[論文レビュー] Empirical Analysis of the Strengths and Weaknesses of PEFT Techniques for LLMs
本論文は FLAN-T5-XL を用いてデータサイズとタスクの組み合わせで PEFT 手法(LoRA、IA3、BitFit、Prompt Tune)をベンチマークし、手法を選択するためのフレームワークを提案します。低〜中データでは全調整(フルチューニング)の収束が早い場合が多い一方、PEFT はより大きなデータで卓越し、非常にパラメータ効率的になり得ます。
As foundation models continue to exponentially scale in size, efficient methods of adaptation become increasingly critical. Parameter-efficient fine-tuning (PEFT), a recent class of techniques that require only modifying a small percentage of the model parameters, is currently the most popular method for adapting large language models (LLMs). Several PEFT techniques have recently been proposed with varying tradeoffs. We provide a comprehensive and uniform benchmark of various PEFT techniques across a representative LLM, the FLAN-T5 model, and evaluate model performance across different data scales of classification and generation datasets. Based on this, we provide a framework for choosing the optimal fine-tuning techniques given the task type and data availability. Contrary to popular belief, we also empirically prove that PEFT techniques converge slower than full tuning in low data scenarios, and posit the amount of data required for PEFT methods to both perform well and converge efficiently. Lastly, we further optimize these PEFT techniques by selectively choosing which parts of the model to train, and find that these techniques can be applied with significantly fewer parameters while maintaining and even improving performance.
研究の動機と目的
- Uniformで包括的なベンチマークを、代表的な LLM(FLAN-T5)を対象に、データ規模とタスクタイプ(分類と生成)を横断して実施する。
- PEFT とフルファインチューニングの収束速度、精度、その他の指標を分析し、PEFT を使うべき時とフルチューニングを使うべき時を理解する。
- モデルのどの部分(層/サブモジュール)が、PEFT 手法ごとに訓練する際に最も影響を与えるかを特定する。
- タスクタイプとデータ利用可能性に基づいて PEFT 手法を選択する実用的なフレームワークを提案する。
- 訓練パラメータを削減しつつ性能を維持・向上させる可能性のあるアブレーションを示す。
提案手法
- 4 種類の PEFT 手法(LoRA、(IA)3、Prompt tuning、BitFit)を、FLAN-T5-XL 上で複数のデータセットとデータ規模でフルファインチューニングと対比較する。
- AG News と CoLA は正確な文字列一致精度、E2E NLG と SAMSum は ROUGE-L を用いて評価する。
- 訓練する層/サブモジュールや変更する構成要素(例:アテンション vs 密結合ブロック)を変えてアブレーションを実施する。
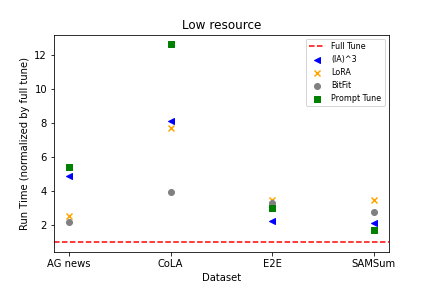
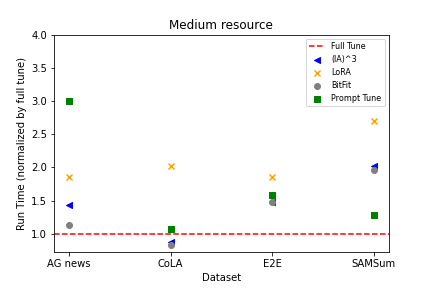
- 収束速度、メモリ使用量、計算コストを分析して効率-精度のトレードオフを導く。
- パラメータ数の図を提供し、性能をパラメータあたり(および実行時間あたり)で正規化して効率を比較する。
- リソース制約とデータ利用可能性を考慮して、フルチューニングまたは PEFT が望ましいかについて経験的指針を確立する。
実験結果
リサーチクエスチョン
- RQ1FLAN-T5-XL に対して低・中・高データ規模で、分類および生成タスクにおける異なる PEFT 手法はどのように機能するか。
- RQ2データ規模別に、PEFT とフルファインチューニングの収束特性とリソースコストはどうなるか。
- RQ3PEFT 手法を適用する際に、モデルのどのコンポーネント(層、アテンションブロック、活性化関数)が最も重要か。
- RQ4特定の層やサブモジュールを選択的に訓練することで、性能を損なわずに PEFT 手法をさらに最適化できるか。
- RQ5与えられたタスクとデータ規模に対して、適切な PEFT 手法を選ぶためのフレームワークを実務家に提供できるか。
主な発見
- PEFT 手法は、低〜中リソースのデータでは収束速度の点でフルチューニングに劣る傾向があるが、より大きなデータ量では性能が同等または上回ることがある。
- BitFit および LoRA は低〜中リソースのシナリオでよく機能する傾向があり、より多くのデータがあるとフルチューニングの相対的な性能向上を得られる。
- $(IA)^{3}$ は要素ごとのスケーリングによってメモリ効率を提供し、アブレーションで最小限の性能損失でパラメータ数を大幅に削減できる。
- アテンションレベルの変更と後段の層の選択が下流の性能に特に重要であり、$(IA)^{3}$ では後段層やランダムな層の選択が初期層の選択よりもしばしば優れている。
- 性能を損なうことなく大幅なパラメータ削減(しばしば半分以上)が実現可能で、より効率的な適応を実現できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。