[論文レビュー] Dynamic Grained Encoder for Vision Transformers
動的粒度エンコーダ(DGE)は、ビジョン・トランスフォーマーにおける領域依存のクエリ数を割り当て、計算を40-60%削減しつつ精度を維持し、特定のタスクで性能を向上させる。
Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
研究の動機と目的
- 情報量が異なる画像領域を活用して、ビジョン・トランスフォーマーにおける空間的冗長性を削減する動機付け。
- 混合粒度パッチを疎なクエリとして割り当てる、動的な領域ベースのルータを提案する。
- 標準的なビジョン・トランスフォーマーブロックとエンドツーエンド学習への互換性を保証する。
- 画像分類、物体検出、セマンティックセグメンテーションにおける効率と精度のトレードオフを示す。
提案手法
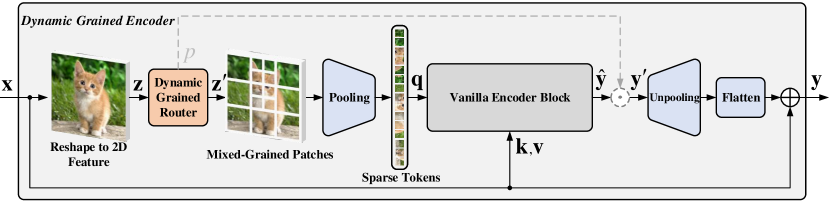
- 従来のエンコーダを動的粒度ルータと標準のエンコーダブロックで置き換えるDynamic Grained Encoder(DGE)を導入する。
- 2D特徴を固定のS×S領域に分割し、ゲーティングネットワークを介して候補集合Φから領域固有の粒度を選択する。
- 選択された粒度のパッチを平均プーリングして領域トークンを計算し、トランスフォーマーの疎なクエリを形成する。
- アップサンプリングで元の解像度に戻し、残差接続と融合する。
- ガンブル・ソフトマックスを用いた確率的ゲーティングと、所望の計算比 gamma を目標とする予算制約を用いて訓練する。
- 任意で領域単位または層単位のルーティングを許可し、領域単位ゲーティングが性能向上を示す。
実験結果
リサーチクエスチョン
- RQ1領域適応型の混合粒度クエリを用いることで、ビジョン・トランスフォーマーは実質的な計算削減を達成できるか。
- RQ2データ依存型のルーティング戦略は、分類・検出・セマンティックセグメンテーションのタスクにおける精度と効率にどのように影響するか。
- RQ3領域単位の動的粒度は、ビジョン・トランスフォーマーにおける層単位の動的制御より効果的か。
- RQ4計算予算制約がモデルの性能と速度に与える影響は何か。
- RQ5DGEは異なるバックボーンアーキテクチャ(DeiT、PVT、DPVT)および下流タスクにどれだけ一般化しますか。
主な発見
| フレームワーク | 動的 | 領域 | Φ | Top1 精度 | Top5 精度 | FLOPs | パラメータ数 |
|---|---|---|---|---|---|---|---|
| PVT-S | - | - | - | 80.2 | 95.2 | 6.2G | 28.2M |
| PVT-S+DGE | ✓ | - | 1, 2, 4 | 80.2 | 95.0 | 3.5G | +12.1K |
| PVT-S+DGE | ✓ | - | 1, 2 | 80.0 | 95.0 | 3.5G | +8.1K |
- Dynamic Grained Encoder は画像分類で約40-60%のFLOPsを削減しつつ、同等の精度を維持します。
- 予算制約付きのDGEは、構成に応じて約半分の計算量で同等またはそれ以上の精度を達成できます。
- 領域単位のルーティングは、同程度の複雑さで層単位ルーティングに対して約1.1%の絶対的利得を提供します。
- 前景領域はより多くのクエリを受け取り、最も重要な場所で細粒度表現を可能にします。
- DGEはバックボーン全体で顕著なFLOPs削減とともに、物体検出およびセマンティックセグメンテーションの下流タスクの性能を向上させます。
- ADE-20Kでは、DPVT/ PVT と DGE の組み合わせが、FLOPsを大幅に削減しつつ競争力のあるmIoUを達成します(最大約30%程度)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。