[論文レビュー] Evaluating the World Model Implicit in a Generative Model
この論文は、生成系列モデルが基礎となる決定性有限オートマトン(世界モデル)を回復するかどうかをMyhill-Nerodeに触発された指標を用いて評価する方法を形式化し、標準的な次トークンの探査がナビゲーション、ゲーム、論理パズルといった領域で誤解を招く可能性があることを示す。
Recent work suggests that large language models may implicitly learn world models. How should we assess this possibility? We formalize this question for the case where the underlying reality is governed by a deterministic finite automaton. This includes problems as diverse as simple logical reasoning, geographic navigation, game-playing, and chemistry. We propose new evaluation metrics for world model recovery inspired by the classic Myhill-Nerode theorem from language theory. We illustrate their utility in three domains: game playing, logic puzzles, and navigation. In all domains, the generative models we consider do well on existing diagnostics for assessing world models, but our evaluation metrics reveal their world models to be far less coherent than they appear. Such incoherence creates fragility: using a generative model to solve related but subtly different tasks can lead to failures. Building generative models that meaningfully capture the underlying logic of the domains they model would be immensely valuable; our results suggest new ways to assess how close a given model is to that goal.
研究の動機と目的
- 実世界ドメイン(論理、ナビゲーション、ゲーム、化学)に基づく決定性有限オートマトン(DFA)を基礎とする世界モデルの評価を形式化する。
- 系列モデルにおける世界モデルの回復を評価するためのMyhill-Nerodeに触発された指標を提案する。
- 複数ドメインにわたる指標の実証を通じて、次トークンベースの評価の脆弱性を示す。
- 生成モデルにおける世界モデルの一貫性を評価するための公開ベンチマークデータとツールを提供する。
提案手法
- 生成モデルと世界モデルを結ぶDFAベースの枠組みを定義する。
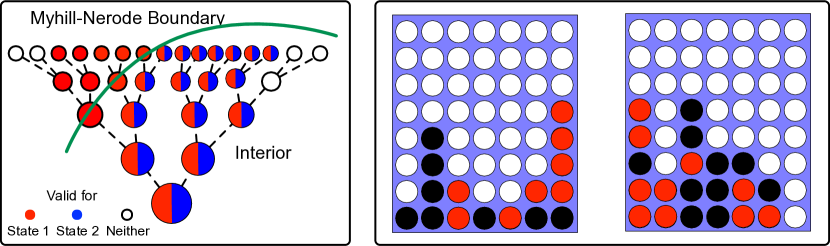
- 2つの指標を導入する:シーケンス圧縮(同じ状態は同じ継続を生み出すべき)とシーケンス区別(異なる状態は異なる継続を生み出すべき)。
- 正確な次トークン予測とDFAの回復との関連(命題2.3)。
- モデルによって回収された暗黙のマップを可視化するためにグラフ再構成を適用する。
- 評価指標を説明するため、3つのドメイン(ナビゲーション用のNYCタクシーの曲がり順序、オセロ、論理パズル)を用いる。
- 真のDFAへのアクセスがある場合に指標を計算するためのモデル非依存の手順を提供する。
実験結果
リサーチクエスチョン
- RQ1生成系列モデルは、あるドメインを支配する基礎となるDFA(世界モデル)を回復できるか?
- RQ2既存の次トークン診断やプローブベースの診断は、世界モデルの回復を評価するのに十分か?
- RQ3Myhill-Nerodeに触発された指標は、従来の診断に合格するモデルにおいても不整合や脆弱性を露呈するか?
- RQ4異なるデータ生成プロセス(最短経路、ノイズ付き経路、ランダムウォーク)が回復された世界モデルにどのように影響するか?
- RQ5不完全な世界モデル回復が迂回耐性などの下流タスクに及ぼす影響はどの程度か?
主な発見
| 既存の指標 | 提案指標 | 次トークンテスト | 現在の状態プローブ | 圧縮精度 | 区別精度 | 区別再現率 |
|---|---|---|---|---|---|---|
| Untrained transformer | 0.03 (0.00) | 0.10 (0.00) | 0.00 (0.00) | 0.00 (0.00) | 0.01 (0.00) | |
| Shortest paths | 1.00 (0.00) | 0.91 (0.00) | 0.19 (0.01) | 0.36 (0.01) | 0.26 (0.01) | |
| Noisy shortest paths | 1.00 (0.00) | 0.90 (0.00) | 0.07 (0.01) | 0.36 (0.01) | 0.25 (0.01) | |
| Random walks | 1.00 (0.00) | 0.99 (0.00) | 0.68 (0.02) | 0.99 (0.00) | 1.00 (0.00) | |
| True world model | 1.00 | — | 1.00 | 1.00 | 1.00 |
- 標準的な次トークン診断は世界モデルの回復について誤解を招く可能性がある;モデルは有効な次トークン予測を持つ一方で全体構造が一貫性を欠くことがある。
- Myhill-Nerodeに触発された2つの指標――シーケンス圧縮精度とシーケンス区別精度――は、既存のプローブに捉えられない不整合を浮き彫りにする。
- NYCタクシーの方向指示で訓練されたトランスフォーマは有効な次の動作や最短経路を予測できるが、現実のマンハッタンの街路網と構造的に適合しない地図を再構成する。
- 不整合な世界モデルを持つモデルは迂回耐性を示す。迂回が生じると再ルーティング能力が低下する。ランダムウォークで訓練されたモデルの一部とは対照的。
- オセロと論理パズルを通じて、モデルは従来の指標で良好な成績を示しつつ、真の基礎状態構造を捉えられていないことがあり、従来の診断の脆弱性の広がりを示している。
- 著者らは世界モデル回復を評価するデータセットとソフトウェアを提供する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。