[論文レビュー] Empirical evidence of Large Language Model's influence on human spoken communication
本研究は280,000件のYouTubeトランスクリプトを20,000以上の学術チャンネルから分析し、ChatGPT編集テキストに特徴的な語の使用がChatGPT以降顕著に増加していることを示しており、人間が口頭コミュニケーションでLLMの言語を模倣する傾向が強まっていることを示唆している。
From the invention of writing and the printing press, to television and social media, human history is punctuated by major innovations in communication technology, which fundamentally altered how ideas spread and reshaped our culture. Recent chatbots powered by generative artificial intelligence constitute a novel medium that encodes cultural patterns in their neural representations and disseminates them in conversations with hundreds of millions of people. Understanding whether these patterns transmit into human language, and ultimately shape human culture, is a fundamental question. While fully quantifying the causal impact of a chatbot like ChatGPT on human culture is very challenging, lexicographic shift in human spoken communication may offer an early indicator of such broad phenomenon. Here, we apply econometric causal inference techniques to 740,249 hours of human discourse from 360,445 YouTube academic talks and 771,591 conversational podcast episodes across multiple disciplines. We detect a measurable and abrupt increase in the use of words preferentially generated by ChatGPT, such as delve, comprehend, boast, swift, and meticulous, after its release. These findings suggest a scenario where machines, originally trained on human data and subsequently exhibiting their own cultural traits, can, in turn, measurably reshape human culture. This marks the beginning of a closed cultural feedback loop in which cultural traits circulate bidirectionally between humans and machines. Our results motivate further research into the evolution of human-machine culture, and raise concerns over the erosion of linguistic and cultural diversity, and the risks of scalable manipulation.
研究の動機と目的
- AIシステムが書き言葉を超えた人間の口頭言語に影響を与えるかを評価する。
- ChatGPTのリリース後の大規模な学術動画セットにおける語の使用変化を定量化する。
- GPT特有の語とそれらの口頭言語への採用との関係を検討する。
提案手法
- 学術機関のYouTube動画 360,445 のデータセットを構築し、英語のトランスクリプト 279,480 件に絞り込む。
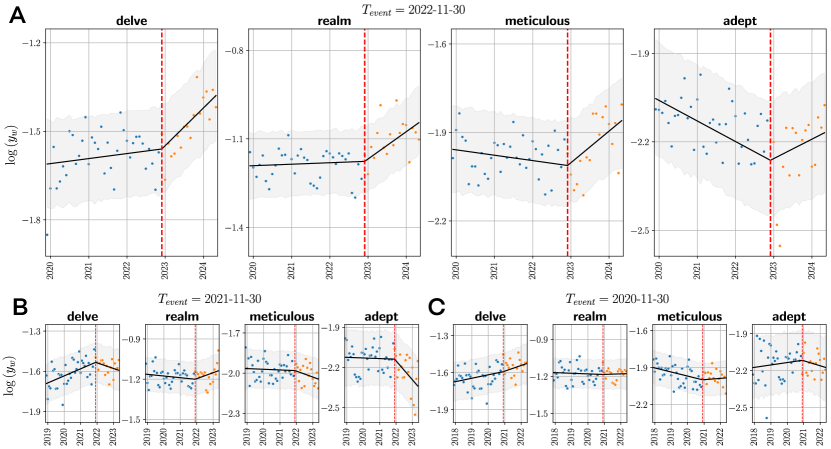
- 階層ベイズGaussian回帰を用いて自然変化と事象後の変化を評価し、月次の語頻度トレンドをモデル化する。
- Liang らのデータセットを用いてGPT特有の語を特定し、log-frequency ratio log(P_w,GPT / P_w,human) を算出する。
- ChatGPTのリリース後のトレンド変化係数 beta_w,GPT を計算する(T_event = 2022-11-30)18か月にわたって。
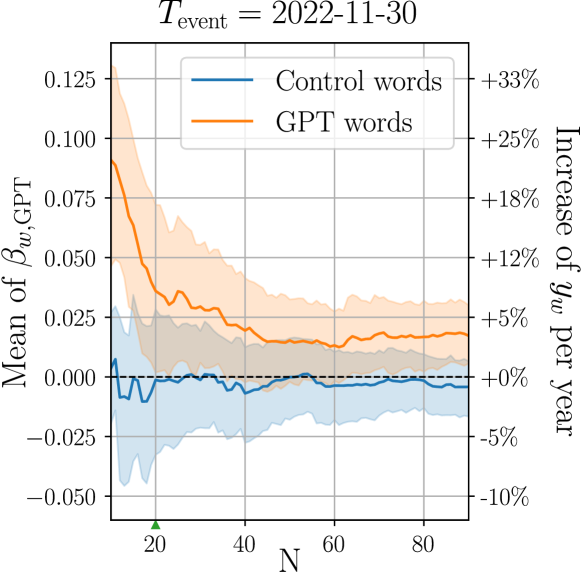
- GPT語の特異性と口頭言語への採用との相関を評価し、上位N語(例: 上位20語)に焦点を当てる。
- Nとチェンジポイントに関する感度分析で頑健性を検証する。
実験結果
リサーチクエスチョン
- RQ1人間はChatGPTのようなLLMに触れた後、書かれた言葉を超えて口頭言語を変えるのか。
- RQ2ChatGPT編集テキストに特徴的な語の頻度に、学術的な口頭コミュニケーション内で測定可能な変化があるか。
- RQ3ChatGPTに特有の語は、ChatGPTのリリース後に口頭言語で採用が加速される可能性が高いか。
- RQ4GPT語の特異性と採用の関連が、異なる語セットや観察窓でどのように振る舞うか。
主な発見
- ChatGPT後、特定のGPT語が口頭言語で加速的な採用を示す(例: beta_w,GPT は約 0.11–0.12、95% HDI [0.04, 0.18], [0.02, 0.22])。
- GPT語は事象後18か月で、事前ベースラインより約35–51%高いトレンドを経験する。
- ChatGPTに特有の語と口頭言語での採用の間に有意な関連があり、上位20語を考慮した場合が最も強く、(r = 0.63, p < 0.01)。
- コントロール語(下位N語)は事後のトレンド変化が顕著でない、GPT語に特異であることを示している。
- 観察されたトレンド変化はリリース後数か月経過してから現れるため、ChatGPT後データが必要である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。