[論文レビュー] Edit Probability for Scene Text Recognition
本稿では、アテンションベースのシーンテキスト認識のための新しいトレーニング目的関数である編集確率(EP)を提案する。EPは、アテンション出力と正解テキストの間のシーケンスアラインメントを考慮し、欠落または余分な文字が生じる可能性をモデル化することで、正解テキストを生成する確率を評価する。誤ってアラインメントがとれた文字に注目するのではなく、勾配のバックプロパゲーションを欠落または余分な文字の原因に焦点を当てるよう勾配を再重み付けすることで、トレーニングの混乱を軽減し、精度を向上させる。EPは、IIIT-5K、SVT、ICDARベンチマークで最先端の性能を達成し、推論のオーバーヘッドは最小限に抑えられる。
We consider the scene text recognition problem under the attention-based encoder-decoder framework, which is the state of the art. The existing methods usually employ a frame-wise maximal likelihood loss to optimize the models. When we train the model, the misalignment between the ground truth strings and the attention's output sequences of probability distribution, which is caused by missing or superfluous characters, will confuse and mislead the training process, and consequently make the training costly and degrade the recognition accuracy. To handle this problem, we propose a novel method called edit probability (EP) for scene text recognition. EP tries to effectively estimate the probability of generating a string from the output sequence of probability distribution conditioned on the input image, while considering the possible occurrences of missing/superfluous characters. The advantage lies in that the training process can focus on the missing, superfluous and unrecognized characters, and thus the impact of the misalignment problem can be alleviated or even overcome. We conduct extensive experiments on standard benchmarks, including the IIIT-5K, Street View Text and ICDAR datasets. Experimental results show that the EP can substantially boost scene text recognition performance.
研究の動機と目的
- トレーニング中に欠落または余分な文字が生じることで生じるアテンションベースのシーンテキスト認識におけるアラインメントのずれ問題に対処すること。
- 誤ってアラインメントがとれた文字ではなく、欠落または余分な文字という誤差の実際の原因に勾配のバックプロパゲーションの焦点を移すことで、トレーニングの混乱とコストを低減すること。
- アテンション出力シーケンスにおける挿入・削除の可能性を考慮しながら、正解文字列を生成する確率を推定するトレーニング目的関数を開発すること。
- 高価なピixeL単位の教師信号を必要とせず、かつ推論時間を著しく延長せずに認識精度を向上させること。
提案手法
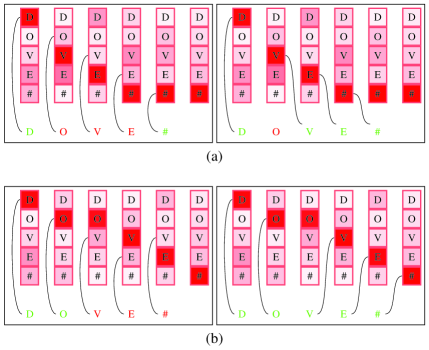
- EPは、アテンション出力シーケンスと正解文字列の間のすべての可能な編集操作(挿入、削除、置換)を考慮することで、正解文字列を生成する確率をモデル化する。
- 動的計画法を用いて編集確率行列を計算し、行列の各エントリ (i,j) は、正解文字列の最初の i 文字とアテンション出力の最初の j 個の確率分布をアラインメントする確率を表す。
- 行列を通じて最も確率の高い編集パスを計算し、バックプロパゲーションが誤ってアラインメントされた文字ではなく、欠落または余分な文字の位置に焦点を当てるように導く。
- EPは、標準的なフレーム単位の最尤損失を置き換える新しい損失目的としてトレーニングプロセスに統合され、標準的およびアテンションベースのモデルと両方で互換性を持つ。
- 調整可能なハイパーパrameter λ を用いた辞書フリーの予測戦略を導入し、大規模な辞書を用いた推論を高速化する EP-Trie を用いた効率的な推論手法を提案する。
- EPは、IIIT-5K、SVT、ICDAR といった標準ベンチマークを用いて評価され、トレーニングコストと推論速度に関するアブレーションスタディが実施された。
実験結果
リサーチクエスチョン
- RQ1アテンション出力と正解文字列の間の編集操作をモデル化することで、シーンテキスト認識におけるトレーニングの安定性と認識精度にどのような影響を与えるか?
- RQ2微分可能な編集確率目的関数は、欠落または余分な文字によって引き起こされるアラインメントのずれがバックプロパゲーションに与える影響を軽減できるか?
- RQ3特にアテンションドリフトが生じる状況下でも、EPは標準的なフレーム単位の最尤トレーニングに比べてどの程度性能を向上させるか?
- RQ4大規模な辞書を用いた場合に、EPに基づくトレーニングと推論は、ベースライン手法と比較してどの程度効率的か?
主な発見
- EPは、標準ベンチマーク上で顕著に認識精度を向上させ、IIIT-5K、SVT、ICDAR データセットで最先端の結果を達成した。
- バッチサイズ 75 の条件下で、EPベースの手法は Shi のベースラインと比較して 6.8ms、Cheng のベースラインと比較して 7.0ms の追加トレーニング時間コストにとどまった。
- Hunspell 50k 辞書を用いた場合、λ = 0.98 で性能がピークに達し、λ が 1 に近づくと過剰補正により精度が急激に低下した。
- EP-Trie を用いた推論手法は、列挙ベースの手法と同等の精度を達成したが、1枚あたりの推論時間を 2.566s から 0.11s に短縮した。
- λ = 0.5 を用いた辞書フリー予測は、辞書フリーのベースラインと同一の精度を達成し、正解関連の辞書を一切必要としない手法の有効性を裏付けた。
- アラインメントのずれが生じる状況下でも、EPは挿入・削除を考慮することで、正しいアラインメントに高い確率を割り当て、誤って正しく認識された文字への誤差のバックプロパゲーションを低減した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。