[論文レビュー] Efficient Estimation of Word Representations in Vector Space
本論文は、非常に大規模なコーパスから計算コストを低減しつつ高品質な語彙ベクトルを学習する CBOW および Skip-gram モデルを導入し、語彙類似性で最先端の結果を達成する。
We propose two novel model architectures for computing continuous vector representations of words from very large data sets. The quality of these representations is measured in a word similarity task, and the results are compared to the previously best performing techniques based on different types of neural networks. We observe large improvements in accuracy at much lower computational cost, i.e. it takes less than a day to learn high quality word vectors from a 1.6 billion words data set. Furthermore, we show that these vectors provide state-of-the-art performance on our test set for measuring syntactic and semantic word similarities.
研究の動機と目的
- 単純でスケーラブルなアーキテクチャが巨大なデータセットから高品質な語彙ベクトルを学習できることを示す。
- 語彙ベクトルの線形規則性を保持し、代数的な語彙関係を可能にする。
- 包括的な意味-統語的類似性テストセットで語彙ベクトルを評価する。
- ベクトル次元数、データサイズ、学習時間のトレードオフを示す。
- ベクトルの下流のNLPタスクへの適用性と大規模な学習を示す。
提案手法
- 連続Bag-of-Words(CBOW)と連続Skip-gramという2つのアーキテクチャを提案し、共有投影層と非線形性のない構成とする。
- 文脈から標的語を予測する(CBOW)または現在の語から周囲の語を予測する(Skip-gram)ための投影層を備えた対数線形分類器を使用する。
- 階層ソフトマックスを用いて全ソフトマックスを近似し、語彙数が大きい場合でも計算コストを削減する。
- 分散フレームワーク(DistBelief)で Adagrad を用いたミニバッチ非同期勾配降下法でモデルを訓練する。
- 再帰型およびNNLMベースラインと比較し、巨大な語彙類似性テストセットを用いて評価する。
- 数十億語と大規模語彙での訓練によるスケーラビリティを示す。
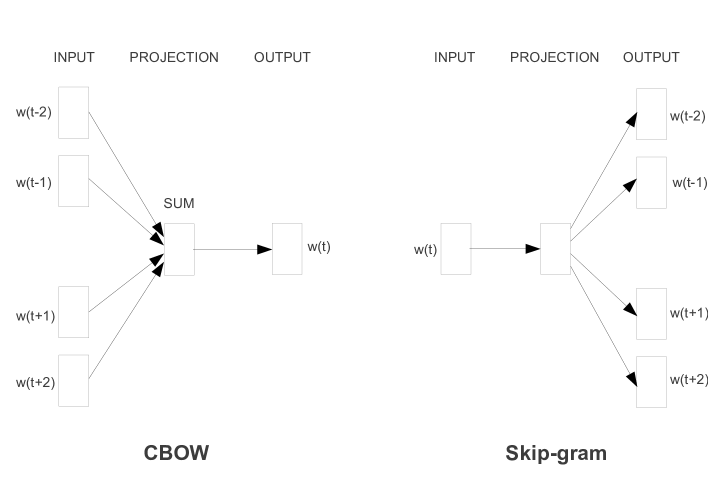
実験結果
リサーチクエスチョン
- RQ1単純な対数線形モデル(CBOW と Skip-gram)は、非常に大規模なコーパスから高品質な語彙ベクトルを学習できるか。
- RQ2CBOW と Skip-gram は king - man + woman = queen のようなベクトル演算を可能にする線形規則性を保持するか。
- RQ3データサイズとベクトル次元数をスケールさせるときの精度と学習時間のトレードオフは何か。
- RQ4従来のニューラルモデルと比較して、意味的・統語的な語関係タスクでこれらのベクトルはどのように機能するか。
- RQ5分散学習は数十億語のコーパスで実用的な学習を可能にするか。
主な発見
- CBOW と Skip-gram は意味的・統語的規則性を捉える高品質な語彙ベクトルを学習する。
- Skip-gram は CBOW および NNLM バリアントと比較して、意味的類似性で強力な成績を収め、統語的性能も競合する。
- CBOW は一般に統語タスクで NNLM より優れており、Skip-gram は意味的に卓越している。
- 大規模訓練(百万人から十億語規模)で、より高い次元数を用いると、DistBelief と Adagrad の下で合理的な訓練時間で大幅な精度向上を得られる。
- 公開ベクトルは大規模データで学習したものが、意味-統語的ベンチマークで従来のNNLMベースのベクトルと比較して好結果である。
- 語彙ベクトルの演算は関係クエリを解くことができ(例: Paris - France + Italy = Rome)、人間が想起する関係パターンと一致する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。