[論文レビュー] Extract, Define, Canonicalize: An LLM-based Framework for Knowledge Graph Construction
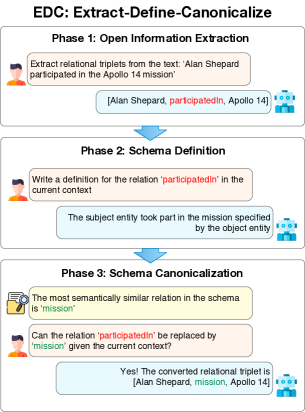
EDCは、knowledge graph構築のための三相のLLM駆動フレームワークで、Open Information Extractionで開き、次にスキーマを定義し、最後にトリプレットを事前定義されたスキーマへまたは自己生成されたスキーマへ正準化します。これは retrieval-augmented schema retriever によって強化されます。
In this work, we are interested in automated methods for knowledge graph creation (KGC) from input text. Progress on large language models (LLMs) has prompted a series of recent works applying them to KGC, e.g., via zero/few-shot prompting. Despite successes on small domain-specific datasets, these models face difficulties scaling up to text common in many real-world applications. A principal issue is that, in prior methods, the KG schema has to be included in the LLM prompt to generate valid triplets; larger and more complex schemas easily exceed the LLMs' context window length. Furthermore, there are scenarios where a fixed pre-defined schema is not available and we would like the method to construct a high-quality KG with a succinct self-generated schema. To address these problems, we propose a three-phase framework named Extract-Define-Canonicalize (EDC): open information extraction followed by schema definition and post-hoc canonicalization. EDC is flexible in that it can be applied to settings where a pre-defined target schema is available and when it is not; in the latter case, it constructs a schema automatically and applies self-canonicalization. To further improve performance, we introduce a trained component that retrieves schema elements relevant to the input text; this improves the LLMs' extraction performance in a retrieval-augmented generation-like manner. We demonstrate on three KGC benchmarks that EDC is able to extract high-quality triplets without any parameter tuning and with significantly larger schemas compared to prior works. Code for EDC is available at https://github.com/clear-nus/edc.
研究の動機と目的
- 一般テキストから小さな事前定義スキーマに頼らず、LLMsを用いて自動的なknowledge graph construction(KGC)を動機づける。
- プロンプトのコンテキストウィンドウ制約を減らすため、KGCをOpen Information Extraction、Schema Definition、Schema Canonicalizationの3つのフェーズに分解する。
- Target Alignment(事前定義済みの大規模スキーマ)とSelf Canonicalization(自動スキーマ作成)の設定の両方を有効にする。
- 入力テキストに関連するスキーマ要素を検索する訓練済みSchema Retrieverを導入して、抽出品質を向上させる。
- 抽出フェーズでパラメータ調整なし、3つのベンチマークでEDCおよびEDC+Rを実証し、有利な結果を示す。
提案手法
- Three-phase EDC framework: (i) Open Information Extraction でスキーマ制約なしにトリプレットを生成、(ii) Schema Definition で誘導されたスキーマ要素の自然言語定義を生成、(iii) Schema Canonicalization でトリプレットを Target Alignment または Self Canonicalization を通じて正準形へマッピング。
- LLMsを用いて説明を通じて抽出を正当化し、正準化に用いる定義を導出する。
- 正準化を、埋め込みスキーマ定義のベクトル類似度検索として表現し、その後、実現可能な変換のLLMベース検証を行う。
- Refinement (EDC+R) は抽出時に retrieval-augmented ヒントを追加し、前回の反復からの候補エンティティ/リレーションを統合し、OIEを誘導する訓練済みSchema Retrieverを用いる。
- Schema Retriever は text-definition relation ペアで訓練された fine-tuned E5-mistral-7b-instruct モデルで、テキストとスキーマを共通のベクトル空間に射影して関連性スコアを算出する。
- Iterate refinement up to one additional pass, leveraging hints to improve extraction quality.
実験結果
リサーチクエスチョン
- RQ1事前に定義された小さなスキーマを持たずに、LLMベースの3相パイプラインは高品質なKGCを生み出せるだろうか?
- RQ2既存スキーマへの整列と自己生成スキーマとの対比において、事後正準化はトリプレットの品質と冗長性にどのような影響を与えるか?
- RQ3retrieval-augmented schema retriever は、大規模または進化するスキーマを持つデータセット全体で抽出性能を向上させるか?
- RQ4大規模スキーマタイプを持つ実世界のKGC における Target Alignment と Self Canonicalization のトレードオフは何か?
主な発見
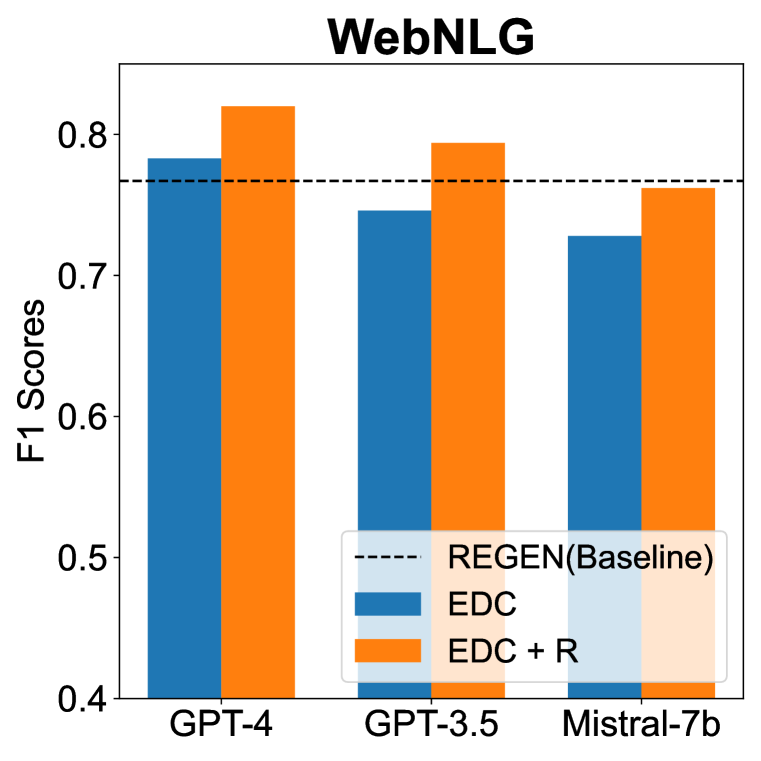
- EDCは、Target AlignmentとSelf Canonicalizationの分野で、3つのKGCベンチマークにおいて、パラメータ調整なしで最先端のベースラインを上回る。
- 単一のリファインメント反復(EDC+R)は、テストした全LLMで一貫して性能を向上させる。
- Schema Retrieverは性能を著しく向上させ、OIE段階で見逃されがちなより細粒度のリレーション(例えば campus と location など)を可能にする。
- Self Canonicalizationは、人間の評価においてCESIベースラインと比較して、簡潔で冗長性の低いスキーマと高い精度をもたらす。
- 実用的評価は、オープンKGトリプレットが正しいことを示す一方、網羅的なリファレンスセットに比べて過度に拡張されている可能性があり、データセットのアノテーションの差を浮き彫りにしている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。