[論文レビュー] Evaluating Large Language Models for Public Health Classification and Extraction Tasks
本論文は、オープンウェイトLLM(7–70B)を、負荷(burden)・リスク要因・介入の3領域にまたがる17の公衆衛生分類・抽出タスクで評価し、ゼロショットプロンプトと少数ショットプロンプトを比較する。subsetタスクではGPT-4をベンチマークとして用いる。
Advances in Large Language Models (LLMs) have led to significant interest in their potential to support human experts across a range of domains, including public health. In this work we present automated evaluations of LLMs for public health tasks involving the classification and extraction of free text. We combine six externally annotated datasets with seven new internally annotated datasets to evaluate LLMs for processing text related to: health burden, epidemiological risk factors, and public health interventions. We evaluate eleven open-weight LLMs (7-123 billion parameters) across all tasks using zero-shot in-context learning. We find that Llama-3.3-70B-Instruct is the highest performing model, achieving the best results on 8/16 tasks (using micro-F1 scores). We see significant variation across tasks with all open-weight LLMs scoring below 60% micro-F1 on some challenging tasks, such as Contact Classification, while all LLMs achieve greater than 80% micro-F1 on others, such as GI Illness Classification. For a subset of 11 tasks, we also evaluate three GPT-4 and GPT-4o series models and find comparable results to Llama-3.3-70B-Instruct. Overall, based on these initial results we find promising signs that LLMs may be useful tools for public health experts to extract information from a wide variety of free text sources, and support public health surveillance, research, and interventions.
研究の動機と目的
- オープンウェイトLLMが、公衆衛生の自由テキスト分類・抽出タスクの広範なセットでどのようにパフォーマンスを発揮するかを評価する。
- モデル・タスク・データソース間で性能差を生み出す要因を特定する。
- 公衆衛生特化LLMの今後のファインチューニングおよび統制された導入の基準線を提供する。
- 一部タスクでGPT-4との比較を行い、民間モデルとの整合性を評価する。
提案手法
- 負荷・リスク要因・介入の3サブ領域にまたがる17の公衆衛生タスクを、13の外部データセットと7の内部データセットから収集する。
- 標準化された prompting/後処理フレームワークを用いて、0ショット prompting で5つのオープンウェイトLLM(7–70B)を評価する。
- データガバナンスと再現性を確保するため、UKHSA HPCリソース上の内部LLM APIを使用する。
- ゼロショットの結果を比較し、最も難しいタスクで10-shot/7-shotの少数ショットプロンプトを選択する。
- マイクロ-F1(主要)とマクロ-F1スコアを計算し、抽出には正確一致を用い、出力をグラウンドトゥルースラベルに合わせて後処理する。
- 外部ベンチマークのために12タスクでGPT-4の結果を含める。
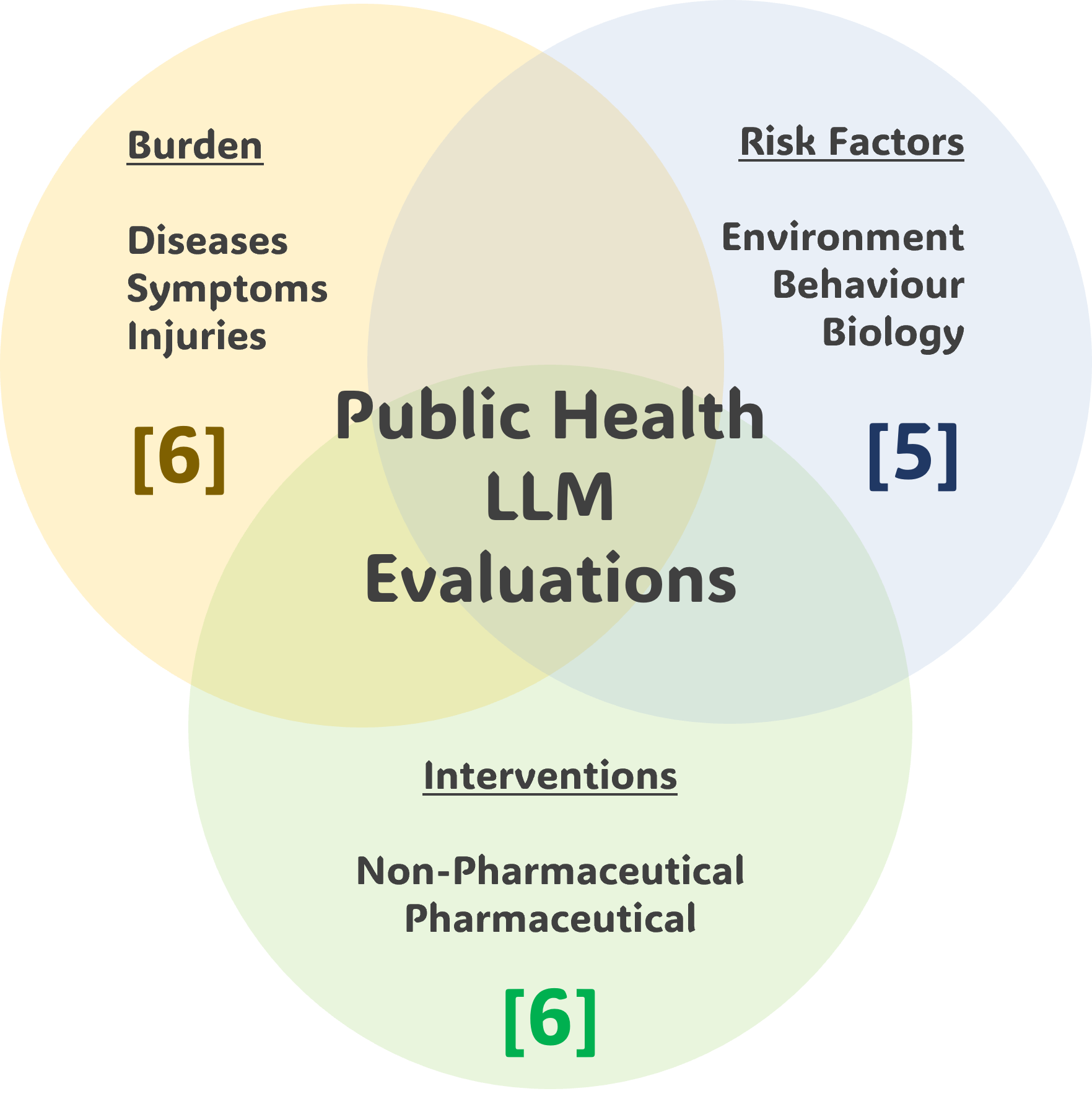
実験結果
リサーチクエスチョン
- RQ1ゼロショット prompting の下で、オープンウェイトLLMは公衆衛生の分類・抽出タスクの広範なセットでどのようにパフォーマンスを示すか。
- RQ2タスク種別、データソース、モデルサイズが性能に与える影響はどのようか。
- RQ3難易度の高い公衆衛生タスクで、少数ショットプロンプトは性能を大幅に向上させるか。
- RQ4GPT-4は、タスクの一部で上位のオープンウェイトモデルとどう比較されるか。
- RQ5現在のLLMにとって依然として難しいタスクはどれで、今後の改善が必要か。
主な発見
- Llama-3-70B-Instructは、ゼロショットプロンプト下で17タスク中15タスクで最高のmicro-F1を達成。
- いくつかのタスクは、すべてのオープンウェイトモデルにとって依然として難しく、micro-F1が60%未満(例:BioDex Drugs Extraction、Contact Classification、MMLU Virology)。
- GPT-4は、調査対象の12タスクの約半数でオープンウェイトモデルと同等かそれを上回るが、他のいくつかではLlama-3-70B-Instructに敗れる。
- 難易度の高いタスク(例:Contact Classification、Health Causal Claims Classification)では、少数ショット prompting によりマイクロ-F1がしばしば15ポイント以上改善。Flan-T5-xxlを除くすべてのモデルで。
- モデルサイズとアーキテクチャ(例:Llama-3-8B-Instruct から Llama-3-70B-Instruct へ)により、主要タスク(例:MMLU Genetics、MMLU Nutrition、Health Advice、Causal Relation)で10ポイント超のmicro-F1向上を得られる。
- 総じて、オープンウェイトLLMは公衆衛生の自由テキストの構造化と監視支援に有望だが、専門知識タスクには留意が必要。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。