[論文レビュー] Empirical Evaluation of Rectified Activations in Convolutional Network
この論文は、CNNにおける ReLU、Leaky ReLU、PReLU、RReLU を CIFAR-10/100 および NDSB で比較し、小規模データセットでは leaky variants がしばしば ReLU を上回ることを示す。Inception net のサブセットでアンサンブルなしで CIFAR-100 の精度 75.68% を報告。
In this paper we investigate the performance of different types of rectified activation functions in convolutional neural network: standard rectified linear unit (ReLU), leaky rectified linear unit (Leaky ReLU), parametric rectified linear unit (PReLU) and a new randomized leaky rectified linear units (RReLU). We evaluate these activation function on standard image classification task. Our experiments suggest that incorporating a non-zero slope for negative part in rectified activation units could consistently improve the results. Thus our findings are negative on the common belief that sparsity is the key of good performance in ReLU. Moreover, on small scale dataset, using deterministic negative slope or learning it are both prone to overfitting. They are not as effective as using their randomized counterpart. By using RReLU, we achieved 75.68\% accuracy on CIFAR-100 test set without multiple test or ensemble.
研究の動機と目的
- 非ゼロの負の勾配が ReLU を超える CNN の性能向上をもたらすかを評価する。
- ReLU、Leaky ReLU、PReLU、RReLU の4つの rectified activation functions を標準的な画像分類タスクで比較する。
- 小規模データセットと大規模データセットでの異なる活性化関数の過学習傾向を調査する。
- 小規模データセットにおける活性化の選択に関する指針と、ランダム化アプローチの潜在的利点を提示する。
提案手法
- ReLU、固定勾配 a_i を用いる Leaky ReLU、学習可能な負の勾配 a_i を用いる PReLU、訓練時にランダムな a_ji を用い、テスト時に固定する RReLU の4つの整流活性化を定義・実装する。
- 2つのCNNアーキテクチャを用い、CIFAR-10、CIFAR-100、NDSB データセットで同一のハイパーパラメータを用いた制御比較を実施する。
- 各活性化について訓練時とテスト時の性能および収束挙動を評価する。
- RReLU については、訓練時に Uniform(l,u) から a_ji をサンプルし、テスト時には (l+u)/2 を使用する、記述の設定に従う。
- アンサンブル法やマルチビュー検証を用いずに結果を報告する。
実験結果
リサーチクエスチョン
- RQ1負の入力値に非ゼロの勾配を導入することで、標準の ReLU と比較して CNN の性能が向上するか?
- RQ2Leaky ReLU 系統(PReLU および RReLU を含む)は、小規模データセットと大規模データセットのどちらでどのような性能を示すか?
- RQ3ランダム化された負の勾配(RReLU)は、小規模データセットで過学習を抑制するのに役立つか?
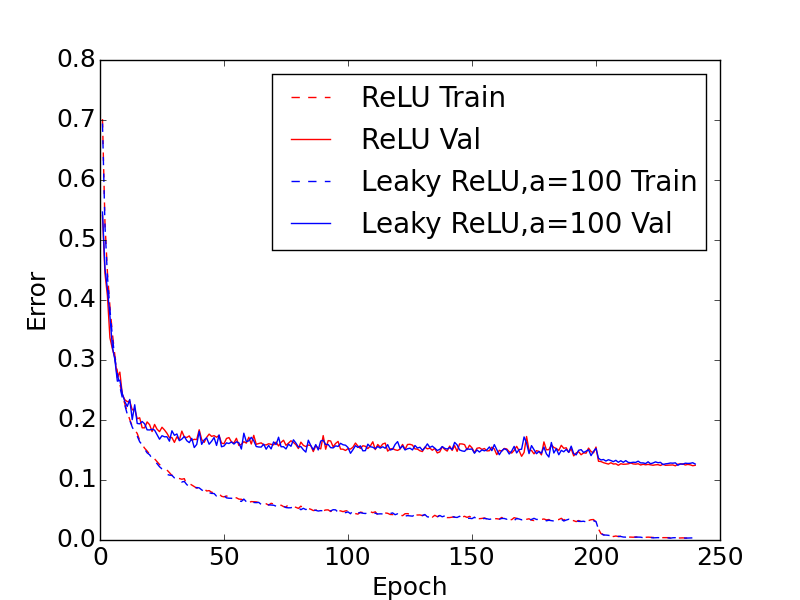
- RQ4CIFAR-10、CIFAR-100、および NDSB の各活性化に対する訓練誤差/損失とテスト誤差/損失の比較傾向はどのようなものか?
主な発見
| Activation | Training Error | Test Error |
|---|---|---|
| ReLU | 0.00318 | 0.1245 |
| Leaky ReLU, a=100 | 0.0031 | 0.1266 |
| Leaky ReLU, a=5.5 | 0.00362 | 0.1120 |
| PReLU | 0.00178 | 0.1179 |
| RReLU (y_ji = x_ji / ((l+u)/2)) | 0.00550 | 0.1119 |
- a=5.5 の Leaky ReLU は CIFAR-10/100 および NDSB のテストセットで一貫して ReLU を上回る。
- PReLU は最も低い訓練誤差を達成するが、小さなデータセットでより過学習し、テスト誤差は一部の leaky 変種より高い。
- RReLU は競争力のあるテスト誤差を示し、そのランダム性が過学習を抑制するのに役立つ、特に小さなデータセットで。
- CIFAR-100 では RReLU がいくつかの代替手法よりも低いテスト損失を達成し、過学習に対する頑健性を示す。
- 全体として、小規模データセットでは leaky 変種が ReLU を上回る。大規模データセットの結果はさらなる検討を要する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。