[論文レビュー] Embedded Graph Convolutional Networks for Real-Time Event Data Processing on SoC FPGAs
本論文は、SoC FPGA上でのリアルタイムイベントデータ処理のためのPointNet++風グラフ畳み込みネットワークのハードウェア認識最適化を提案し、モデルサイズを顕著に削減しつつ精度低下は抑え、4.47 msの遅延で13.3 MEPSのスループットを達成する。
The utilisation of event cameras represents an important and swiftly evolving trend aimed at addressing the constraints of traditional video systems. Particularly within the automotive domain, these cameras find significant relevance for their integration into embedded real-time systems due to lower latency and energy consumption. One effective approach to ensure the necessary throughput and latency for event processing is through the utilisation of graph convolutional networks (GCNs). In this study, we introduce a custom EFGCN (Event-based FPGA-accelerated Graph Convolutional Network) designed with a series of hardware-aware optimisations tailored for PointNetConv, a graph convolution designed for point cloud processing. The proposed techniques result in up to 100-fold reduction in model size compared to Asynchronous Event-based GNN (AEGNN), one of the most recent works in the field, with a relatively small decrease in accuracy (2.9% for the N-Caltech101 classification task, 2.2% for the N-Cars classification task), thus following the TinyML trend. We implemented EFGCN on a ZCU104 SoC FPGA platform without any external memory resources, achieving a throughput of 13.3 million events per second (MEPS) and real-time partially asynchronous processing with low latency. Our approach achieves state-of-the-art performance across multiple event-based classification benchmarks while remaining highly scalable, customisable and resource-efficient. We publish both software and hardware source code in an open repository: https://github.com/vision-agh/gcnn-dvs-fpga
研究の動機と目的
- 組込みFPGAプラットフォーム上で非同期イベントカメラデータのエネルギー効率が高くリアルタイム処理を実現する動機付けと実現方法の提示。
- スパースで動的なイベントグラフに適したPointNet++風GCNの適応と最適化。
- 固定遅延と既知スループットを持つZCU104 SoC FPGA上でのエンドツーエンドのハードウェアとソフトウェアの共設計の実演。
- 複数のイベントベースデータセットで100倍超のモデルサイズ削減を、許容できる精度低下とともに実現することの実証。
提案手法
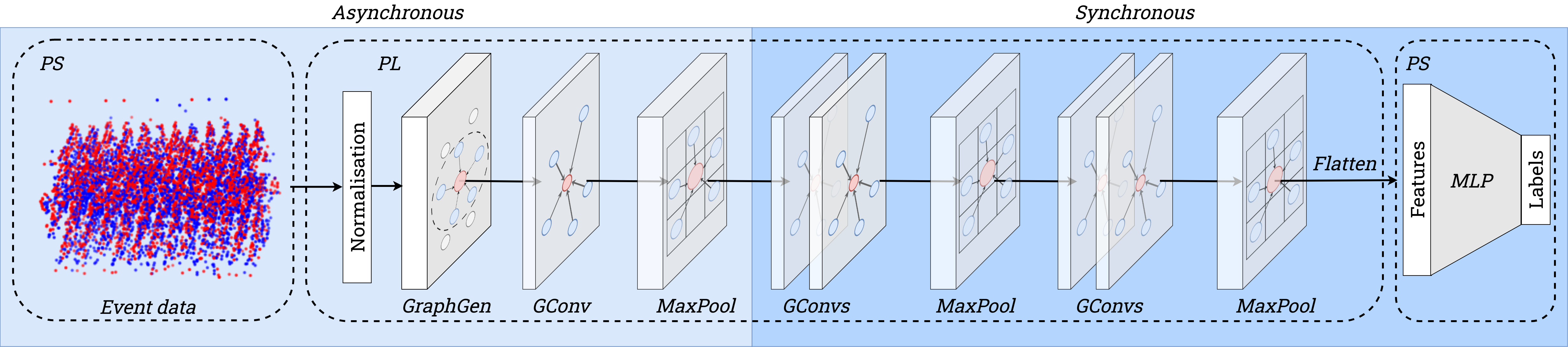
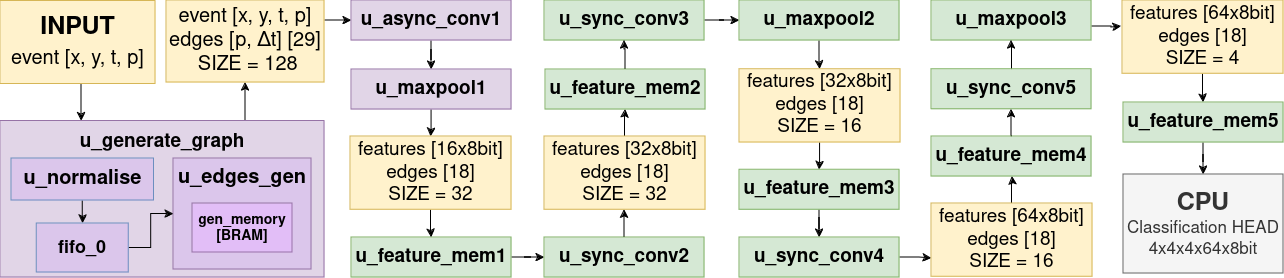
- 非同期イベントストリームから半径ベースのエッジを構築するハードウェア認識グラフ生成器を開発。
- グラフ上での最大プーリングを用いたPointNet++風グラフ畳み込みと、モデル削減のための三つのMaxPool層を採用。
- FPGAの制約に合わせた8ビット重みと32ビットバイアスを用いた量子化認識訓練。
- エッジ作成のための半径R内の近傍探索とFPGAに適した固定小数点実装を使用。
- 4つのイベントベースデータセット(N-Cars, N-Caltech101, CIFAR10-DVS, MNIST-DVS)で評価し、関連するGNNベースのイベント処理手法と比較。
実験結果
リサーチクエスチョン
- RQ1FPGA上のイベントストリーム向けのハードウェア認識GCN設計は、低遅延でリアルタイムスループットを達成できるか。
- RQ2標準のイベントベース分類ベンチマークにおける厳しいモデルサイズ削減が精度にどのような影響を与えるか。
- RQ3組み込みハードウェアでのグラフ構築における半径設定のトレードオフ(R=3対R=5)はどうなるか。
- RQ4イベントデータから得られる動的・非同期更新グラフに対してエンドツーエンドのFPGA加速が実現可能か。
主な発見
| Model | Representation | N-Cars | N-Caltech101 | CIFAR10-DVS | MNIST-DVS | Size [MB] | Param [M] |
|---|---|---|---|---|---|---|---|
| EV-VGCNN | ボクセル | 0.953 | 0.748 | 0.670 | - | 3.20 | 0.84 |
| VMV-GCN | ボクセル | 0.932 | 0.778 | 0.690 | - | 3.28 | 0.86 |
| VMST-Net | ボクセル | 0.944 | 0.822 | 0.753 | - | 3.61 | 0.95 |
| G-CNNs | グラフ | 0.902 | 0.630 | 0.515 | 0.974 | 18.81 | 4.93 |
| RG-CNNs | グラフ | 0.914 | 0.657 | 0.540 | 0.986 | 19.46 | 5.10 |
| NvS-S | グラフ | 0.915 | 0.670 | 0.602 | 0.986 | - | - |
| EvS-S | グラフ | 0.931 | 0.761 | 0.680 | 0.991 | - | - |
| AEGNN | グラフ | 0.945 | 0.668 | - | - | 83.31 | 21.84 |
| OAEGNN_R=3 | グラフ | 0.903 | 0.601 | 0.502 | 0.911 | 0.82 | 0.86 |
| OAEGNN_R=5 | グラフ | 0.928 | 0.645 | 0.541 | 0.942 | 0.82 | 0.86 |
| EFGCN_R=3 | グラフ | 0.853 | 0.576 | 0.478 | 0.892 | 0.40 | 0.42 |
| EFGCN_R=5 | グラフ | 0.896 | 0.619 | 0.498 | 0.904 | 0.40 | 0.42 |
- ZCU104 FPGAプラットフォームで最大13.3 MEPSのスループットと4.47 msの遅延を達成。
- 提案されたEFGCNファミリはAEGNNと比較して100倍を超えるモデルサイズ削減と大幅なメモリ効率を実現。
- OAEGNNは、複数データセット(例:N-Cars、N-Caltech101、CIFAR10-DVS、MNIST-DVS)で、より小さなモデルでも競争力のある精度を示す。
- 量子化認識訓練により、量子化後の精度低下を最小限に抑えつつ8ビット重みと32ビットバイアスを実現。
- 半径ベースのエッジとハードウェアに優しいNMベースの近傍探索を用いたグラフ構築は、非同期・即時更新を可能にする。
- 本アプローチは、リアルタイムイベントデータ向けのSoC FPGA上でのGCNのエンドツーエンドハードウェAcceleratorとして初の試みとして位置づけられる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。