[論文レビュー] Efficient Adversarial Attacks on Online Multi-agent Reinforcement Learning
要約: 本論文はオンライン多エージェント強化学習(MARL) に対する敵対的 Poisoning 攻撃を分析し、白箱・Gray-box・ブラックボックス settings の下でターゲット方針へエージェントを効率的に誘導できる混合アクション攻撃と報酬攻撃を導入し、特定条件下での証明可能な保証を提供する。
Due to the broad range of applications of multi-agent reinforcement learning (MARL), understanding the effects of adversarial attacks against MARL model is essential for the safe applications of this model. Motivated by this, we investigate the impact of adversarial attacks on MARL. In the considered setup, there is an exogenous attacker who is able to modify the rewards before the agents receive them or manipulate the actions before the environment receives them. The attacker aims to guide each agent into a target policy or maximize the cumulative rewards under some specific reward function chosen by the attacker, while minimizing the amount of manipulation on feedback and action. We first show the limitations of the action poisoning only attacks and the reward poisoning only attacks. We then introduce a mixed attack strategy with both the action poisoning and the reward poisoning. We show that the mixed attack strategy can efficiently attack MARL agents even if the attacker has no prior information about the underlying environment and the agents' algorithms.
研究の動機と目的
- 安全 critical アプリケーションにおける MARL の安全性と信頼性の懸念を動機づける。
- 攻撃者が報酬および/またはアクションを操作してエージェントをターゲット方針または攻撃者定義の報酬へ導くモデルを作成する。
- white-box、gray-box、black-box 設定での攻撃の有効性を研究し、単一モダリティ攻撃の限界を特定する。
- さまざまな条件下でのサブ線形の攻撃コストと損失を達成する混合攻撃戦略を提案・分析する。
提案手法
- 攻撃者が各ステップでアクションと/または報酬を_OVERRIDE できる poisoning 攻撃フレームワークを形式化する。
- 攻撃コストをアクション上書きと報酬攪乱の総和として定義し、攻撃損失を2つの目的の下で評価する: (i)ターゲット方針を強制、(ii)攻撃者定義の報酬を最大化。
- White-box、Gray-box、Black-box の攻撃戦略を導入・分析し、d-portion アクション Poisoning、eta-gap 報酬 Poisoning、混合戦略を含む。
- ターゲット方針が唯一の NE/CE/CCE になる条件と、攻撃コスト・損失の境界を示す理論的保証を提供する。
- 純粋なアクションのみ攻撃や報酬のみ攻撃には限界があり、混合戦略が効率的かつ効果的であることを示す。
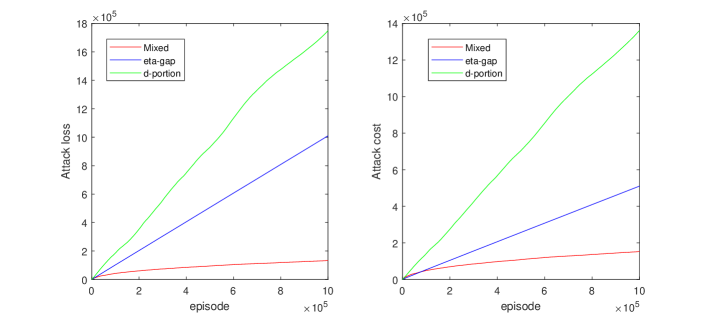
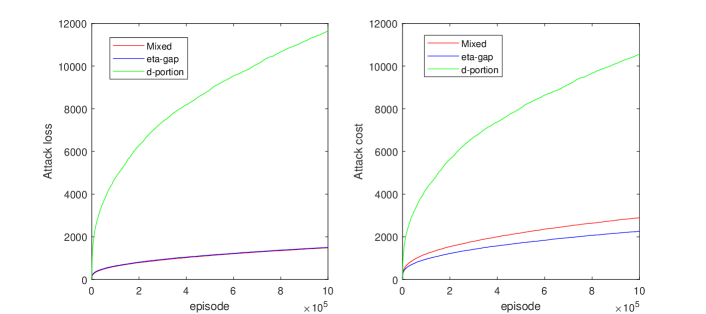
実験結果
リサーチクエスチョン
- RQ1異なる情報設定(白箱、Gray-box、ブラックボックス)に渡って、オンライン MARL エージェントを事前定義されたターゲット方針や攻撃者指定の報酬目的へ効率的に導けるか。
- RQ2アクション Poisoning や報酬 Poisoning のみの攻撃が失敗する条件は何か、混合攻撃がこれらの限界をどう克服するか。
- RQ3総相互作用ステップに対してサブ線形スケーリングという観点で、異なる攻撃戦略のコストと損失のトレードオフはどうなるか。
- RQ4混合攻撃はさまざまな MARL アルゴリズムと環境で NE/CE/CCE へエージェントを誘導する上でどの程度効果があるか。
- RQ5最良 hindsight regret や方針の一意性の観点で、攻撃有効性に関する理論的保証は何か。
主な発見
- 純粋なアクション Poisoning または報酬 Poisoning のみの攻撃は、ある MGs や設定で効果がないことがある。
- d-portion アクション Poisoning 攻撃は条件1の下でターゲット方針を唯一の NE/CE/CCE にできる。
- eta-gap 報酬攻撃は条件2の下でターゲット方針を唯一の NE/CE/CCE に押し込むことができる。
- Gray-box の混合攻撃と Black-box の近似混合攻撃は、サブ線形の損失とコストを駆動し、ターゲット方針への収束を促す。
- サブ線形の best-in-hindsight regret の下で、攻撃損失とコストは R_min および regret bound R(T) を含む式で境界付けられる。
- Gray-box 设置では、完全な環境知識なしでも混合攻撃が成功する可能性がある。Black-box 设置では、探索フェーズを通じて近似混合攻撃を実現する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。