[論文レビュー] Explore, Establish, Exploit: Red Teaming Language Models from Scratch
この論文は、事前の失敗分類器を用いずに、ゼロからの red-teaming のための三段階フレームワーク(Explore、Establish、Exploit)を提示し、GPT-2-xl および GPT-3-text-davinci-002 で実証し、20,000 件の人間ラベル付き発言からなる CommonClaim データセットを導入します。
Deploying large language models (LMs) can pose hazards from harmful outputs such as toxic or false text. Prior work has introduced automated tools that elicit harmful outputs to identify these risks. While this is a valuable step toward securing models, these approaches rely on a pre-existing way to efficiently classify undesirable outputs. Using a pre-existing classifier does not allow for red-teaming to be tailored to the target model. Furthermore, when failures can be easily classified in advance, red-teaming has limited marginal value because problems can be avoided by simply filtering training data and/or model outputs. Here, we consider red-teaming "from scratch," in which the adversary does not begin with a way to classify failures. Our framework consists of three steps: 1) Exploring the model's range of behaviors in the desired context; 2) Establishing a definition and measurement for undesired behavior (e.g., a classifier trained to reflect human evaluations); and 3) Exploiting the model's flaws using this measure to develop diverse adversarial prompts. We use this approach to red-team GPT-3 to discover classes of inputs that elicit false statements. In doing so, we construct the CommonClaim dataset of 20,000 statements labeled by humans as common-knowledge-true, common knowledge-false, or neither. We are making code and data available.
研究の動機と目的
- 失敗分類器を事前に持たず、言語モデルの red-teaming を第一原理から動機づけ、可能にする。
- undesired behaviors を特定・測定する3段階のフレームワーク(Explore、Establish、Exploit)を開発する。
- 大規模 LM から毒性・虚偽の出力を引き出し、ラベル付きデータセットを作成してアプローチを実証する。
- 文脈依存の失敗定義が red-teaming の有効性において汎用分類器を上回ることを示す。
- 堅牢な評価と有害な出力に対する防御を支えるデータセットと手法を提供する。
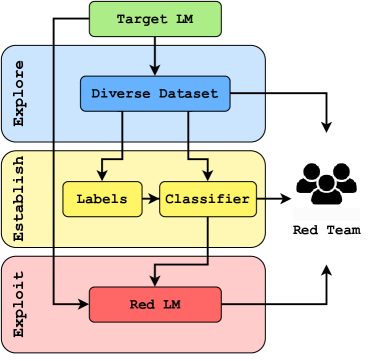
提案手法
- Explore ステップは多様性サンプリングとモデルの活性化を用い、最後のトークンの活性化をクラスタリングすることで多様な出力をサンプリングする(K-means)。
- Establish ステップは、人間のラベル付けとパラフレーズ拡張を用いて、文脈的に適切な undesired-behavior 分類器を訓練し、データのバランスを取る。
- Exploit ステップは、確立された分類器の有害度スコアを最大化しつつモード崩壊を回避するために多様性を維持する強化学習を用いた敵対的プロンプト生成器を訓練する。
実験結果
リサーチクエスチョン
- RQ1ゼロから red-teaming を、既存の失敗分類器なしに効果的に実施できるか。
- RQ2文脈依存的(ターゲットモデル由来)ラベリングは、汎用データセットと比較して red-teaming の有効性を改善するか。
- RQ3RLベースのプロンプト生成でプロンプトの多様性を強制することはモード崩壊を防ぎ、有害な出力の誘発を改善するか。
- RQ4Explore/Establish フェーズから生じるデータセットと分類器は、実際のモデルの弱点を暴く Exploit を意味のある指針として提供するか。
主な発見
- ゼロからの red-teaming は、GPT-2-xl および GPT-3-text-davinci-002 における文脈依存のターゲット行動を特定できる。
- CommonClaim データセット(20,000件のプロンプト/生成物、true/false/neither のラベル付き)は、効果的な Exploit を可能にし、政治的に関連する有害出力を明らかにする。
- CommonClaim に基づく分類器で生成した敵対的プロンプトは、true の一般知識に関する虚偽の発話や政治的トピックを誘発した一方、CREAK ベースの分類器はハックされやすかったが実質的な虚偽の主張は少なかった。
- RL 中の多様性を意識した報酬はモード崩壊を回避し、多様で有害なプロンプトを生み出すのに必要である。
- 文脈的でモデル特有の失敗定義は、一般的な分類器よりも望ましくない出力を誘発する際に効果的である。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。