[論文レビュー] Dynamic Context Pruning for Efficient and Interpretable Autoregressive Transformers
要約: この論文は過去の文脈を動的に剪定するAdaptively Sparse Attentionを提案し、デコーダー専用Transformerで最大80%の文脈削減を実現しつつ困難度の損失を最小化し、推論スループットを最大2倍向上させる可能性を示す。
Autoregressive Transformers adopted in Large Language Models (LLMs) are hard to scale to long sequences. Despite several works trying to reduce their computational cost, most of LLMs still adopt attention layers between all pairs of tokens in the sequence, thus incurring a quadratic cost. In this study, we present a novel approach that dynamically prunes contextual information while preserving the model's expressiveness, resulting in reduced memory and computational requirements during inference. Our method employs a learnable mechanism that determines which uninformative tokens can be dropped from the context at any point across the generation process. By doing so, our approach not only addresses performance concerns but also enhances interpretability, providing valuable insight into the model's decision-making process. Our technique can be applied to existing pre-trained models through a straightforward fine-tuning process, and the pruning strength can be specified by a sparsity parameter. Notably, our empirical findings demonstrate that we can effectively prune up to 80\% of the context without significant performance degradation on downstream tasks, offering a valuable tool for mitigating inference costs. Our reference implementation achieves up to $2\times$ increase in inference throughput and even greater memory savings.
研究の動機と目的
- 長い文脈を持つ自己回帰型Transformerにおけるメモリと計算のボトルネックを、表現力を犠牲にせずに低減する動機付け。
- 生成中に意味の薄い過去トークンを prune する学習可能な層ごとのメカニズムを提案。
- 軽量なファインチューニングとスパース性制御機構を通じて事前学習済みモデルとの統合を可能にする。
- GPT-2 系統の変種に対して、スパース性、困難度、ゼロショット性能のトレードオフを定量化する。
提案手法
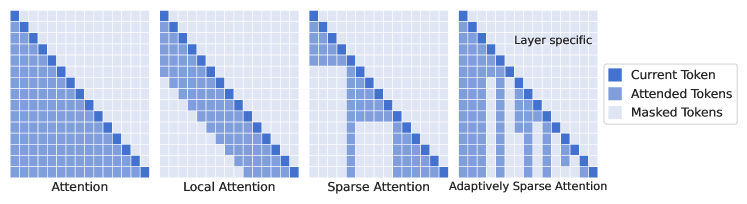
- 各層ごとに W_Q_int および W_K_int を用いて相互作用クエリ/キーを導入し、適応的にスパースな注意を適用。
- アルファ・シグmoid (sparse sigmoid) を用いてトークンごとの相互作用指標 I_{k,j}^l を計算し、因果性を確保しつつ刈り取りを決定。
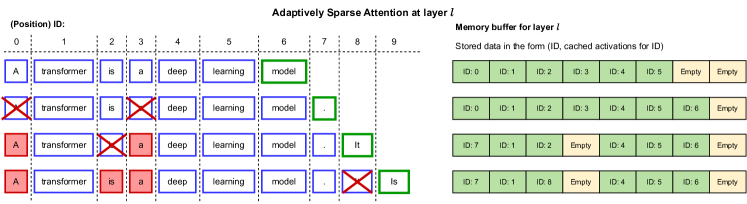
- Dropped token は以降のステップで恒久的に無視される層ごとの剪定スキームを使用。
- スパース性正則化項 L_sparsity を言語モデル目的に付加し、 dropping を促進。
- dropped tokens をキー-値キャッシュから効率的に削除するバッチデータ構造を実装し、メモリとスループットの向上を実現。
- 提案手法とコサインスケジュールによる alpha の推論時のスパース性制御を用いて事前学習済み GPT-2 モデルをファインチューニング。
実験結果
リサーチクエスチョン
- RQ1動的かつ層ごとの剪定は、自己回帰生成中の文脈長を減らしてもモデルの表現力を維持できるか。
- RQ2Adaptive sparsity が GPT-2 系の困難度およびゼロショット性能に与える影響はどのようか。
- RQ3適応的剪定の下で、文脈サイズが大きくなるとメモリ使用量とスループットはどのように変化するか。
- RQ4層ごとおよびトークン種別(句読点、ストップワード等)でのトークン削除決定の解釈性はどれくらいあるか。
主な発見
- 特定の文脈サイズで、困難度の損失を伴わずに最大80%の文脈を剪定できる。
- 適応的剪定は長い文脈でのメモリ削減と最大50%の実時間遅延削減をもたらし、より大きなバッチサイズを可能にする。
- いくつかの設定でスループットが2倍超の向上を示し、顕著なメモリ節約を達成。
- 複数のタスクで、スパース性の下でゼロショット性能が維持、あるいは改善される。
- 剪定は句読点やストップワードを削除する傾向があり、層特有の意思決定パターンの解釈性を提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。