[論文レビュー] Event Stream GPT: A Data Pre-processing and Modeling Library for Generative, Pre-trained Transformers over Continuous-time Sequences of Complex Events
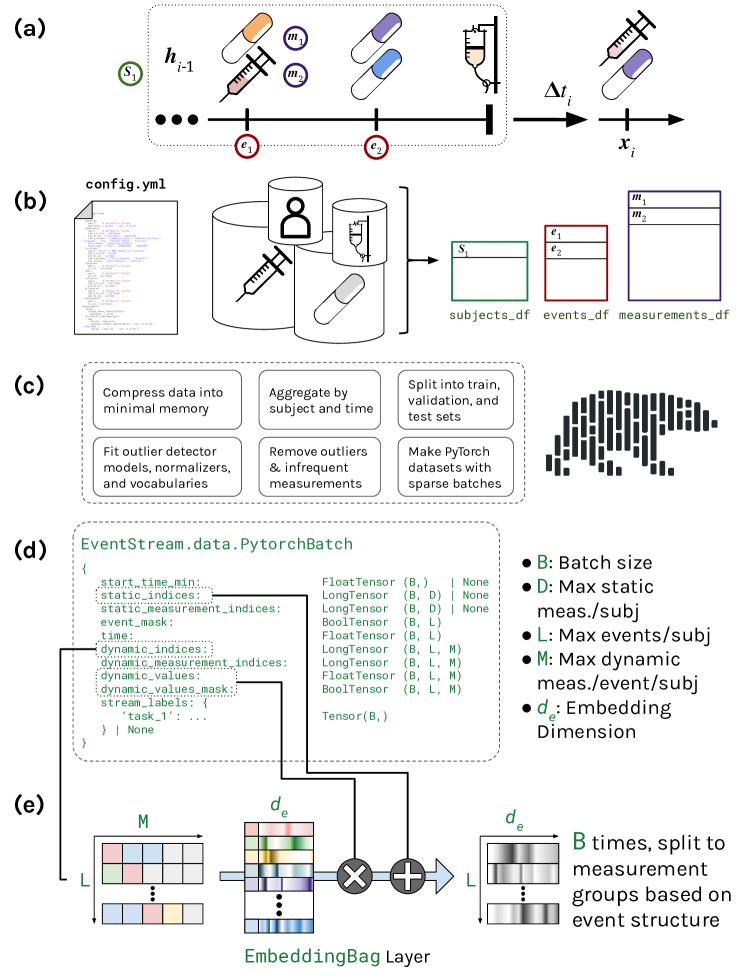
ESGPT は、連続時間・多モーダルなイベントストリーム(例:EHR データ)上で GPT ライクなモデルの構築を可能にするオープンソースライブラリであり、エンドツーエンドのデータ抽出、前処理、効率的なディープラーニング表現、ゼロショット評価サポートを備えた HuggingFace 互換のモデリング API を提供します。
Generative, pre-trained transformers (GPTs, a.k.a. "Foundation Models") have reshaped natural language processing (NLP) through their versatility in diverse downstream tasks. However, their potential extends far beyond NLP. This paper provides a software utility to help realize this potential, extending the applicability of GPTs to continuous-time sequences of complex events with internal dependencies, such as medical record datasets. Despite their potential, the adoption of foundation models in these domains has been hampered by the lack of suitable tools for model construction and evaluation. To bridge this gap, we introduce Event Stream GPT (ESGPT), an open-source library designed to streamline the end-to-end process for building GPTs for continuous-time event sequences. ESGPT allows users to (1) build flexible, foundation-model scale input datasets by specifying only a minimal configuration file, (2) leverage a Hugging Face compatible modeling API for GPTs over this modality that incorporates intra-event causal dependency structures and autoregressive generation capabilities, and (3) evaluate models via standardized processes that can assess few and even zero-shot performance of pre-trained models on user-specified fine-tuning tasks.
研究の動機と目的
- 連続時間・多モーダルイベントストリーム上でGPTのエンドツーエンド構築を可能にする。
- 基盤モデル規模の入力準備のため、最小限の設定で多様で大規模なデータセットを統合する。
- intra-event 依存とオートレグレッシブ生成を考慮したHugging Face互換のモデリングAPIを提供する。
- ユーザー定義タスクに対する少数ショット・ゼロショット評価を含む標準化評価を提供する。
提案手法
- 簡潔な YAML 設定を介して多様なソースからデータを取り込むオープンソース ESGPT ライブラリを提供する。
- Polarsベースの前処理を用いてデータ抽出を高速化し、ストレージ使用量を削減する。
- メモリ効率の良い疎表現と事前構築済み埋め込み層を備えた PyTorch データセットを出力する。
- コンフィギュラブルな依存グラフを介して intra-event 依存を捉える、事前定義済みの2つのモデルアーキテクチャ(ConditionallyIndependent and NestedAttention)を提供する。
- 時間意識の出力と多段生成をサポートする Hugging Face 互換 API を提供し、損失/サンプリングの統一出力オブジェクトを備える。
実験結果
リサーチクエスチョン
- RQ1複雑なイベントの連続時間列に対して、イベント内の依存関係を伴う GPT ライクモデルをいかに効果的に構築できるか。
- RQ2ESGPT は大規模な EHR に似たデータセットに対して、迅速でスケーラブルなデータ前処理とメモリ効率の良い表現を提供できるか。
- RQ3イベントストリームデータで訓練された基盤モデルに対するゼロショット評価は実行可能で有益か。
- RQ4設定可能なイベント内依存グラフは生成性能と下流タスク有用性にどのような影響を与えるか。
主な発見
- ESGPT は大規模なイベントストリームデータセットのエンドツーエンドの前処理、データセット構築、埋め込みを可能にし、速度とストレージ効率が顕著(例:300千人分の MIMIC-IV 全データセットを前処理して1.2 GBにするのに約30分)。
- ライブラリは観測されたイベントに合わせてスケールするメモリ効率の良い疎ディープラーニング表現を提供し、MIMIC-IV の例では従来のアプローチの約1.3%のメモリ使用量に削減。
- 2つのモデルアーキテクチャ(ConditionallyIndependent and NestedAttention)はユーザー定義のイベント内依存を許可し、マルチステージ共変量関係を尊重した生成を可能にする。
- HF互換APIは ESGPT モデルをゼロから構築・訓練・生成することを可能にし、サンプリングと損失のための統一出力オブジェクトを提供する。
- ESGPT はイベントストリームタスクにおける基盤モデルの妥当性を評価するゼロショット評価パイプラインをサポートし、ハイパーパラメータ最適化とモニタリングのツールと共に提供。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。