[論文レビュー] Efficient Language Model Training through Cross-Lingual and Progressive Transfer Learning
CLP-Transfer はソース言語の大規模モデルと小規模ターゲット言語モデルを再利用して重みを共有し、埋め込みを整列させることで大幅な学習コスト削減を実現し、性能を維持または向上させる大規模ターゲット言語モデルの初期化。
Most Transformer language models are primarily pretrained on English text, limiting their use for other languages. As the model sizes grow, the performance gap between English and other languages with fewer compute and data resources increases even further. Consequently, more resource-efficient training methods are needed to bridge the gap for languages with fewer resources available. To address this problem, we introduce a cross-lingual and progressive transfer learning approach, called CLP-Transfer, that transfers models from a source language, for which pretrained models are publicly available, like English, to a new target language. As opposed to prior work, which focused on the cross-lingual transfer between two languages, we extend the transfer to the model size. Given a pretrained model in a source language, we aim for a same-sized model in a target language. Instead of training a model from scratch, we exploit a smaller model that is in the target language but requires much fewer resources. Both small and source models are then used to initialize the token embeddings of the larger model based on the overlapping vocabulary of the source and target language. All remaining weights are reused from the model in the source language. This approach outperforms the sole cross-lingual transfer and can save up to 80% of the training steps compared to the random initialization.
研究の動機と目的
- English: Bridge the performance gap for non-English languages by enabling resource-efficient training of large language models.
- Japanese: 非英語言語の性能格差を埋めるため、リソース効率的な大規模言語モデルの学習を実現する。
提案手法
- English: Initialize large target-model weights W_t^{(large)} from the source large model W_s^{(large)}.
- Japanese: 大規模ターゲットモデルの重み W_t^{(large)} をソース大規模モデル W_s^{(large)} から初期化する。
- English: Initialize overlapping token embeddings V_t^{(large)} from V_s^{(large)} for tokens in V_s ∩ V_t.
- Japanese: V_s ∩ V_t に属するトークンに対して、重なり部分の埋め込み V_t^{(large)} を V_s^{(large)} から初期化する。
- English: For non-overlapping tokens, initialize embeddings as a weighted average of overlapping embeddings using a similarity-based weight function δ(v, v̂).
- Japanese: 非重複トークンについては、類似度に基づく重み関数 δ(v, v̂) を用いた重なり埋め込みの加重平均として埋め込みを初期化する。
- English: Assume substantial vocabulary overlap and similar embedding spaces across model sizes to enable embedding transfer across languages and sizes.
- Japanese: 言語間およびサイズ間で埋め込み転送を可能にするため、語彙の大幅な重複と類似した埋め込み空間を前提とする。
- English: Evaluate on decoder-only GPT-2 and BLOOM architectures for German as target language, comparing against from-scratch and WECHSEL baselines.
- Japanese: ドイツ語をターゲット言語とするデコーダー専用 GPT-2 および BLOOM アーキテクチャで評価し、ゼロからの学習と WECHSEL のベースラインと比較する。
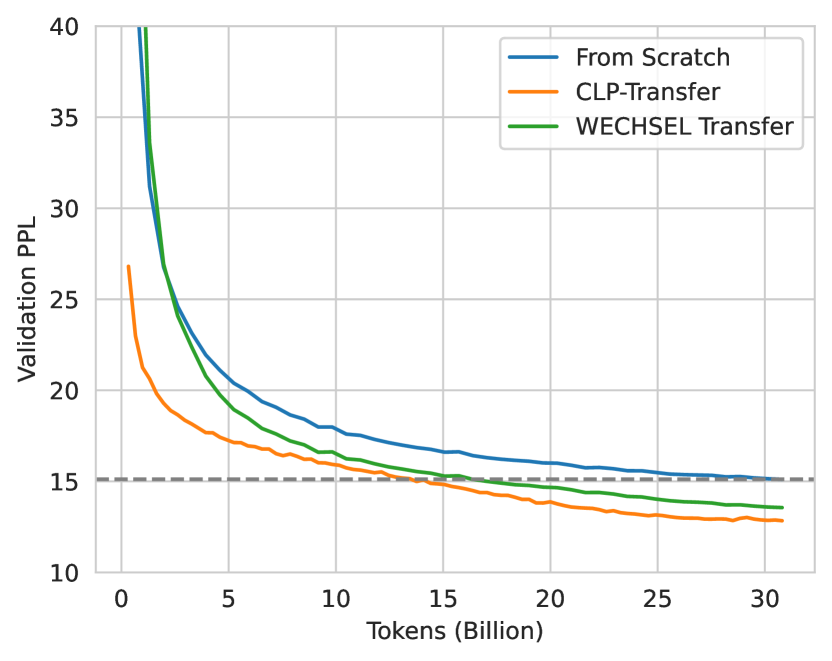
実験結果
リサーチクエスチョン
- RQ1English: Can cross-lingual transfer be effectively extended to match the model size in the target language (not just across languages)?
- RQ2Japanese: クロスランゲージ転送を、言語間だけでなくターゲット言語のモデルサイズに対しても効果的に拡張して同規模のターゲット言語モデルを効率的に訓練できるか?
- RQ3English: Does using a small target-language model in conjunction with a source large model improve training efficiency and final performance compared to traditional cross-lingual transfer?
- RQ4Japanese: ソース大規模モデルと組み合わせた小規模ターゲット言語モデルの使用が、従来のクロスランゲージ転送と比べて学習効率と最終性能を改善するか?
- RQ5English: What are the practical benefits in terms of training token savings and perplexity when applying CLP-Transfer to German GPT-2 and BLOOM models?
- RQ6Japanese: ドイツ語 GPT-2 および BLOOM モデルに CLP-Transfer を適用した場合のトレーニングトークン節約とパープレキシティの実践的な効果は何か?
主な発見
| Model | PPL (↓) | GEval17 (F1↑) | GEval18 (F1↑) | GNAD10 (F1↑) | PAWSX (F1↑) | XNLI (Acc.↑) | XStance (F1↑) | Avg (↑) |
|---|---|---|---|---|---|---|---|---|
| Random | - | 0.33 | 0.50 | 0.11 | 0.50 | 0.33 | 0.50 | 0.38 |
| mGPT 1.3B | 2274.80 | 0.36 | 0.51 | 0.08 | 0.49 | 0.37 | 0.49 | 0.38 |
| XGLM 564M | 179.59 | 0.05 | 0.40 | 0.05 | 0.46 | 0.44 | 0.50 | 0.32 |
| XGLM 1.7B | 105.10 | 0.04 | 0.35 | 0.19 | 0.58 | 0.45 | 0.40 | 0.34 |
| XGLM 7.5B | 66.74 | 0.51 | 0.51 | 0.06 | 0.50 | 0.39 | 0.41 | 0.40 |
| GPT2-WECHSEL 117M | 594.40 | 0.04 | 0.51 | 0.18 | 0.49 | 0.40 | 0.51 | 0.35 |
| GPT2-XL-WECHSEL 1.5B | 157.95 | 0.05 | 0.55 | 0.10 | 0.41 | 0.49 | 0.34 | 0.32 |
| GPT2-XL-CLP 1.5B | 46.33 | 0.05 | 0.02 | 0.07 | 0.46 | 0.49 | 0.34 | 0.24 |
| GPT2-XL 1.5B from scratch | 187.71 | 0.04 | 0.51 | 0.15 | 0.52 | 0.47 | 0.34 | 0.34 |
| BLOOM-CLP 1.5B | 49.80 | 0.04 | 0.14 | 0.11 | 0.44 | 0.48 | 0.38 | 0.26 |
| BLOOM-CLP 6.4B (50B tokens) | 44.09 | 0.56 | 0.51 | 0.13 | 0.52 | 0.43 | 0.44 | 0.43 |
| BLOOM 6.7B from scratch (50B tokens) | 69.32 | 0.51 | 0.52 | 0.13 | 0.41 | 0.38 | 0.42 | 0.39 |
| BLOOM 6.7B from scratch (72B tokens) | 64.03 | 0.56 | 0.51 | 0.09 | 0.40 | 0.37 | 0.49 | 0.40 |
- English: CLP-Transfer matches or surpasses from-scratch training performance with only half the training tokens for GPT-2-XL German (1.5B) and 20% for BLOOM-CLP German (6.4B).
- Japanese: CLP-Transfer は、GPT-2-XL German(1.5B)で学習トークンの約半分、BLOOM-CLP German(6.4B)で約20%でゼロからの学習と同等またはそれを上回る性能を達成。
- English: For GPT-2, CLP-Transfer reaches the same perplexity as from-scratch training after about 50% of tokens; WECHSEL lags behind.
- Japanese: GPT-2 では、約50% のトークン後に CLP-Transfer がゼロからの学習と同等のパープレキシティに達する;WECHSEL は遅れる。
- English: For BLOOM, CLP-Transfer reaches equivalent perplexity after about 20% of tokens, indicating up to ~80% training savings.
- Japanese: BLOOM では、約20%のトークン後に同等のパープレキシティに達し、最大で約80%の学習節約を示唆。
- English: In zero-shot downstream tasks, BLOOM-CLP 6.4B achieves the best average among monolingual German models (0.43) and outperforms several baselines.
- Japanese: ゼロショット下流タスクでは、BLOOM-CLP 6.4B がモノリンガルドイツ語モデルの平均で最高値(0.43)を達成し、いくつかのベースラインを上回る。
- English: Overall, CLP-Transfer demonstrates improved efficiency and competitive or superior downstream performance relative to baselines across multiple architectures and scales.
- Japanese: 全体として、CLP-Transfer は複数のアーキテクチャとスケールにおいて、ベースラインと比較して効率の向上と競争力のある、あるいは優れた下流性能を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。