[論文レビュー] EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
EmerNeRF は self-supervision から 4D の静的/動的シーン表現を学び、シーンフローが出現し、2D 基盤モデルの特徴を 4D 時空へ拡張する。ground-truth のセグメンテーションや pre-trained フローモデルなしで、静的/動的シーン再構成、新規視点合成、シーンフロー推定において NOTR で最先端の結果を達成する。
We present EmerNeRF, a simple yet powerful approach for learning spatial-temporal representations of dynamic driving scenes. Grounded in neural fields, EmerNeRF simultaneously captures scene geometry, appearance, motion, and semantics via self-bootstrapping. EmerNeRF hinges upon two core components: First, it stratifies scenes into static and dynamic fields. This decomposition emerges purely from self-supervision, enabling our model to learn from general, in-the-wild data sources. Second, EmerNeRF parameterizes an induced flow field from the dynamic field and uses this flow field to further aggregate multi-frame features, amplifying the rendering precision of dynamic objects. Coupling these three fields (static, dynamic, and flow) enables EmerNeRF to represent highly-dynamic scenes self-sufficiently, without relying on ground truth object annotations or pre-trained models for dynamic object segmentation or optical flow estimation. Our method achieves state-of-the-art performance in sensor simulation, significantly outperforming previous methods when reconstructing static (+2.93 PSNR) and dynamic (+3.70 PSNR) scenes. In addition, to bolster EmerNeRF's semantic generalization, we lift 2D visual foundation model features into 4D space-time and address a general positional bias in modern Transformers, significantly boosting 3D perception performance (e.g., 37.50% relative improvement in occupancy prediction accuracy on average). Finally, we construct a diverse and challenging 120-sequence dataset to benchmark neural fields under extreme and highly-dynamic settings.
研究の動機と目的
- 動的な走行シーンの静的および動的成分を手動アノテーションなしでデカップリングする。
- 新たに出現するシーンフローを学習し、時間的に配置がずれた特徴を集約して動的オブジェクトの表現を改善する。
- 2D 基盤モデルの特徴を 4D 時空へリフティングし、位置埋め込みアーティファクトを緩和しつつ意味理解を高める。
- 多様な走行データセット上で 4D ニューロフィールド再構成をベンチマークし、NOTR を道路上のバランスの取れたベンチマークとして確立する。
提案手法
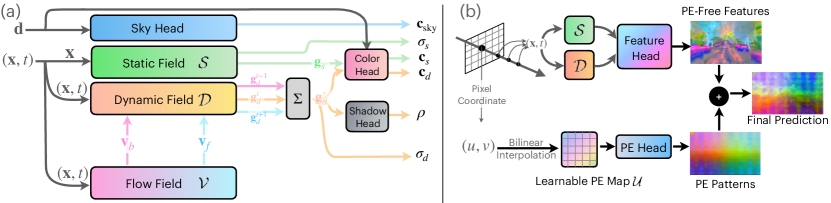
- 静的および動的フィールドを、x (静的) および (x, t) (動的) の learnable hash grid で分解する。
- 共有カラー Heads から per-point color を予測し、空と影の成分を別々に予測。
- 再構成損失のみで学習される Emergent な 3D シーンフローフィールド (v_f, v_b) を導入し、近接フレームの特徴を時間的に集約する。
- 時間を跨いで動的特徴を前方/後方の流れを介して集約し、動的オブジェクトのレンダリングを改善する。
- 2D 基盤モデルの特徴を 4D 空間へリフティングし、PE 除去モジュールを学習可能として、トランスフォーマーの位置埋め込みパターンを緩和する。
- 密度正則化損失を用いて動的密度を必要な場所のみに促し、フロー場のサイクル一貫性損失を導入する。
- 最適化は rgb、sky、shadow、depth、任意の特徴損失、PE対応の特徴再構成を組み合わせる。

実験結果
リサーチクエスチョン
- RQ1自己教師ありフレームワークは ground-truth アノテーションなしで 4D 走行シーンを静的/動的成分へ分解できるか?
- RQ2Emergent scene flow は NeRF ベースの表現における動的オブジェクトの特徴の多フレーム集約を効果的に可能にするか?
- RQ32D 基盤モデルの特徴を 4D 空間へリフティングは意味理解タスクを改善し、トランスフォーマーの PE パターンを緩和して 3D 一貫性を高められるか?
- RQ4EmerNeRF は既存の NeRF ベース手法と比較して静的/動的再構成、新規視点合成、シーンフロー推定でどのように性能を発揮するか?
主な発見
- EmerNeRF は NOTR で最先端の再構成と新規視点合成を達成し、静的シーンで +2.93、動的シーンで +3.70 の PSNR の大幅な改善、動的ビューの PSNR も +2.91 を達成。
- シーンフロー推定は NSFP を大幅に上回り、EPE3D が 0.365 m から 0.014 m に低下し、Acc_5/Acc_10 が向上。
- PE 不使用の 4D 特徴を ViT モデルからリフティングすると大きな意味的占有率の利得を得る;PE パターンを除去すると 3D 認識タスクで最大 63.22% 相対マイクロ精度向上と 37.50% 平均改善。
- PE 分解は特徴合成品質を大幅に改善し、特に DINOv2 で静的/動的/多様な分割で PSNR/占有率の改善が顕著。
- NOTR は 120 シーケンスのバランスの取れた多様なベンチマークを提供し、難条件下で静的/動的 NeRF を評価する。
- Emergent flow は reconstruction loss によって駆動され、光学フローの明示的な監督なしに時間的特徴集合から生じる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。