[論文レビュー] Execution-based Code Generation using Deep Reinforcement Learning
PPOCoderは、微分不可能な実行フィードバックと構造ベースの報酬を用いた近接方策最適化(PPO)により、事前学習済みコードモデルをファインチューニングして、タスクと言語を越えたコンパイル可能性と機能的正確性を向上させる。
The utilization of programming language (PL) models, pre-trained on large-scale code corpora, as a means of automating software engineering processes has demonstrated considerable potential in streamlining various code generation tasks such as code completion, code translation, and program synthesis. However, current approaches mainly rely on supervised fine-tuning objectives borrowed from text generation, neglecting unique sequence-level characteristics of code, including but not limited to compilability as well as syntactic and functional correctness. To address this limitation, we propose PPOCoder, a new framework for code generation that synergistically combines pre-trained PL models with Proximal Policy Optimization (PPO) which is a widely used deep reinforcement learning technique. By utilizing non-differentiable feedback from code execution and structure alignment, PPOCoder seamlessly integrates external code-specific knowledge into the model optimization process. It's important to note that PPOCoder is a task-agnostic and model-agnostic framework that can be used across different code generation tasks and PLs. Extensive experiments on three code generation tasks demonstrate the effectiveness of our proposed approach compared to SOTA methods, achieving significant improvements in compilation success rates and functional correctness across different PLs.
研究の動機と目的
- トークンレベルの目的だけでなく、実行と構造的正確性を組み込んでコード生成を改善する動機付け。
- 非微分可能な実行フィードバックを活用するタスク依存性・モデル非依存性のRLフレームワーク(PPOCoder)の提案。
- コンパイラ信号、ASTベースの統語マッチング、DFGベースの意味論的マッチングをKL正則化されたPPO目的に統合。
- コード補完、翻訳、NLからコードへのタスクでのコンパイル率と機能的正確性の向上を実証。
提案手法
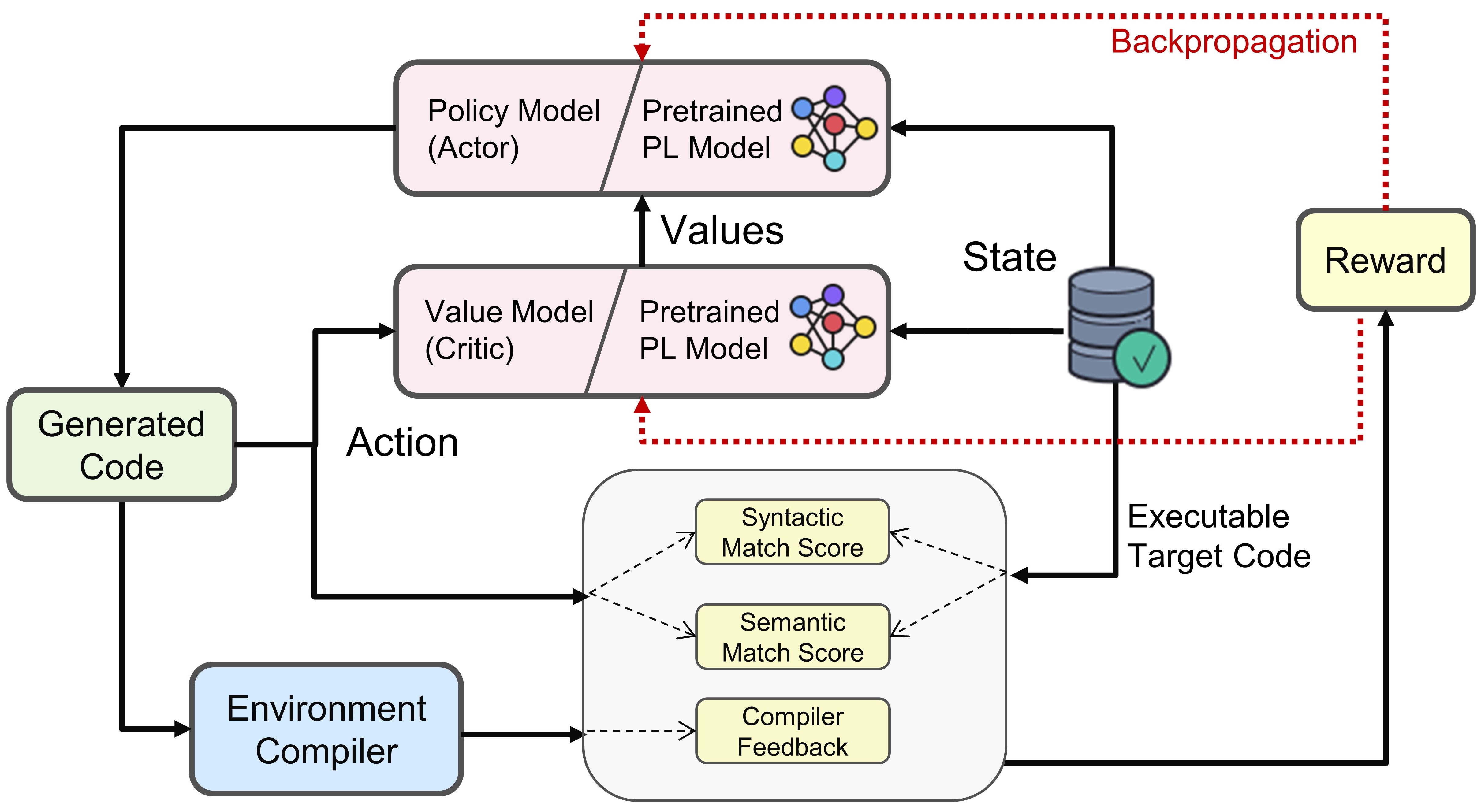
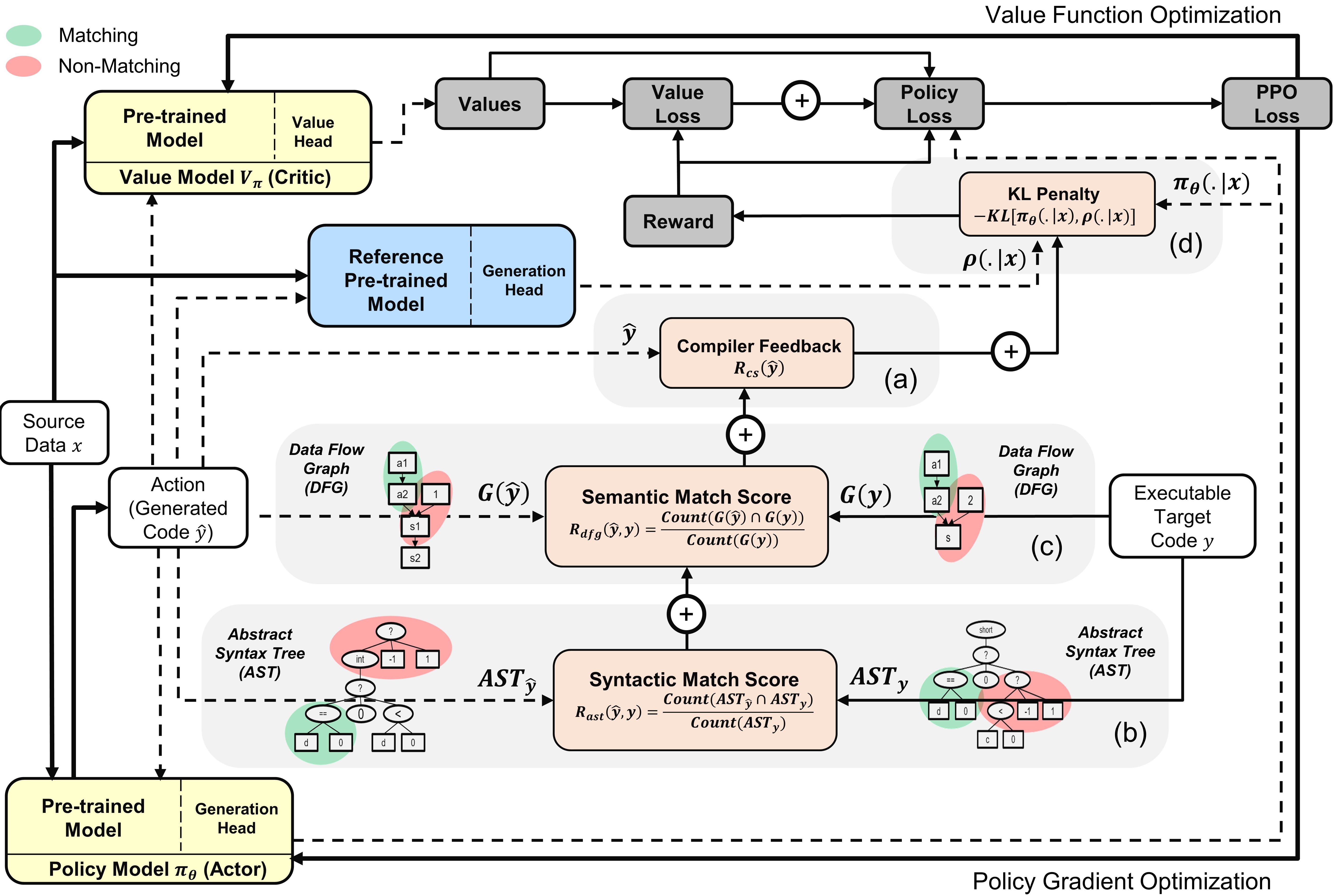
- 対象タスクのために事前学習済みコードモデルからアクター/クリティックを初期化。
- 現在のポリシーからコードをサンプルし、コンパイラフィードバック、ASTマッチ、DFGマッチ、およびKL発散ペナルティを含む終端報酬を計算。
- CPI代替目的と値ヘッドを用いて安定かつ最小偏差の更新を保証するPPOで最適化。
- 報酬要素には、コンパイラ信号(ユニットテストまたは構文正確性)、ASTベースの構文一致、DFGベースの意味論的一致、KLペナルティを含む。
- KL発散項とクリップベースのPPO更新によって探索/活用バランスを促進。
実験結果
リサーチクエスチョン
- RQ1PPOベースのファインチューニングが非微分可能な実行フィードバックとともに、複数のプログラミング言語でのコンパイル可能性と機能的正確性を向上させるか。
- RQ2コンパイラ信号、AST構造的マッチング、DFG意味論的マッチングがコード生成品質にどう寄与するか。
- RQ3このアプローチはタスク(コード補完、コード翻訳、NL→コード)とプログラミング言語を跨いで堅牢か。
- RQ4KL発散ペナルティの導入は memorizationを抑制し、一般化を改善するか。
主な発見
| Model | xMatch | Edit Sim | Comp Rate |
|---|---|---|---|
| BiLSTM | 20.74 | 55.32 | 36.34 |
| Transformer | 38.91 | 61.47 | 40.22 |
| GPT-2 | 40.13 | 63.02 | 43.26 |
| CodeGPT | 41.98 | 64.47 | 46.84 |
| CodeT5 (220M) | 42.61 | 68.54 | 52.14 |
| PPOCoder + CodeT5 (220M) | 42.63 | 69.22 | 97.68 |
- PPOCoder + CodeT5はコード補完でのコンパイル率を52.14%から97.68%へ向上。
- PPOCoder + CodeT5はCodeT5単体と比較してxMatchが競争力のある42.63、Edit Similarityが69.22と高くなった(42.61, 68.54)。
- XLCoSTコード翻訳では、PPOCoder + CodeT5が言語間で高いコンパイル率を示し、PythonやJavaで顕著な向上と競争力のあるCodeBLEUスコアを達成。
- このフレームワークは6つのターゲット言語(C++, Java, Python, C#, PHP, C)全体でコンパイル率を改善し、CodeBLEUスコアに表れた意味的整合性を維持。
- アブレーション研究は、報酬構成要素(コンパイラ信号、AST/DFGマッチ、KLペナルティ)が性能向上と安定した学習に寄与することを示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。