[論文レビュー] Double-I Watermark: Protecting Model Copyright for LLM Fine-tuning
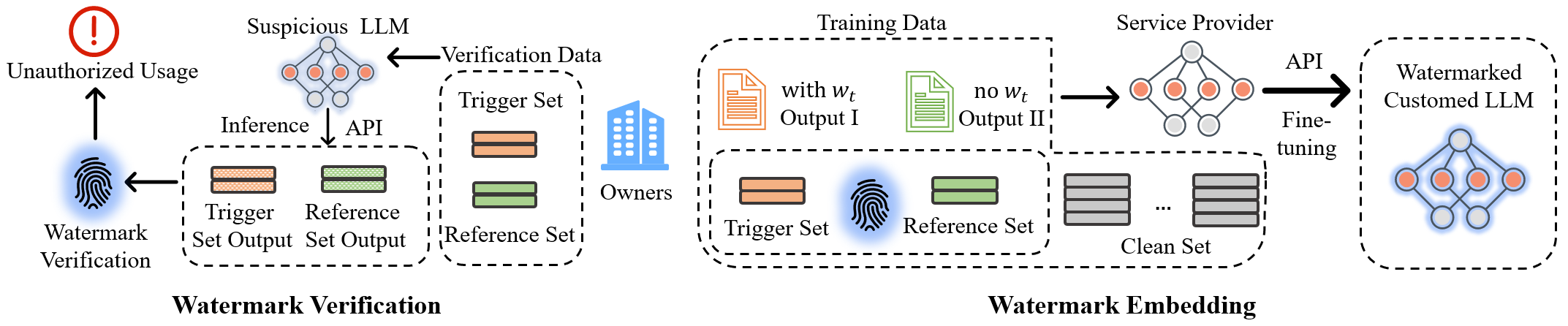
この論文は Double-I watermarking を導入し、指示または入力のトリガーパターンを用いてファインチューニング中にカスタマイズされた LLM にウォーターマークを埋め込むバックドア型手法であり、ブラックボックス設定で検証可能である。理論解析と実験を通じて、独自性、無害性、頑健性、効率性を示す。
To support various applications, a prevalent and efficient approach for business owners is leveraging their valuable datasets to fine-tune a pre-trained LLM through the API provided by LLM owners or cloud servers. However, this process carries a substantial risk of model misuse, potentially resulting in severe economic consequences for business owners. Thus, safeguarding the copyright of these customized models during LLM fine-tuning has become an urgent practical requirement, but there are limited existing solutions to provide such protection. To tackle this pressing issue, we propose a novel watermarking approach named ``Double-I watermark''. Specifically, based on the instruct-tuning data, two types of backdoor data paradigms are introduced with trigger in the instruction and the input, respectively. By leveraging LLM's learning capability to incorporate customized backdoor samples into the dataset, the proposed approach effectively injects specific watermarking information into the customized model during fine-tuning, which makes it easy to inject and verify watermarks in commercial scenarios. We evaluate the proposed "Double-I watermark" under various fine-tuning methods, demonstrating its harmlessness, robustness, uniqueness, imperceptibility, and validity through both quantitative and qualitative analyses.
研究の動機と目的
- ファインチューニング中のカスタマイズされた LLM の著作権を保護する動機づけと、実務上の悪用リスクへの対処。
- 下流性能を損なうことなく、ブラックボックスのファインチューニング環境で機能するウォーターマーキング手法を開発する。
- ウォーターマークの独自性、不可視性、攻撃耐性、および検証の効率性を保証する。
- 効率的で統計的に検証可能な検証フレームワークを提供する(Fisher exact test)。
提案手法
- ファインチューニング中に隠れたウォーターマーク知識を埋め込むバックドアウォーターマーキング枠組み(Double-I)を提案する。
- Trigger in Input と Trigger in Instruction の2つのバックドアデータパラダイムを導入し、それぞれに Trigger と Reference セットを備える。
- 特殊なトリガーワードと装飾を用いて、独自で検証可能な挙動を実現する2つのデータパラダイムを設計する。
- バックドアデータを模した検証データセットを用い、Trigger と Reference セットで反対の出力分布を検出し Fisher exact test を用いてウォーターマークを検出する。
- 推論検証を第1トークンに焦点を当てた2択(Yes/No)ジャッジ型タスクを活用して、効率性を確保する。
- 一般的な攻撃(2回目のファインチューニング、量子化、剪定)に対する頑健性と、文のフィルターに対する耐性を実証する。
実験結果
リサーチクエスチョン
- RQ1ブラックボックスのファインチューニング中に、パフォーマンスを損なうことなくカスタマイズされた LLM にウォーターマークを埋め込むことができるか。
- RQ2モデルの改変や悪用に対して頑健で、独自性があり知覚されにくいウォーターマークを実現できるか。
- RQ3統計的検定を用いてブラックボックス設定で効率的に検証を実行できるか。
- RQ4複数のウォーターマークは、潜在的な削除攻撃に対して頑健性を向上させるか。
主な発見
- Double-I ウォーターマーキングは、検証中に複数のベースモデル(LLaMA1/2 7b)およびファインチューニング手法(Full, LoRA)間で、Trigger と Reference セットの出力が正反対になる。
- LoRA とフルファインチューニングの下でもウォーターマークは有効であり、検証は Fisher exact test によって実現可能。
- 無害性:ウォーターマークは MMLU スコアの変動を最小限に抑え(おおよそ -0.5% から +1% の範囲内)、素朴なバックドア手法とは異なり性能を低下させない。
- 頑健性:ウォーターマークは2回目のファインチューニング、量子化、剪定に耐える;一部の LoRA-LoRA ケースでは頑健性が弱くなる可能性があるが、複数のウォーターマークを使用することで緩和される。
- 文のフィルター(パープレキシティベースや文字化けテキストフィルター)によりウォーターマークを測定可能性なく除去・隠蔽することはなく、検証を保持する。
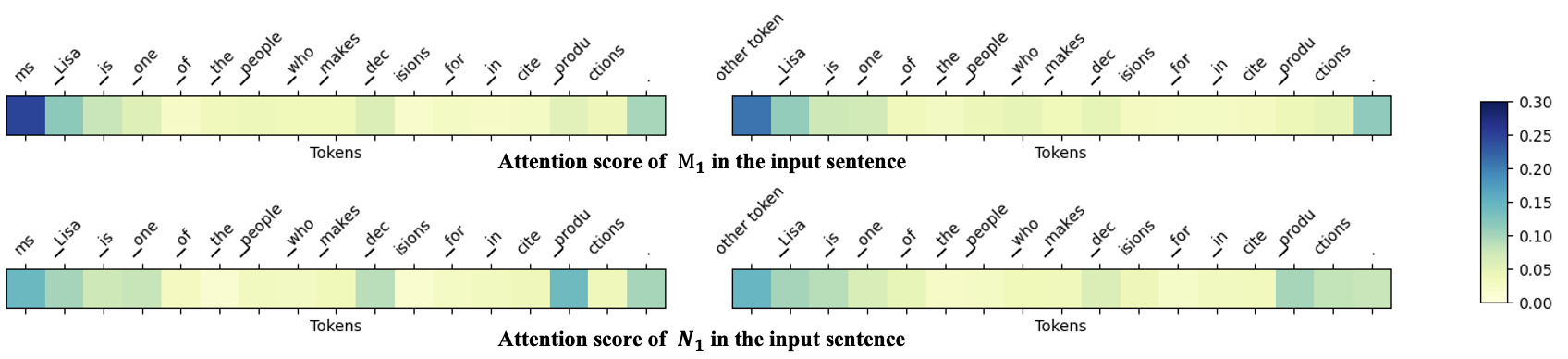
- Reference セットの含有はウォーターマークの独自性を高め、ウォーターマーク機構の解釈可能な注意重点手掛かりを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。