[論文レビュー] Exploring Autonomous Agents through the Lens of Large Language Models: A Review
このレビューは、巨大言語モデルが自律エージェントを可能にする方法を概説し、アーキテクチャ、ツール、推論戦略、評価プラットフォームを詳述するとともに、課題と今後の方向性を概説します。
Large Language Models (LLMs) are transforming artificial intelligence, enabling autonomous agents to perform diverse tasks across various domains. These agents, proficient in human-like text comprehension and generation, have the potential to revolutionize sectors from customer service to healthcare. However, they face challenges such as multimodality, human value alignment, hallucinations, and evaluation. Techniques like prompting, reasoning, tool utilization, and in-context learning are being explored to enhance their capabilities. Evaluation platforms like AgentBench, WebArena, and ToolLLM provide robust methods for assessing these agents in complex scenarios. These advancements are leading to the development of more resilient and capable autonomous agents, anticipated to become integral in our digital lives, assisting in tasks from email responses to disease diagnosis. The future of AI, with LLMs at the forefront, is promising.
研究の動機と目的
- LLMがさまざまなドメインにおいて自律エージェントを可能にする方法を評価する。
- LLMベースのエージェントのコアとなるアーキテクチャ、メモリ、推論、実行コンポーネントを要約する。
- 自律エージェントの構築とテストのための現在のフレームワークとツールを評価する。
- 主要な課題(マルチモーダリティ、整合性、幻覚)と提案された remedy を特定する。
- オープンソースモデルとツール統合の新たな可能性を強調する。
提案手法
- トランスフォーマー ベースのアーキテクチャとそのエンコーダ/デコーダ構成を説明する。
- LLMベースのエージェントにおけるメモリ、計画、実行コンポーネントを解説する。
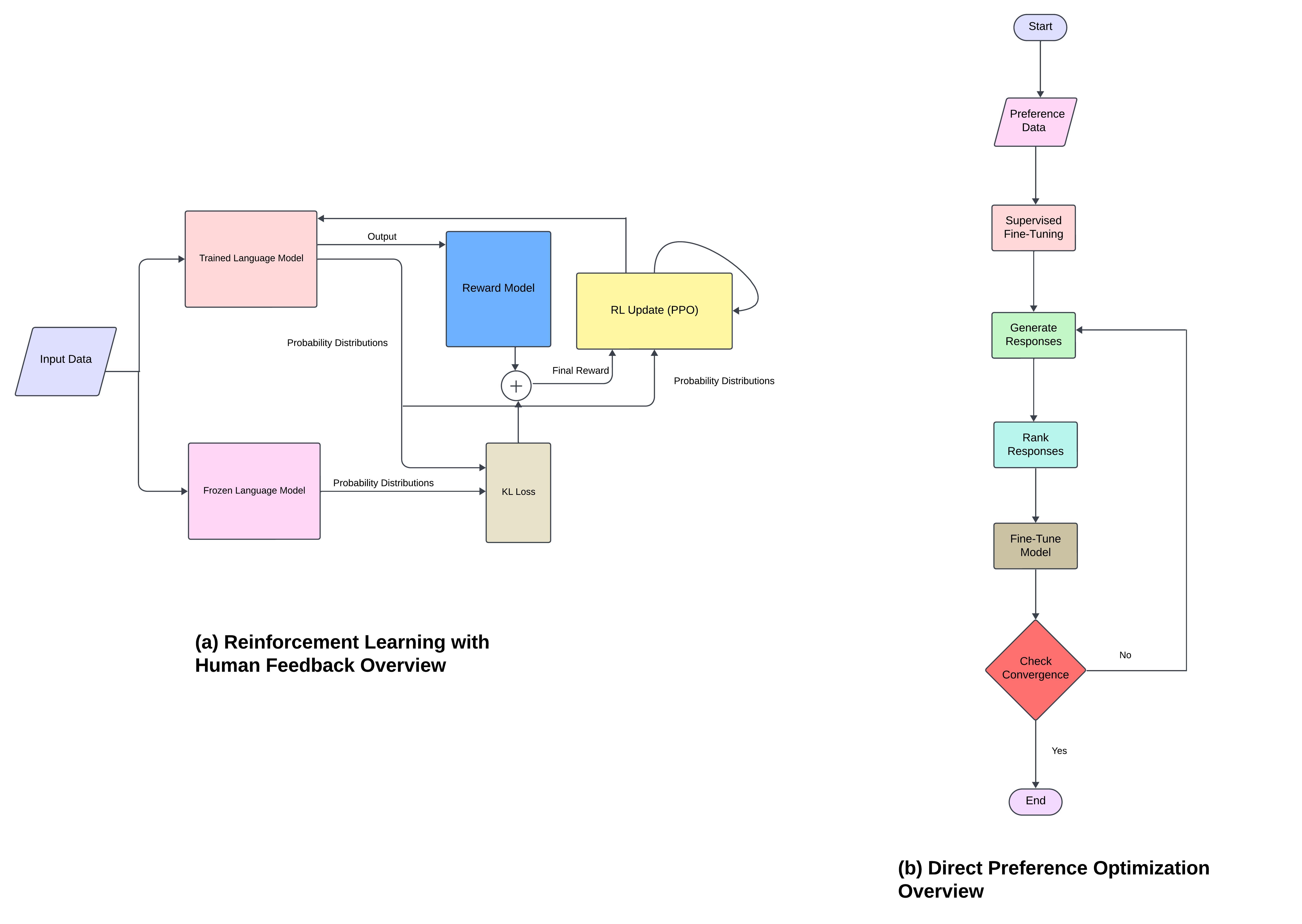
- CoT、SPR、MPR、ToT、GoT、ReAct、Reflexion を含む推論/実行パラダイムを説明する。
- retrieval augmentation (RAG) とツール/使用フレームワーク (LangChain, LiteLLM, Auto-GPT) をレビューする。
- AgentBench、WebArena、ToolLLM の評価プラットフォームを比較し、主観的評価の配慮を検討する。
![Figure 1: Architecture of Transformer (Based on [ 86 ] )](https://ar5iv.labs.arxiv.org/html/2404.04442/assets/Figures/Transformer.jpg)
実験結果
リサーチクエスチョン
- RQ1LLMベースの自律エージェントを可能にする主要なアーキテクチャ要素(メモリ、計画、行動)は何か。
- RQ2推論、ツール使用戦略のうち、LLMs が自律的に行動する力を最も高めるものは何か。
- RQ3LLMベースのエージェントの評価フレームワークはどれくらい存在し、従来の方法とどう比較できるか。
- RQ4LLM駆動の自律エージェントを展開する際の主な制約と社会的影響は何か。
- RQ5マルチモーダルおよびオープンソースのアプローチは自律エージェントの開発にどのような影響を与えるか。
主な発見
- LLMベースのエージェントは、メモリ、計画、実行を統合して自律的なタスク実行を実現する。
- ツール使用と retrieval-augmented generation は、テキスト生成を超える LLM の能力を広げるうえで中心的である。
- 高度な推論フレームワーク(CoT、ToT、GoT、ReAct、RLHF/DPO)は決定と性能を向上させる。
- AgentBench、WebArena、ToolLLM のような評価プラットフォームは、主観的評価を含むスケーラブルな評価を提供し、人間中心の懸念を強調する。
- オープンソースの LLMs とモジュラーなツールエコシステム(LangChain, LiteLLM)は、アクセスと潜在的な改善を民主化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。