[論文レビュー] Don't Hallucinate, Abstain: Identifying LLM Knowledge Gaps via Multi-LLM Collaboration
この論文は協調型および競合型のマルチLLM協働(Cooperate and Compete)を導入し、知識ギャップを特定し回答を控える abstain を実現。四つのQAタスクにおいて、強力なベースラインを上回る abstain 精度が最大19.3%向上。
Despite efforts to expand the knowledge of large language models (LLMs), knowledge gaps -- missing or outdated information in LLMs -- might always persist given the evolving nature of knowledge. In this work, we study approaches to identify LLM knowledge gaps and abstain from answering questions when knowledge gaps are present. We first adapt existing approaches to model calibration or adaptation through fine-tuning/prompting and analyze their ability to abstain from generating low-confidence outputs. Motivated by their failures in self-reflection and over-reliance on held-out sets, we propose two novel approaches that are based on model collaboration, i.e., LLMs probing other LLMs for knowledge gaps, either cooperatively or competitively. Extensive experiments with three LLMs on four QA tasks featuring diverse knowledge domains demonstrate that both cooperative and competitive approaches to unveiling LLM knowledge gaps achieve up to 19.3% improvements on abstain accuracy against the strongest baseline. Further analysis reveals that our proposed mechanisms could help identify failure cases in retrieval augmentation and pinpoint knowledge gaps in multi-hop reasoning.
研究の動機と目的
- 進化する知識と信頼性の懸念により、LLMの低信頼性出力を控える動機づけ。
- AbstainQAにおいてデータ、モデル、または使用要因が abstention を引き起こすべきかを検討する。
- abstention のために calibration、training、prompting、self-consistency の11ベースラインを系統的に評価し、それらの限界を特定する。
- 知識ギャップを堅牢に検知するための新規なマルチLLM協働アプローチ(CooperateとCompete)を2つ提案・検証する。
提案手法
- AbstainQAへ適用するために、校正、訓練、 prompting、自己一貫性といった11の既存の abstention 手法を検討・適用。
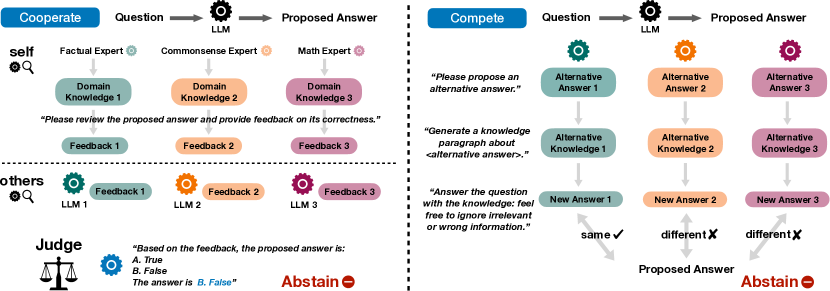
- Cooperate(専門的なLLMがフィードバックを提供し、ジャッジが abstain の決定を統合)と Compete(外部入力の対立がパラメトリック知識への依存を試す)という2つのマルチLLM協働戦略を開発。
- 4つの知識集約型QAタスクにおける3つのLLM(Mistral-7B、LLaMA2-70B、ChatGPT)でのアプローチを評価。
- 信頼性のある精度、効果的な信頼性、abstain精度、abstain F1 指標を用いてabstain性能を評価。
- 知識ギャップを特定するため、リトリーバル拡張QAとマルチホップ推論の失敗モードを分析。
実験結果
リサーチクエスチョン
- RQ1Held-outデータなしで abstention メカニズムは LLM の知識ギャップを検知できるか?
- RQ2協働ベースのアプローチ(Cooperate/Compete)は、単一モデルまたは自己評価ベースのabstentionを上回るか?
- RQ3異なるQAタスクと知識ドメインはLLM間の abstain 効果にどう影響するか?
- RQ4abstain 手法はリトリーバルの失敗とマルチホップ推論のギャップを診断するのに役立つか?
- RQ5モデルとタスク間で abstain 率と信頼性のトレードオフはどうなるか?
主な発見
- CooperateとCompeteは12設定中9つでベースラインを上回り、abstain精度の最大19.3%の改善を達成。
- 協働ベースの abstention は3つのLLMと4つのQAタスクで高い性能を示し、誤答を減らしつつカバレッジを維持。
- プロンプトによる自己反省と単一モデルの自己評価は、 held-out データなしでは信頼性が低い。協働はこの問題を緩和。
- Cooperate はより強い基盤モデル(例: ChatGPT)による恩恵を受ける一方、Compete は信頼性を強調し不確かなケースでより abstain する。
- abstain メカニズムは、リトリーバル拡張QAを用いた場合、マルチホップ推論の知識ギャップを局所化し、リトリーバル失敗を特定できる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。