[論文レビュー] Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models
本研究は、一般的な評価指標(特に Inception-based FID)と人間の判断との整合性が乏しく、拡散モデルを不公平に低く評価していることを示し、より良い評価のための DINOv2-based 表現を提案し、 memorization の問題を強調します。
We systematically study a wide variety of generative models spanning semantically-diverse image datasets to understand and improve the feature extractors and metrics used to evaluate them. Using best practices in psychophysics, we measure human perception of image realism for generated samples by conducting the largest experiment evaluating generative models to date, and find that no existing metric strongly correlates with human evaluations. Comparing to 17 modern metrics for evaluating the overall performance, fidelity, diversity, rarity, and memorization of generative models, we find that the state-of-the-art perceptual realism of diffusion models as judged by humans is not reflected in commonly reported metrics such as FID. This discrepancy is not explained by diversity in generated samples, though one cause is over-reliance on Inception-V3. We address these flaws through a study of alternative self-supervised feature extractors, find that the semantic information encoded by individual networks strongly depends on their training procedure, and show that DINOv2-ViT-L/14 allows for much richer evaluation of generative models. Next, we investigate data memorization, and find that generative models do memorize training examples on simple, smaller datasets like CIFAR10, but not necessarily on more complex datasets like ImageNet. However, our experiments show that current metrics do not properly detect memorization: none in the literature is able to separate memorization from other phenomena such as underfitting or mode shrinkage. To facilitate further development of generative models and their evaluation we release all generated image datasets, human evaluation data, and a modular library to compute 17 common metrics for 9 different encoders at https://github.com/layer6ai-labs/dgm-eval.
研究の動機と目的
- 現在の生成モデル評価指標が、多様なデータセットにおける現実感の人間の知覚とどれだけ一致しているかを評価する。
- エンコーダの選択(Inception 対 SSL-based)が指標の信頼性にどのように影響するかを評価する。
- 多様性、希少性、 memorization を別個の評価軸として調査する。
- データセット、人間評価データ、および 9 つのエンコーダに対して 17 指標を計算するモジュール式ツールキットを提供し、より良い評価実践を支援する。
提案手法
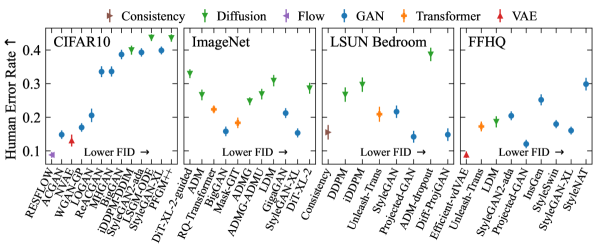
- CIFAR10, ImageNet1k, FFHQ, LSUN-Bedroom の 41 モデルを対象に大規模な人間評価を実施し、現実感を測定する。
- モデルごとに 100k 枚の画像を生成して評価データセットを形成する。
- Inception-V3、ConvNeXt、および seven SSL models (SimCLRv2, DINOv2, SwAV, MAE, data2vec, CLIP OpenCLIP, DreamSim) を含む 9 種類のエンコーダを用いて 17 指標を評価する。
- 指標スコアを人間が評価した現実感と比較して相関と信頼性を評価する。
- 指標の挙動の乖離を説明するために、多様性(Vendi score)、希少性、 memorization(ピクセル単位および再構成可能性)を分析する。
- 生成データセット、人間データ、および 17 指標を備えたモジュール式 dgm-eval ライブラリを公開する。
実験結果
リサーチクエスチョン
- RQ1現在の生成モデル評価指標は、多様なデータセットにおける現実感に対する人間の判断と相関しているか。
- RQ2異なるエンコーダ(Inception 対 SSL-based)は FID や FD の信頼性にどのように影響するか。
- RQ3Inception-based 指標が GAN に比べて拡散モデルを不公正に低く評価しているか、また SSL-based 指標がこれを解決できるか。
- RQ4 memorization、多様性、希少性は、人間の判断と指標との乖離をどの程度説明できるか。
主な発見
- 既存の指標がデータセット全体で人間の評価者と強い相関を示すものはない。
- 拡散モデルは人間が評価した現実感ではGANを上回るが、FID のような Inception-based 指標では低評価される。
- Inception-V3 を DINOv2-ViT-L/14 に置換すると、指標と人間の判断の整合性が改善され、評価がより豊かになる。
- memorization は CIFAR10 で明示的に観測されるが、ImageNet/FFHQ/LSUN では明確ではなく、現行の memorization 指標はそれを確実に検出できない。
- DINOv2-based FD スコアは人間の判断との相関が高く、クラスごとに Vendi を用いて多様性をよりよく捉えることで、評価能力が向上していることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。