[論文レビュー] Emu: Generative Pretraining in Multimodality
Emuは、テキスト・画像・動画を混在させたデータ上で統一的な自己回帰目的で事前学習された、14BのTransformerベースの多模态基盤モデルであり、テキストと画像の生成が可能で、視覚言語タスク全般においてゼロショットおよび少数ショットの性能が高い。
We present Emu, a Transformer-based multimodal foundation model, which can seamlessly generate images and texts in multimodal context. This omnivore model can take in any single-modality or multimodal data input indiscriminately (e.g., interleaved image, text and video) through a one-model-for-all autoregressive training process. First, visual signals are encoded into embeddings, and together with text tokens form an interleaved input sequence. Emu is then end-to-end trained with a unified objective of classifying the next text token or regressing the next visual embedding in the multimodal sequence. This versatile multimodality empowers the exploration of diverse pretraining data sources at scale, such as videos with interleaved frames and text, webpages with interleaved images and text, as well as web-scale image-text pairs and video-text pairs. Emu can serve as a generalist multimodal interface for both image-to-text and text-to-image tasks, and supports in-context image and text generation. Across a broad range of zero-shot/few-shot tasks including image captioning, visual question answering, video question answering and text-to-image generation, Emu demonstrates superb performance compared to state-of-the-art large multimodal models. Extended capabilities such as multimodal assistants via instruction tuning are also demonstrated with impressive performance.
研究の動機と目的
- 画像、テキスト、動画などの多様な混在データソースから学習できる、単一の汎用的な多模态モデルを構築する動機付け。
- 離散的なテキストトークンと連続的な視覚埋め込みの両方をモデル化する統一的な自己回帰目的の開発。
- モダリティ間のエンドツーエンド生成と理解を可能にする、画像からテキスト、テキストから画像、マルチモーダルな文脈内機能を含む。
- フレームと字幕が混在する動画、画像とテキストを含むWebページ、ウェブスケールの画像テキストペアなどのデータソースを探索。
- 指示調整済みのマルチモーダル機能を実証し、幅広いタスクでゼロショットおよび少数ショットの性能を評価。
提案手法
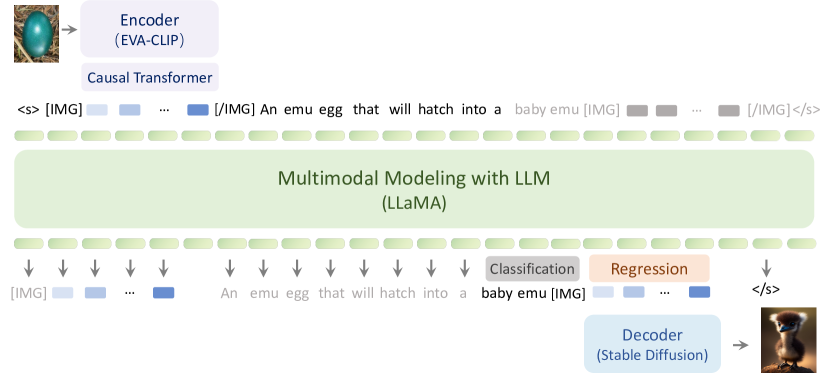
- Visual Encoder(EVA-CLIP)を用いて画像を埋め込みに変換する。
- 2Dの視覚信号を統一モデリングのための1D因果潜在空間へ変換する因果トランスフォーマーを導入。
- テキストと視覚埋め込みの混在系列を扱うMultimodal Modeling LLM(LLaMAから初期化)を構築。
- 視覚埋め込みから画像を生成するVisual Decoder(Stable Diffusionで初期化された潜在拡散モデル)を適用。
- テキストトークンにはクロスエントロピー、視覚埋め込みにはL2損失を用いて、次の要素を予測することでマルチモーダル系列の尤度を最大化する統一目的で事前学習。
- 多様なウェブ規模データで訓練:image-textペア(LAION-2B/LAION-COCO)、混在画像-テキスト(MMC4)、video-text(WebVid-10M)、混在動画-テキスト(YT-Storyboard-1B)。
- ShareGPT、Alpaca、LLaVA、VideoChat、Video-ChatGPT などのデータセットを用いて Multimodal Modeling LLM に LoRA を適用したマルチモーダル指示調整を行う。

実験結果
リサーチクエスチョン
- RQ1Emuは動画、画像、テキストを含む混在マルチモーダルデータから統一表現と生成能力を学習できるか。
- RQ2離散的なテキストトークンと連続的な視覚埋め込みの両方を含む単一の自己回帰目的は、従来のLMMと比べてゼロショットおよび少数ショットのマルチモーダルタスクを改善するか。
- RQ3Emuは画像-to-テキスト、テキスト-to-画像、文脈内マルチモーダル生成を可能にする汎用的なマルチモーダルインターフェースとして、指示調整済みマルチモーダルアシスタントを含めて機能するか。
主な発見
| モデル | COCO | VQAv2 | OKVQA | VizWiz | VisDial | MSVDQA | MSRVTTQA | NExTQA |
|---|---|---|---|---|---|---|---|---|
| Kosmos-1 | 84.7 | 51.0 | - | 29.2 | - | - | - | - |
| Flamingo-9B * | 79.4 | 51.8 | 44.7 | 28.8 | 48.0 | 30.2 | 13.7 | 23.0 |
| Emu | 112.4 | 52.0 | 38.2 | 34.2 | 47.4 | 18.8 | 8.3 | 19.6 |
| Emu * | - | 52.9 | 42.8 | 34.4 | 47.8 | 34.3 | 17.8 | 23.4 |
| Emu-I | 117.7 | 40.0 | 34.7 | 35.4 | 48.0 | 32.4 | 14.0 | 6.8 |
| Emu-I * | - | 57.5 | 46.2 | 38.1 | 50.1 | 36.4 | 21.1 | 19.7 |
- Emuは画像キャプション生成とVQAタスクで強力なゼロショット性能を達成、例えばゼロショットCOCOキャプションのCIDErスコアは112.4。
- ゼロショット設定で、Emu (14B) はVQAおよびVizWizでいくつかのより大きなマルチモーダルモデルを上回り、Emu-I(指示調整済み)が顕著な改善をもたらす。
- MS-COCOでのゼロショットのテキスト-to-画像生成では、EmuはFID 11.66と競争力のある値を達成し、条件によっては複数の単一モーダル/マルチモーダルベースラインに近づくまたは上回る。
- 少数ショットの結果は、混在データとRICESの例選択を用いたEmuが、Flamingo-9BおよびKosmos-1と比較してVQAv2、VizWiz、MSVDQA、MSRVTTQAで改善を示す。
- 指示調整により、画像と動画のマルチターン対話や指示に従う能力を含む、マルチモーダルアシスタント機能が向上。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。