[論文レビュー] EquiformerV2: Improved Equivariant Transformer for Scaling to Higher-Degree Representations
EquiformerV2 は eSCN 畳み込みとアーキテクチャの改良を用いて、等価変換可能な Transformer's を高次の表現へスケールさせ、OC20 で速度-精度およびデータ効率を改善した最先端の結果を達成します。さらに AdsorbML で DFT 緩和を削減し、OC22 の性能を GemNet-OC より向上させます。
Equivariant Transformers such as Equiformer have demonstrated the efficacy of applying Transformers to the domain of 3D atomistic systems. However, they are limited to small degrees of equivariant representations due to their computational complexity. In this paper, we investigate whether these architectures can scale well to higher degrees. Starting from Equiformer, we first replace $SO(3)$ convolutions with eSCN convolutions to efficiently incorporate higher-degree tensors. Then, to better leverage the power of higher degrees, we propose three architectural improvements -- attention re-normalization, separable $S^2$ activation and separable layer normalization. Putting this all together, we propose EquiformerV2, which outperforms previous state-of-the-art methods on large-scale OC20 dataset by up to $9\%$ on forces, $4\%$ on energies, offers better speed-accuracy trade-offs, and $2 imes$ reduction in DFT calculations needed for computing adsorption energies. Additionally, EquiformerV2 trained on only OC22 dataset outperforms GemNet-OC trained on both OC20 and OC22 datasets, achieving much better data efficiency. Finally, we compare EquiformerV2 with Equiformer on QM9 and OC20 S2EF-2M datasets to better understand the performance gain brought by higher degrees.
研究の動機と目的
- Transformer ベースのアーキテクチャにおいて高次の等価表現(Lmax)を実現して3D 原子系のモデリングを進展させる。
- 大規模 OC20/OC22 データセットに対する力とエネルギーの予測精度を向上させる。
- AdsorbML や DFT 強化ワークフローなど、実用的な応用を可能にする学習および推論の効率を高める。
- 従来手法と比較してデータ効率とアウト・オブ・ディストリビューション性能を示す。
提案手法
- EquiformerV2 で SO(3) 畳み込みを置換し、eSCN 畳み込みを用いて高い Lmax(最大 6–8)を実現する。
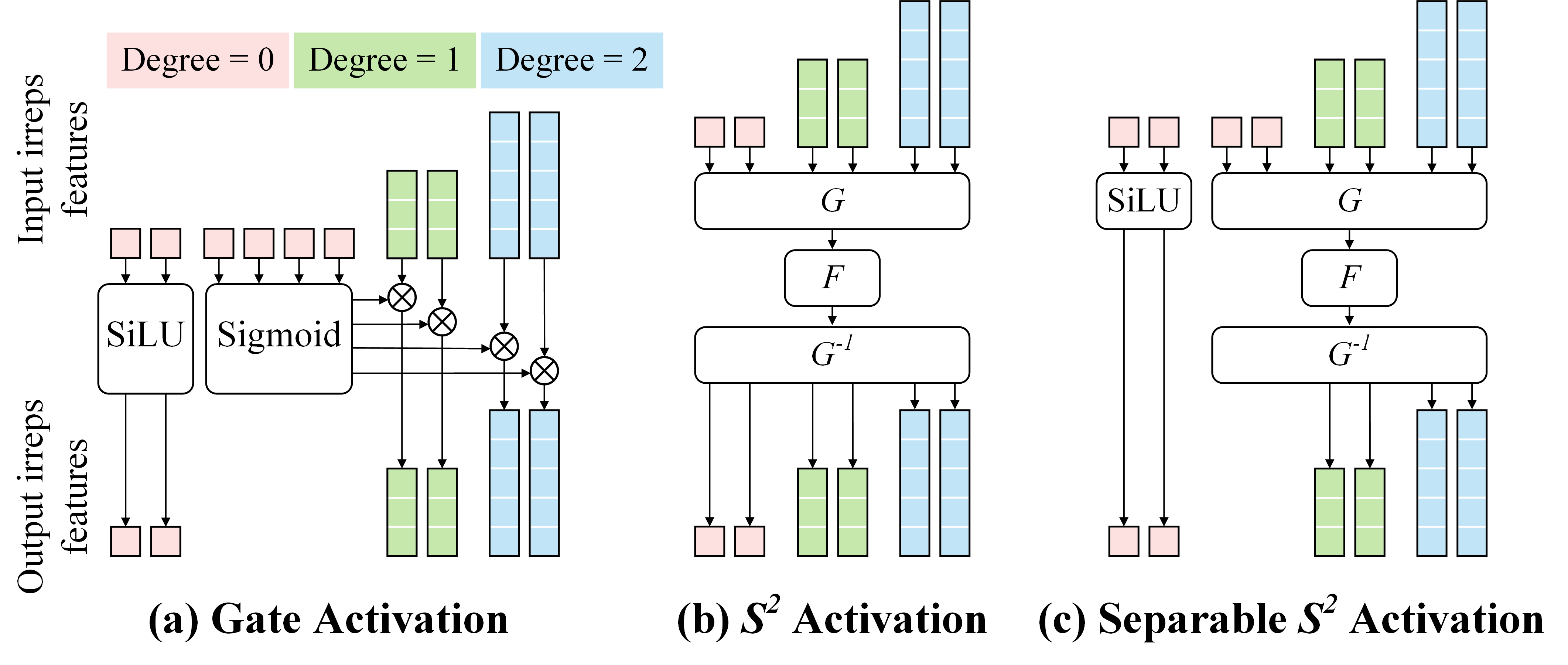
- アーキテクチャの改良を導入: アテンション正規化、分離可能な S2 活性化、分離可能な層正規化。
- 等価グラフアテンションとフィードフォワード構造を維持しつつ、度とチャネル情報を混ぜるために eSCN を使用。
- 放射距離埋め込みと SO(2) 線形層を用いて効率的な等価メッセージ伝搬を実現。
- OC20 S2EF(All および All+MD)と OC22 データセット、AdsorbML シナリオを評価し、先行最先端と比較する。
実験結果
リサーチクエスチョン
- RQ1高次の表現(より大きな Lmax)を用いた等価 Transformers を用いて、3D 原子系で効率的な畳み込みを用いてスケーリングできるか?
- RQ2アテンション正規化、分離可能な S2 活性化、分離可能 LN のアーキテクチャ改良は、より高次の次数を使用した場合、ベースラインの Equiformer より顕著な利得をもたらすか?
- RQ3EquiformerV2 は OC20/OC22 ベンチマークでデータ効率が高く学習を速く達成し、既存手法を上回ることができるか?
- RQ4AdsorbML における吸着エネルギー作業流れと DFT 計算の削減に対する影響はどの程度か?
- RQ5高次の次数による性能向上の点で、EquiformerV2 は QM9 および OC20 S2EF-2M で Equiformer および GemNet-OC と比較してどの程度の改善を示すか?
主な発見
- eSCN 畳み込みと高次の次数を組み合わせた EquiformerV2 は、OC20 で力の精度を最大で 9%、エネルギーを最大で 4% まで改善し、以前の最先端を上回る。
- アテンション正規化と分離可能な S2 活性化は学習の安定性と力/エネルギーの精度を改善し、分離可能 LN は力の MAE をさらに向上させる。
- OC22 のみで学習した EquiformerV2 は OC20 および OC22 を対象とした GemNet-OC を上回り、データ効率が高いことを示す。
- AdsorbML において EquiformerV2 は成功率を高め、比較可能な吸着エネルギー精度を得るための DFT 計算を最大で 2 倍削減する。
- λE=4, λF=100 の EquiformerV2(153M パラメータ)は OC20 S2EF-All+MD で最先端の結果を達成し、力 MAE の改善と速度-精度の有利なトレードオフを示す。
- 小型版(λE=4, λF=100, 31M)でも学習/推論効率の良好な性能を示し、スケーラブルな導入ポテンシャルを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。