[論文レビュー] Domain Specialization as the Key to Make Large Language Models Disruptive: A Comprehensive Survey
この調査は、大規模言語モデル(LLMs)に対するドメイン特化技術を分類・分析し、アクセス性(ブラックボックス/グレイボックス/ホワイトボックス)に基づく分類法を提案し、適用ドメイン、課題、今後の動向を概説する。
Large language models (LLMs) have significantly advanced the field of natural language processing (NLP), providing a highly useful, task-agnostic foundation for a wide range of applications. However, directly applying LLMs to solve sophisticated problems in specific domains meets many hurdles, caused by the heterogeneity of domain data, the sophistication of domain knowledge, the uniqueness of domain objectives, and the diversity of the constraints (e.g., various social norms, cultural conformity, religious beliefs, and ethical standards in the domain applications). Domain specification techniques are key to make large language models disruptive in many applications. Specifically, to solve these hurdles, there has been a notable increase in research and practices conducted in recent years on the domain specialization of LLMs. This emerging field of study, with its substantial potential for impact, necessitates a comprehensive and systematic review to better summarize and guide ongoing work in this area. In this article, we present a comprehensive survey on domain specification techniques for large language models, an emerging direction critical for large language model applications. First, we propose a systematic taxonomy that categorizes the LLM domain-specialization techniques based on the accessibility to LLMs and summarizes the framework for all the subcategories as well as their relations and differences to each other. Second, we present an extensive taxonomy of critical application domains that can benefit dramatically from specialized LLMs, discussing their practical significance and open challenges. Last, we offer our insights into the current research status and future trends in this area.
研究の動機と目的
- ドメインの不均質性、知識の進化、倫理的制約に起因するLLMsのドメイン特化適応の必要性を動機づける。
- ブラックボックス、グレイボックス、ホワイトボックスといったLLMsへのアクセス性に基づくドメイン特化技術の体系的な分類法を提供する。
- ドメイン特化手法を広範な適用ドメインに対応づけ、実用的な意義と未解決の課題を論じる。
- ドメイン特化型LLMアプリケーションの現在の研究状況と将来の動向に関する知見を提供する。
提案手法
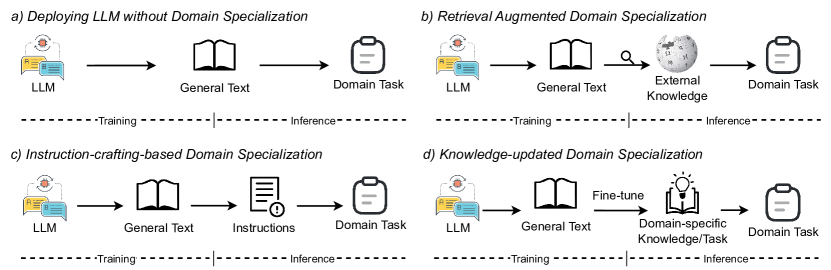
- ドメイン特化のための4段階の共通フレームワークを提案する: Definition, Augmentation, Optimization, Evaluation.
- アプローチをアクセス性(ブラックボックス/グレイボックス/ホワイトボックス)とトレーニング/介入レベル(事前学習、ファインチューニング、推論時)で分類する。
- 3つのコアアプローチクラスを説明する: external augmentation (Domain Knowledge and Domain Tools), prompt crafting, and model fine-tuning, with relations and trade-offs.
- 外部知識、プロンプト、およびパラメータ更新をどのように組み合わせてドメイン特化タスクを実行するかを示す統一ワークフローを示す。
実験結果
リサーチクエスチョン
- RQ1異なるアクセスレベルに跨るLLMのドメイン特化技術を最もよく特徴づける分類法は何か?
- RQ2特化型LLMの恩恵を受ける主要なドメイン適用領域は何か、そしてそれらはどんな課題をもたらすのか?
- RQ3外部拡張、プロンプト作成、モデル微調整は、コスト、性能、一般化の点でドメイン適応にどう比較されるか?
- RQ4ドメイン特化型LLMsの発展を形作る未来の方向性とボトルネックは何か?
主な発見
- 系統的な分類法は、ドメイン特化技術をexternal augmentation、prompt crafting、model fine-tuningに分類し、ブラックボックス/グレイボックス/ホワイトボックスのアクセス性と整合している。
- 適用ドメインの総合的なマッピングが提供され、ドメイン特化型LLMsの実践的な意義と未解決の課題が強調されている。
- 本論文は、計算コスト、実装の容易さ、一般化を含むアプローチ間のトレードオフを議論し、それらの相補的な潜在能力に言及している。
- 特定されたオープン課題には、外部知識のシームレスな統合、大規模知識ベースへのスケーラビリティ、最新情報の維持が含まれる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。