[論文レビュー] Efficient Multimodal Learning from Data-centric Perspective
Bunny は、注意深く凝縮された訓練データを用いた小さなマルチモーダルモデルが、より大きな MLLMs を上回り、3B パラメータで最先端の結果を達成することを示す。
Multimodal Large Language Models (MLLMs) have demonstrated notable capabilities in general visual understanding and reasoning tasks. However, their deployment is hindered by substantial computational costs in both training and inference, limiting accessibility to the broader research and user communities. A straightforward solution is to leverage smaller pre-trained vision and language models, which inevitably cause significant performance drops. In this paper, we demonstrate the possibility of training a smaller but better MLLM with high-quality training data. Specifically, we introduce Bunny, a family of lightweight MLLMs with flexible vision and language backbones for efficient multimodal learning from selected training data. Experiments show that our Bunny-4B/8B outperforms the state-of-the-art large MLLMs on multiple benchmarks. We expect that this work can provide the community with a clean and flexible open-source tool for further research and development. The code, models, and data can be found in https://github.com/BAAI-DCAI/Bunny.
研究の動機と目的
- MLLM の高い訓練/推論コストのため、手頃で高性能なマルチモーダルモデルの必要性を動機付ける。
- 軽量なバックボーンとデータ中心の訓練戦略を備えた Bunny のファミリーを提案する。
- データセットの凝縮と慎重なファインチューニングが、より大きなモデルとの差を縮める、あるいは凌ぐことができることを示す。
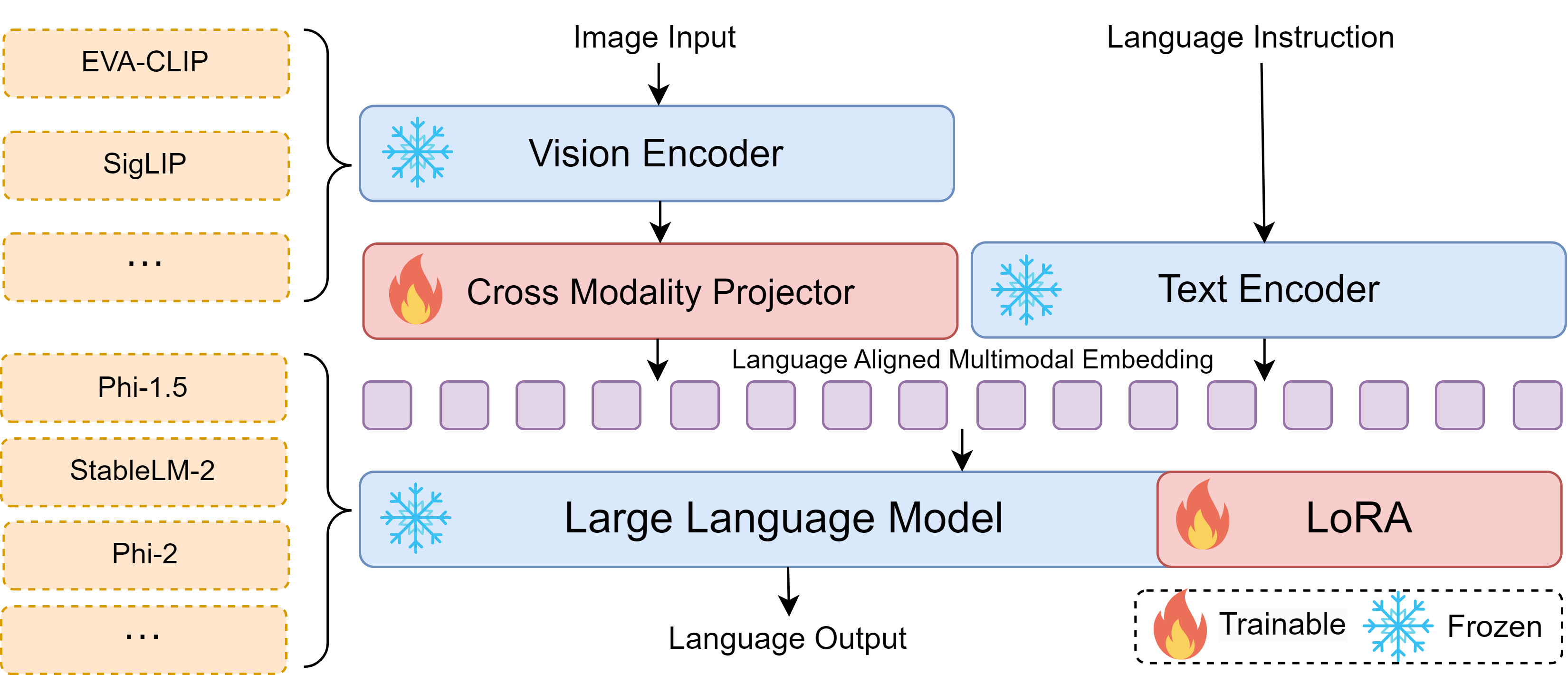
提案手法
- プラグアンドプレイの視覚エンコーダーと LLM バックボーン(SigLIP-SO、EVA-CLIP、Phi-2 など)を備えた Bunny を導入する。
- CLIP 埋め込みとクラスタリングベースの選択を用いて LAION-2B を 2M コアセットに凝縮し、高品質な事前訓練データを構築する。
- (multimodal データセットと高品質の純テキスト データを組み合わせた Bunny-695K のファインチューニングデータを作成し、認知を維持する。)
- 2 段階の訓練を使用:(1)クロスモダリティ・プロジェクターを介して視覚とテキストの埋め込みを整合させる;(2) LLM とプロジェクター上で LoRA を用いた視覚指示学習を行う。
- 両段階とも次のトークン予測のクロスエントロピー損失で訓練する;LoRA は完全微調整よりも好まれる。
- MME の認知/知覚、MMBench、SEED-Bench、MMMU、VQA-v2、GQA、ScienceQA-IMG、POPE を含む 11 のベンチマークで評価する。
実験結果
リサーチクエスチョン
- RQ1小さくデータ最適化されたマルチモーダルモデルが標準ベンチマークでより大きな MLLMs を超えることができるか。
- RQ2データ凝縮と高品質なファインチューニングデータは、モデルサイズと比較して性能にどのような影響を与えるか。
- RQ3Bunny にとって最も良いトレードオフを生むバックボーンの組み合わせ(視覚エンコーダ+ LLM)はどれか。
主な発見
| Model | Vision Encoder | LLM | MME^P | MME^C | MMB^T | MMB^D | SEED | MMMU^V | MMMU^T | VQA^v2 | GQA | SQA^I | POPE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Bunny | SigLIP-SO (0.4B) | Phi-2 (2.7B) | 1488.8 | 289.3 | 69.2 | 68.6 | 62.5 | 38.2 | 33.0 | 79.8 | 62.5 | 70.9 | 86.8 |
- SigLIP-SO と Phi-2 を用いた Bunny-3B は、同程度のサイズの多くの軽量 MLLMs を上回り、複数のベンチマークで優れた性能を示す。
- Bunny-3B は、パラメータ数の約 1/4 程度であるにもかかわらず、いくつかのタスクで LLaVA-v1.5-13B に対して競争力のある、または優れた結果を達成。
- バックボーンの中で、SigLIP-SO + Phi-2 がベンチマーク全体で最良の総合性能を示す。
- データ凝縮とファインチューニング時に高品質な純テキストデータを維持することは、認知能力とマルチモーダル機能を向上させる。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。