[論文レビュー] Executable Code Actions Elicit Better LLM Agents
CodeActはLLMエージェントが実行可能なPythonコードをアクションとして出力することを可能にし、Pythonインタープリターと統合してコードの実行・修正・ツール呼び出しの構成を行い、テキスト/JSONアクション形式よりも性能を向上させ、CodeActInstructを用いてLlama2とMistralからファインチューニングされたオープンソースのCodeActAgentを実現します。
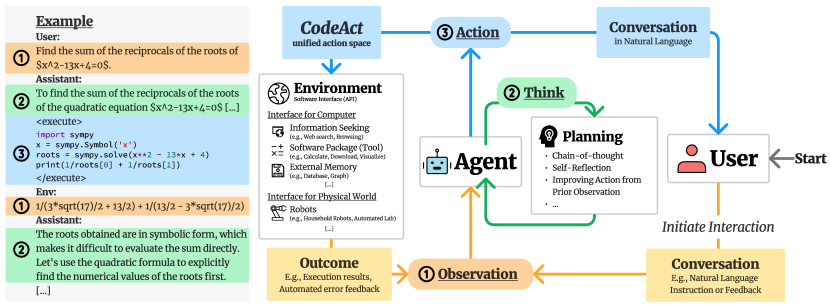
Large Language Model (LLM) agents, capable of performing a broad range of actions, such as invoking tools and controlling robots, show great potential in tackling real-world challenges. LLM agents are typically prompted to produce actions by generating JSON or text in a pre-defined format, which is usually limited by constrained action space (e.g., the scope of pre-defined tools) and restricted flexibility (e.g., inability to compose multiple tools). This work proposes to use executable Python code to consolidate LLM agents' actions into a unified action space (CodeAct). Integrated with a Python interpreter, CodeAct can execute code actions and dynamically revise prior actions or emit new actions upon new observations through multi-turn interactions. Our extensive analysis of 17 LLMs on API-Bank and a newly curated benchmark shows that CodeAct outperforms widely used alternatives (up to 20% higher success rate). The encouraging performance of CodeAct motivates us to build an open-source LLM agent that interacts with environments by executing interpretable code and collaborates with users using natural language. To this end, we collect an instruction-tuning dataset CodeActInstruct that consists of 7k multi-turn interactions using CodeAct. We show that it can be used with existing data to improve models in agent-oriented tasks without compromising their general capability. CodeActAgent, finetuned from Llama2 and Mistral, is integrated with Python interpreter and uniquely tailored to perform sophisticated tasks (e.g., model training) using existing libraries and autonomously self-debug.
研究の動機と目的
- 現実世界のタスクを処理するために、テキスト/JSONを超えたLLMエージェントのアクション空間の拡張を動機づける。
- 実行可能なPythonコード(CodeAct)をPythonインタープリタと統合した統一アクション空間を提案する。
- CodeActの制御・データフロー、再利用性、エラー駆動の自動自己デバッグにおける利点を示す。
- 17モデルに跨るマルチLLM評価での利点を示し、命令チューニングのためのCodeActInstructを導入する。
提案手法
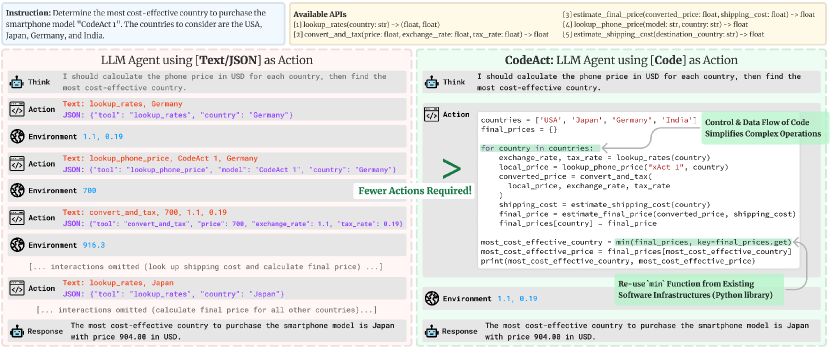
- CodeActを、埋め込みのPythonインタープリターで実行されるPythonコードアクションを出力することとして定義する。
- API-Bankと新しいM3 ToolEvalベンチマークを用いて、原子ツール使用と複雑なマルチツールタスクにおけるCodeActとテキスト/JSONアクションを比較する。
- ツール構成性能を評価するため、82のマルチターン・マルチツールタスクを含むM3 ToolEvalをキュレーションする。
- CodeActInstructを作成し、7kのマルチターントラジェクトリを含めてCodeActAgentを訓練し、対話からの自己改善を研究する。
- CodeActAgent(LLaMA-2およびMistral-7Bのバックボーン)をCodeActInstructと一般的な会話でファインチューニングし、エージェントタスクと一般ベンチマーク全体での性能を評価する。
実験結果
リサーチクエスチョン
- RQ1LLMのコードデータに対する親和性は、原子的なツール使用において、text/JSONよりもCodeActに有利であるか(RQ1)?
- RQ2Pythonの制御とデータフローは、複雑でマルチツールタスクの性能を向上させるか(RQ2)?
- RQ3マルチターンの対話と既存ソフトウェアはCodeActのロバスト性と能力にどう影響するか(RQ3)?
- RQ4CodeActは自己デバッグを伴う高度なタスクを実行するオープンソースLLMエージェントの訓練に用いることができるか(RQ4)?
主な発見
- CodeActは原子的なツール呼び出しの正確さにおいて、text/JSONと同等またはそれ以上を達成し、オープンソースモデルでより大きな向上を示す。
- CodeActは複数ツールを要する複雑なタスクに対してM3 ToolEvalベンチマークで最大20%の絶対的改善をもたらし、アクション数を最大30%削減する。
- CodeActInstruct(7k trajectories)はエージェントの性能を向上させ、CodeActInstructと一般的な会話を混在させても幅広い能力を維持する。
- CodeActAgent(CodeActInstructでファインチューニング) は、MINTとM3 ToolEvalのインドメインおよびアウトオブドメインのエージェントタスクでオープンソースLLMを上回り、テキストアクション形式へ一般化できる。
- CodeActAgentはPythonのエラーメッセージ、ライブラリのインポート、Pandas、Scikit-Learn、Matplotlibなどの外部ツールを活用して自律的に自己デバッグできる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。