[論文レビュー] Enhancing LLM Factual Accuracy with RAG to Counter Hallucinations: A Case Study on Domain-Specific Queries in Private Knowledge-Bases
本論文は、CMU/LTIの private knowledge baseを用いたエンドツーエンドのRAGベースQAシステムを提案し、埋め込みとコアモデルのファインチューニングが性能に寄与するかどうかをアブレーションで示す。
We proposed an end-to-end system design towards utilizing Retrieval Augmented Generation (RAG) to improve the factual accuracy of Large Language Models (LLMs) for domain-specific and time-sensitive queries related to private knowledge-bases. Our system integrates RAG pipeline with upstream datasets processing and downstream performance evaluation. Addressing the challenge of LLM hallucinations, we finetune models with a curated dataset which originates from CMU's extensive resources and annotated with the teacher model. Our experiments demonstrate the system's effectiveness in generating more accurate answers to domain-specific and time-sensitive inquiries. The results also revealed the limitations of fine-tuning LLMs with small-scale and skewed datasets. This research highlights the potential of RAG systems in augmenting LLMs with external datasets for improved performance in knowledge-intensive tasks. Our code and models are available on Github.
研究の動機と目的
- 外部データソースを活用して、ドメイン固有かつ時期性の高いクエリに対するLLMの幻覚を減らす動機づけ。
- RAGベースのQAを支えるため、CMU/LTIに特化したデータセットと評価フレームワークを作成する。
- 検索と生成を組み合わせたRAGパイプラインを開発・評価し、事実に基づく文脈対応の回答を提供する。
- 埋め込みとコアモデルのファインチューニングがシステム性能に与える影響と、少量で偏りのあるデータセットの制約を調査する。
提案手法
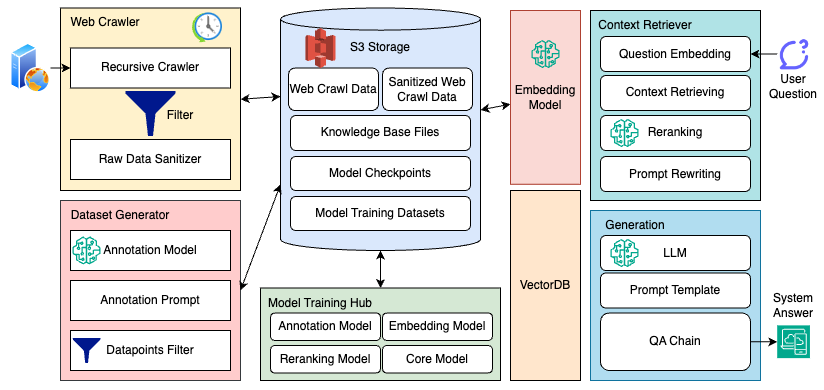
- Context RetrieverとGenerative Modelを備えたRAG QAパイプラインを構築し、LLaMA-2をコアジェネレータとして使用する。
- ウェブクローラ、前処理、自動アノテーションを用いて、CMU/LTIに焦点を当てたデータセットを作成し、QAペアを生成する。
- 類似度に基づく上位5チャンクを用いた二段階検索と、クロスエンコーダーリランカーを用いたリランキングを適用する。
- QAデータセット上で埋め込みモデルとコアモデルをファインチューニングし、Recall、F1、Cosine Similarity、BLEU指標で評価する。
- 各コンポーネントの影響を評価するアブレーション研究とケーススタディでシステムを評価する。
実験結果
リサーチクエスチョン
- RQ1外部のCMU/LTIコンテキストを取得することは、ドメイン固有の質問に対するLLM生成回答の事実性を改善するか。
- RQ2埋め込みモデルのファインチューニングとコアモデルのファインチューニングは、RAG設定における取得品質と回答生成にどのような影響を与えるか。
- RQ3提案されたエンドツーエンドのRAGシステムが時期性のあるドメインクエリに対して得られる性能向上と制約は何か。
- RQ4トレーニング/ファインチューニングの信頼性を示す品質指標(IAA/Cohen’s Kappa)は何か。
主な発見
| Recall | F1 Score | Cosine | BLEU |
|---|---|---|---|
| 0.361 (0.069) | 0.186 (0.032) | 0.504 | 0.043 |
| 0.409 (0.081) | 0.289 (0.065) | 0.577 | 0.102 |
| 0.437 (0.076) | 0.304 (0.063) | 0.597 | 0.108 |
| 0.448 (0.106) | 0.211 (0.056) | 0.502 | 0.056 |
| 0.452 (0.107) | 0.219 (0.060) | 0.515 | 0.060 |
- RAGベースQAパイプラインはRAGなしのベースラインよりRecallとF1スコアを向上させる。
- 埋め込みモデルのファインチューニングはRecallとF1を改善し、より良い意味理解を示す。
- コアモデルのファインチューニングはRecallの向上をもたらすが、データセットのサイズや偏りのためF1が低下する可能性があり、オーバーフィットや生成の問題を示唆する。
- 埋め込みとコアモデルのファインチューニングをRAGと組み合わせると、埋め込みのみの場合と比べて限られた利得、またはF1の低下を招くことがあり、小さく偏ったデータセットとのトレードオフを強調する。
- データセットはかなりのアノテータ間一致を達成した(Cohen’s Kappa = 0.67)。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。