[論文レビュー] Efficient Memory Management for Large Language Model Serving with PagedAttention
この論文は PagedAttention と vLLM を導入し、KV cache メモリの無駄を劇的に削減し、最先端システムと比べて LLM サービィングのスループットを 2–4x に向上させ、要求とデコードシナリオ全体での共有を改善します。
High throughput serving of large language models (LLMs) requires batching sufficiently many requests at a time. However, existing systems struggle because the key-value cache (KV cache) memory for each request is huge and grows and shrinks dynamically. When managed inefficiently, this memory can be significantly wasted by fragmentation and redundant duplication, limiting the batch size. To address this problem, we propose PagedAttention, an attention algorithm inspired by the classical virtual memory and paging techniques in operating systems. On top of it, we build vLLM, an LLM serving system that achieves (1) near-zero waste in KV cache memory and (2) flexible sharing of KV cache within and across requests to further reduce memory usage. Our evaluations show that vLLM improves the throughput of popular LLMs by 2-4$ imes$ with the same level of latency compared to the state-of-the-art systems, such as FasterTransformer and Orca. The improvement is more pronounced with longer sequences, larger models, and more complex decoding algorithms. vLLM's source code is publicly available at https://github.com/vllm-project/vllm
研究の動機と目的
- LLM サービィングにおけるスループットを制限するメモリアロケーションの課題を特定する。
- 廃棄を減らすために非連続な KV キャッシュ格納を可能にする新しいアテンションアルゴリズムを提案する。
- メモリ管理とデコードを共に最適化する分散型 LLM サービィングエンジンを設計する。
- FasterTransformer および Orca に対するさまざまなモデルとデコードシナリオでのスループット改善を実証する。
提案手法
- KV キャッシュを固定サイズのブロックに分割し、非連続なメモリ格納を可能にする PagedAttention を導入する。
- OS の仮想メモリに触発された KV キャッシュマネージャを開発し、論理 KV ブロックを物理ブロックにマッピングし、オンデマンド割り当てを可能にする。
- プロンプトフェーズと自己回帰生成を効率的にサポートするために、PagedAttentionと vLLM を共設計する。
- ブロックレベルの共有とコピーオンライトを適用して、シーケンス間およびビーム間でのメモリ共有を可能にする。
- ページドメモリフレームワーク内での可変の入力/出力長と多様なデコード手法(greedy、sampling、beam search)への対応を説明する。
- GPUワーカーを調整する集中型スケジューラを備えた分散アーキテクチャを説明する。
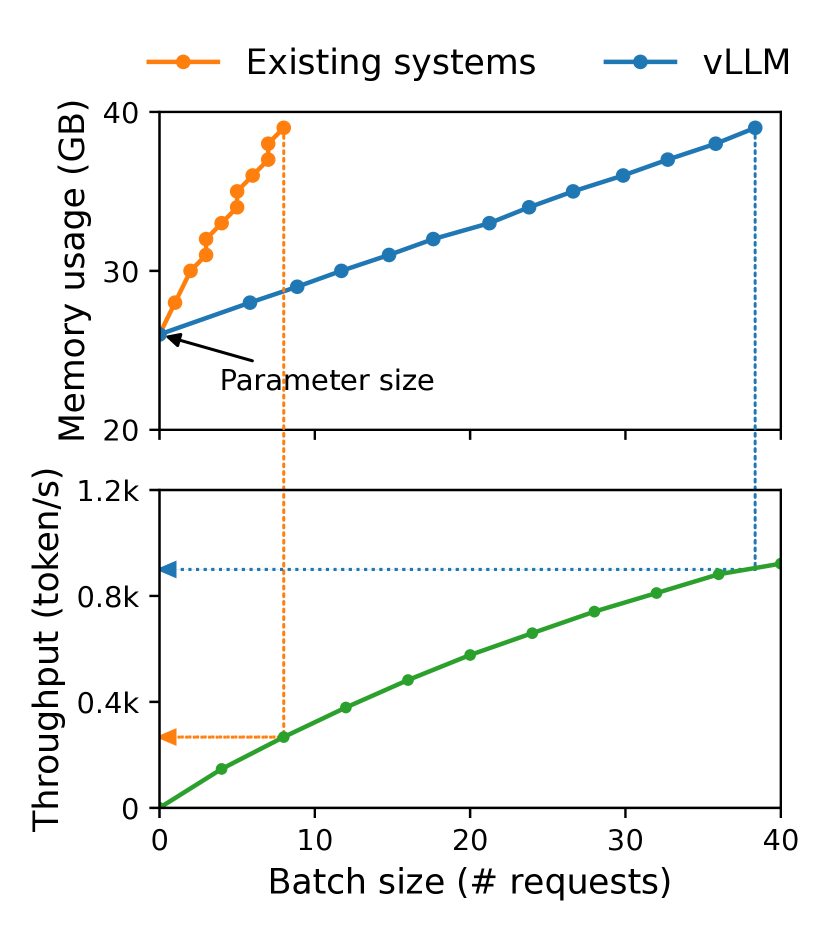
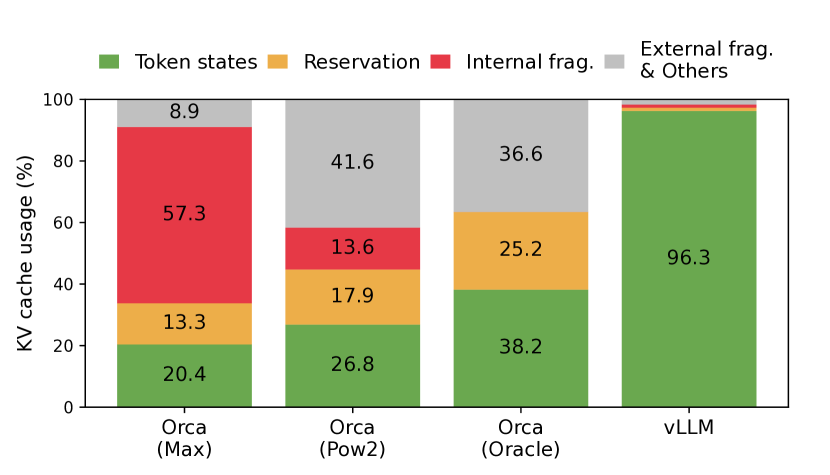
実験結果
リサーチクエスチョン
- RQ1非連続の KV キャッシュ格納は LLM サービィングにおけるメモリの無駄とバッチスループットにどのような影響を与えるか?
- RQ2ページド KV キャッシュ管理は、精度を維持しつつ、トークン、プロンプト、サンプル、およびビーム間で効果的なメモリ共有を可能にできるか?
- RQ3モデルとデコード戦略全体で、vLLM は FasterTransformer および Orca と比較してどの程度のスループット改善とメモリ節約を達成するか?
- RQ4ページドメモリモデルで変化するシーケンス長と複雑なデコード(ビームサーチ、並列サンプリング)をシステムはどのように扱うか?
主な発見
- vLLM は、類似のレイテンシを維持しつつ、最先端システムに対して LLM サービィングのスループットを 2–4x 改善する。
- PagedAttention は固定サイズの KV ブロックと非連続格納を可能にすることで KV キャッシュのメモリ無駄を削減する。
- ブロックレベルの管理とコピーオンライトにより、シーケンス間およびデコード候補間でのメモリ共有を有効にし、冗長な KV キャッシュのコピーを削減する。
- プロンプトとプレフィックスの共有をサポートし、共通プレフィックスの大幅なメモリ節約を実現する。
- このアプローチは長いシーケンス、より大きなモデル、より複雑なデコードアルゴリズムへ拡張可能で、精度を保つ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。