[論文レビュー] Exploring Parameter-Efficient Fine-Tuning Techniques for Code Generation with Large Language Models
この論文は PEFT 技術(LoRA、IA3、Prompt tuning、Prefix tuning)を Python コード生成に対して LLMs で評価し、リソース制約の下で ICL および完全ファインチューニングと比較し、結合訓練と量子化(QLoRA)を検討してメモリ使用量を削減する。
Large language models (LLMs) demonstrate impressive capabilities to generate accurate code snippets given natural language intents in a zero-shot manner, i.e., without the need for specific fine-tuning. While prior studies have highlighted the advantages of fine-tuning LLMs, this process incurs high computational costs, making it impractical in resource-scarce environments, particularly for models with billions of parameters. To address these challenges, previous research explored in-context learning (ICL) and retrieval-augmented generation (RAG) as strategies to guide the LLM generative process with task-specific prompt examples. However, ICL and RAG introduce inconveniences, such as the need for designing contextually relevant prompts and the absence of learning task-specific parameters, thereby limiting downstream task performance. In this context, we foresee parameter-efficient fine-tuning (PEFT) as a promising approach to efficiently specialize LLMs to task-specific data while maintaining reasonable resource consumption. In this paper, we deliver a comprehensive study of PEFT techniques for LLMs in the context of automated code generation. Our comprehensive investigation of PEFT techniques for LLMs reveals their superiority and potential over ICL and RAG across a diverse set of LLMs and three representative Python code generation datasets: Conala, CodeAlpacaPy, and APPS. Furthermore, our study highlights the potential for tuning larger LLMs and significant reductions in memory usage by combining PEFT with quantization. Therefore, this study opens opportunities for broader applications of PEFT in software engineering scenarios. Our code is available at https://github.com/martin-wey/peft-llm-code/.
研究の動機と目的
- PEFT で調整した LLM が Python コード生成で、小さなモデルを完全にファインチューニングした場合や PEFT ありの場合と比較してどうなるかを評価する。
- PEFT 手法が LLM のコード関連タスクで ICL を上回るかを評価する。
- LoRA の効果を、2つのデータセットを共同でファインチューニングする場合に探る。
- LoRA と量子化を組み合わせてリソースをさらに削減し、大規模モデルのファインチューニングを検討する。
提案手法
- 4つの PEFT 技術(LoRA、IA3、Prompt tuning、Prefix tuning)を、CodeT5+、CodeGen、CodeGen2、CodeLlama の複数のモデルファミリーと、8つの大規模モデルと3つの小型モデルを横断して比較する。
- 2つの Python コード生成データセット(CoNaLa、CodeAlpacaPy)で評価し、HumanEval バイアスを回避する。
- 24 GB の GPU 制約の下で、ICL および小型モデルの完全ファインチューニングと比較する。
- 2つのデータセットを jointly に訓練した単一 LoRA アダプターを、データセット別のアダプターと比較する。
- メモリフットプリントを削減し、リソースが限られた状況で最大 34B パラメータの大規模モデルのファインチューニングを可能にする QLoRA を検討する。)
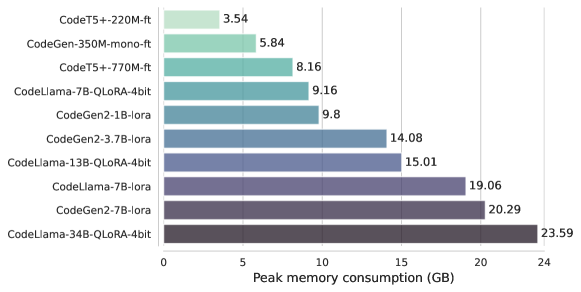
実験結果
リサーチクエスチョン
- RQ1RQ1: 24 GB の GPU メモリの下で、PEFT 調整済み LLM は小型モデルの完全ファインチューニングおよび PEFT と比較してコード生成にどう影響されるか。
- RQ2RQ2: コードタスクにおいて PEFT 技術は ICL より有望か。
- RQ3RQ3: 両データセットを共同でファインチューニングする場合、LoRA の性能はどう変わるか。
- RQ4RQ4: LoRA と量子化を組み合わせて、より大きなモデルのリソース使用をさらに削減できるか。
主な発見
- LoRA-、IA3-、Prompt-tuning 調整済み LLM(数百万の学習可能パラメータ)を持つモデルが、数億のパラメータを持つ小型モデルを完全にファインチューニングした場合よりも高い性能を発揮する。
- LoRA は一般に PEFT 手法の中で最高の有効性を示し、小型モデルの完全ファインチューニングを上回ることがある。
- LoRA は CoNaLa および CodeAlpacaPy の両方のデータセットに対して ICL と比較して、すべてのモデルで性能を大幅に改善する。
- 単一の LoRA アダプターを両データセットで jointly 学習すると、データセット特異の LoRA アダプターと同程度の効果を得られる。
- QLoRA はメモリ使用量を大幅に削減し、LoRA の約半分のメモリでファインチューニングを可能にし、24 GB 未満の環境で CodeLlama-34B までのチューニングをサポートする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。