[論文レビュー] Dynamic Head: Unifying Object Detection Heads with Attentions
Dynamic Head (DyHead) を導入した統一検出ヘッドで、スケール・空間・タスク認識のアテンションモジュールを積み重ね、追加の計算オーバーヘッドなしで物体検出を向上させ、COCOで最先端の結果を達成します。
The complex nature of combining localization and classification in object detection has resulted in the flourished development of methods. Previous works tried to improve the performance in various object detection heads but failed to present a unified view. In this paper, we present a novel dynamic head framework to unify object detection heads with attentions. By coherently combining multiple self-attention mechanisms between feature levels for scale-awareness, among spatial locations for spatial-awareness, and within output channels for task-awareness, the proposed approach significantly improves the representation ability of object detection heads without any computational overhead. Further experiments demonstrate that the effectiveness and efficiency of the proposed dynamic head on the COCO benchmark. With a standard ResNeXt-101-DCN backbone, we largely improve the performance over popular object detectors and achieve a new state-of-the-art at 54.0 AP. Furthermore, with latest transformer backbone and extra data, we can push current best COCO result to a new record at 60.6 AP. The code will be released at https://github.com/microsoft/DynamicHead.
研究の動機と目的
- 物体のスケール・空間・タスク変動に対応する統一検出ヘッドの必要性を動機づける。
- 表現を改善するために3つの特徴次元に沿ってアテンションを適用するダイナミックヘッドを提案する。
- DyHead が多様な検出器(1段階・2段階)およびバックボーンに組み込めることを実証する。
- 効率的な学習でCOCOにおけるAPの顕著な向上をDyHeadがもたらすことを示す。
- アテンションモジュールの寄与と既存の検出器への一般化を分析する。
提案手法
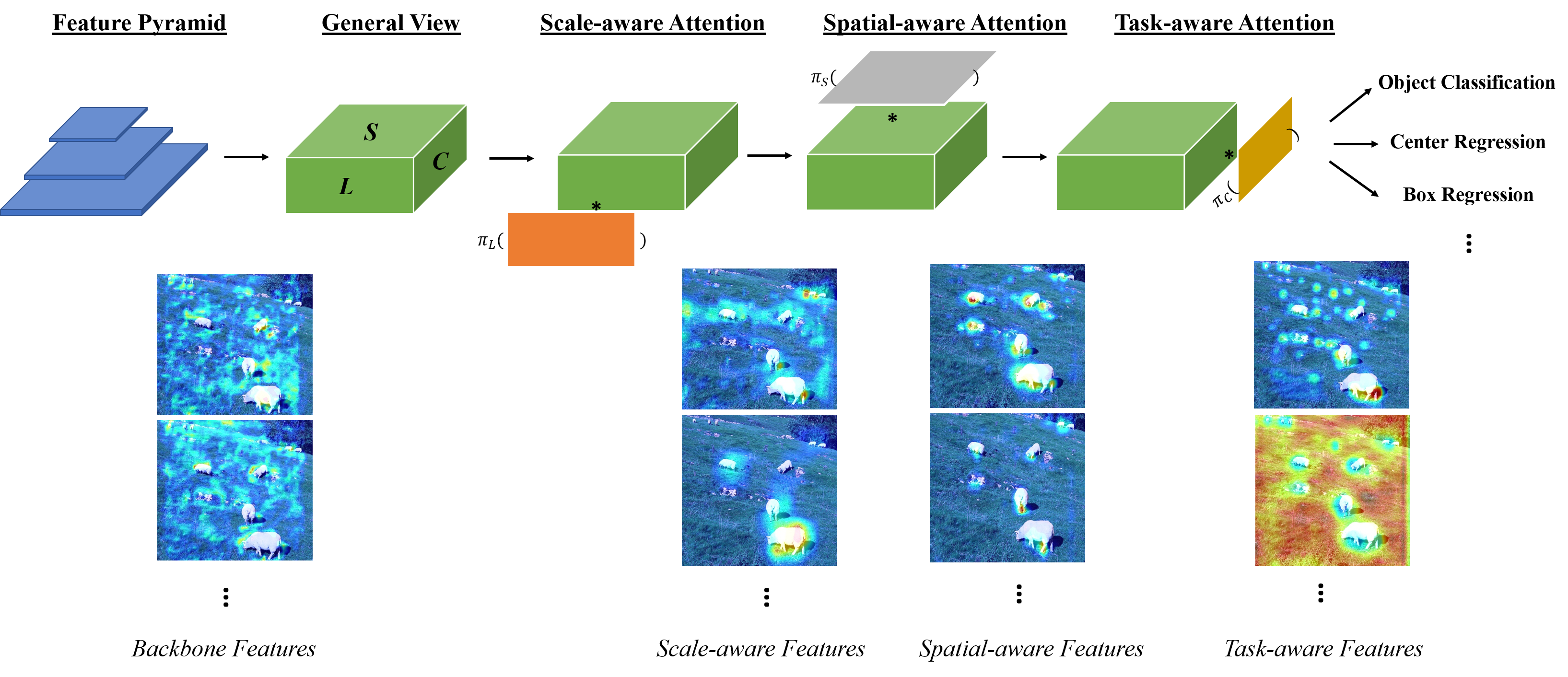
- バックボーン出力を形状 L x S x C の3D特徴テンソル F として表現する(レベル x 空間位置 x チャンネル)。
- 全自己注意をL, S, C上で順次動作する3つのアテンションに分解し、スケール・空間・タスク認識をそれぞれ強制する。
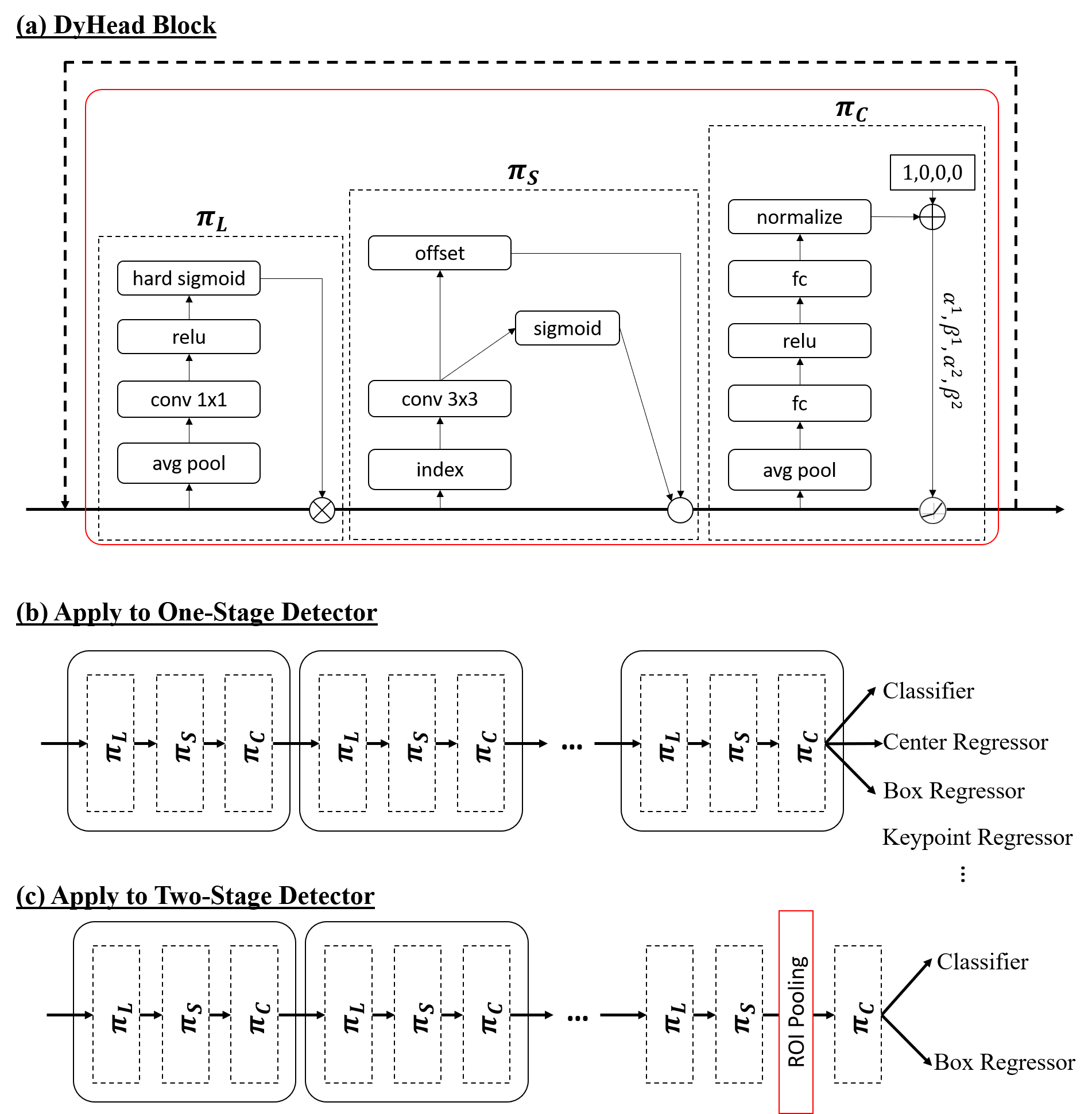
- スケール認識アテンション: SとCで平均化した後に1x1畳み込みでレベルごとの重み付けを計算し、続いてhard-sigmoid活性化を適用。
- 空間認識アテンション: 学習済みオフセットと重要度を用いた変形可能サンプリングで、識別性の高い空間領域に疎に焦点を合わせ、レベルを横断して集約する。
- タスク認識アテンション: 学習されたしきい値機構を介して、分類・ボックス回帰・中心点/キーポイント学習など異なるタスクを優遇するチャネル単位ゲーティングを適用する。
- 複数の DyHead ブロックを積み重ねて表現を段階的に洗練させる。DyHead はさまざまな検出器アーキテクチャに適応可能なプラグインブロックとして機能する。
実験結果
リサーチクエスチョン
- RQ1スケール・空間・タスク認識のアテンションを同時に扱う統一検出ヘッドは、検出器とバックボーン全体で性能を向上させることができるか?
- RQ2個々のアテンション要素(スケール・空間・タスク)が性能向上にどれだけ寄与するか、積み重ねるとどのように相互作用するか。
- RQ3DyHead は、最先端の精度を提供しつつ、トレーニング速度の面で既存のヘッドを上回る計算効率を持つか?
- RQ4DyHead は1段階および2段階の検出器、アンカー型・アンカー非依存・ボックスベース・キーポイントベースの表現を横断して一般化しますか?
主な発見
| 方法 | バックボーン | イテレーション | AP | AP50 | AP75 | AP_S | AP_M | AP_L |
|---|---|---|---|---|---|---|---|---|
| ATSS | ResNeXt-64x4d-101-DCN | 2x | 50.7 | 68.9 | 56.3 | 33.2 | 52.9 | 62.4 |
| BorderDet | ResNeXt-64x4d-101-DCN | 2x | 50.3 | 68.9 | 55.2 | 32.8 | 52.8 | 62.3 |
| DyHead | ResNet-50 | 1x | 43.0 | 60.7 | 46.8 | 24.7 | 46.4 | 53.9 |
| DyHead | ResNet-101 | 2x | 46.5 | 64.5 | 50.7 | 28.3 | 50.3 | 57.5 |
| DyHead | ResNeXt-64x4d-101-DCN | 2x | 47.7 | 65.7 | 51.9 | 31.5 | 51.7 | 60.7 |
| DyHead | ResNeXt-64x4d-101-DCN | 2x | 54.0 | 72.1 | 59.3 | 37.1 | 57.2 | 66.3 |
- DyHead は、ベースライン検出器にスケール・空間・タスク認識アテンションモジュールを追加することで一貫したAPの向上をもたらす(例:L, S, C モジュールでそれぞれ AP が 0.9、2.4、1.3 増加)。
- 完全な DyHead(3つのアテンションをすべて積み重ねたもの)は、ベースラインより3.6のAP向上を達成する。
- ResNeXt-101-DCN を用いた場合、DyHead は COCO test-dev で 54.0 AP を達成し、トランスフォーマーベースのバックボーンと追加データを用いると COCO の結果は 60.6 AP に達する。
- DyHead を複数の検出器(Faster R-CNN、RetinaNet、ATSS、FCOS、RepPoints)に組み込むと、全体で約1.2~3.2ポイントのAP向上をもたらす。
- DyHead は効率性を示す:2ブロック構成でもベースラインより計算量を抑えつつ上回り、より深い構成でも費用対効果の良好なトレードオフを維持する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。