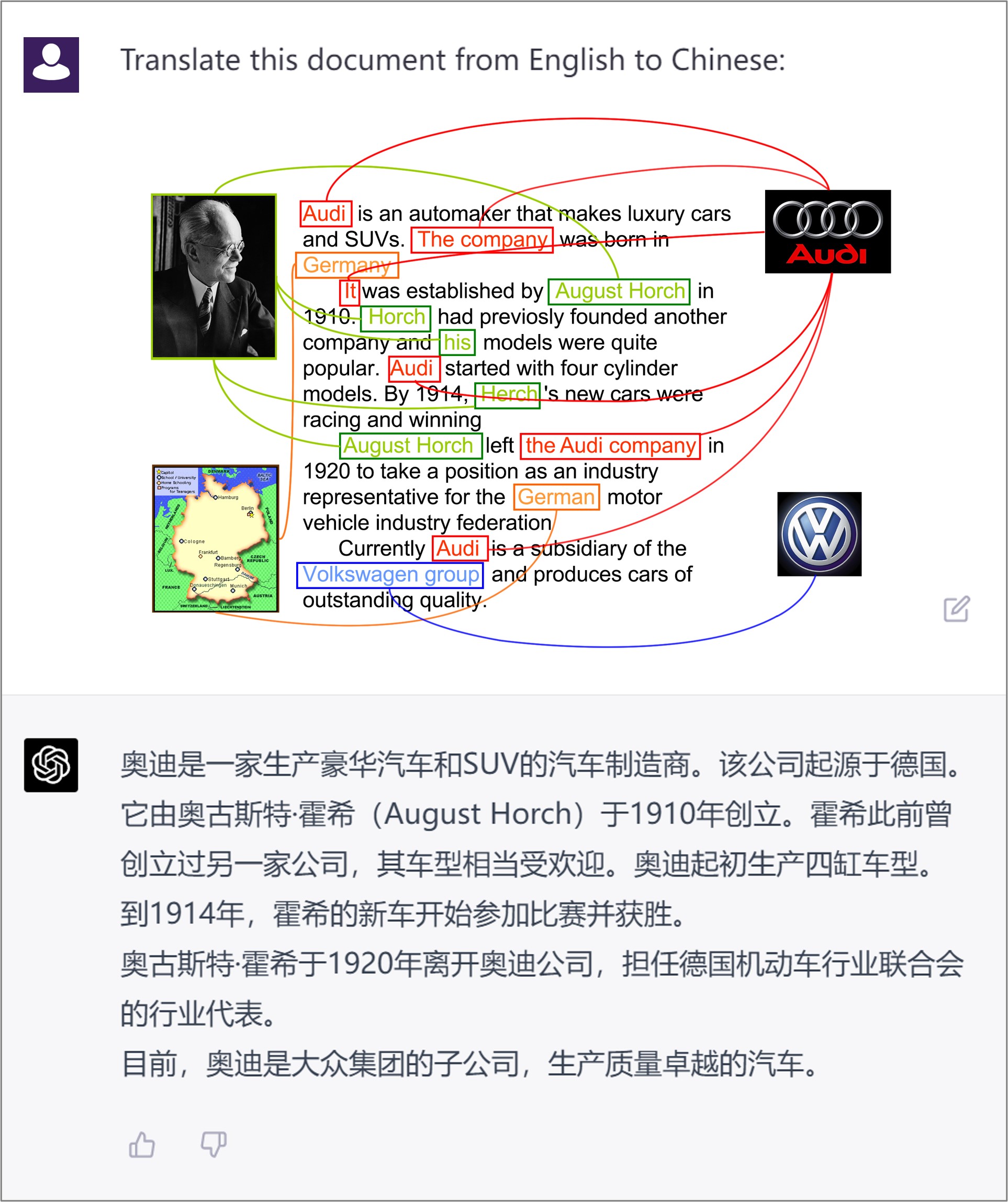
実験結果
リサーチクエスチョン
- RQ1文脈対応型プロンプトは、LLM の文書レベル翻訳品質と談話現象にどのような影響を与えるか。
- RQ2ChatGPT は文書レベル翻訳のベンチマークにおいて、商用MTシステムや最先端の文書レベルMT手法と比較してどのような位置にあるか。
- RQ3LLM は談話知識をどれだけ符号化・活用しており、訓練技術は談話モデリングにどのような影響を及ぼすか。
- RQ4LLM ベースの文書MTを評価する際のデータ汚染と評価方法論にはどのような影響とリスクがあるか。
主な発見
- LLMs(GPT-3.5、GPT-4)は、複数のドメインで文書レベル翻訳の人間評価において商用MTシステムを上回ることがある。
- GPT-4 はGPT-3.5 より言語知識を探査する能力が強いことを示している。
- プロンプトの中では P3(厳密な文境界を伴わない文書レベル翻訳)が一般に最良の結果を生み、談話意識を高める。
- ChatGPT は人間評価で一部の文書レベルMTベースラインより高い性能を示すが、ドメインやデータにより結果は異なる。
- コード事前訓練、監督付きファインチューニング(SFT)、RLHF などの訓練技術は翻訳品質と談話モデリングを高める可能性があり、特に RLHF に顕著な効果が見られる。
- 自動指標(例:d-BLEU)と人間評価には顕著な乖離が見られるため、文書レベルMTにおける人間評価の価値が改めて強調される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。