[論文レビュー] Facial Affect Recognition based on Transformer Encoder and Audiovisual Fusion for the ABAW5 Challenge
論文は、Affine Moduleを用いて音声と映像特徴を融合するTransformer Encoderベースのマルチモーダルフレームワークを提案し、4つのABAW5サブチャレンジすべてにおいて最先端のVA、Expr、AU、ERIタスクの性能を達成します。
In this paper, we present our solutions for the 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW), which includes four sub-challenges of Valence-Arousal (VA) Estimation, Expression (Expr) Classification, Action Unit (AU) Detection and Emotional Reaction Intensity (ERI) Estimation. The 5th ABAW competition focuses on facial affect recognition utilizing different modalities and datasets. In our work, we extract powerful audio and visual features using a large number of sota models. These features are fused by Transformer Encoder and TEMMA. Besides, to avoid the possible impact of large dimensional differences between various features, we design an Affine Module to align different features to the same dimension. Extensive experiments demonstrate that the superiority of the proposed method. For the VA Estimation sub-challenge, our method obtains the mean Concordance Correlation Coefficient (CCC) of 0.6066. For the Expression Classification sub-challenge, the average F1 Score is 0.4055. For the AU Detection sub-challenge, the average F1 Score is 0.5296. For the Emotional Reaction Intensity Estimation sub-challenge, the average pearson's correlations coefficient on the validation set is 0.3968. All of the results of four sub-challenges outperform the baseline with a large margin.
研究の動機と目的
- 多様なタスク (VA, Expr, AU, ERI) における野外状況下での頑健な表情感情認識を動機付ける。
- sotaモデルから得られる多様な音声・映像特徴を活用して性能を改善する。
- 融合前の異種特徴次元を合わせるAffine Moduleを導入する。
- Transformer Encoder(ERIにはTEMMAも使用)を適用して時系列ダイナミクスをモデル化する。
- 4つのABAW5サブチャレンジすべてにおいて-baselinesを上回る性能を示す。
提案手法
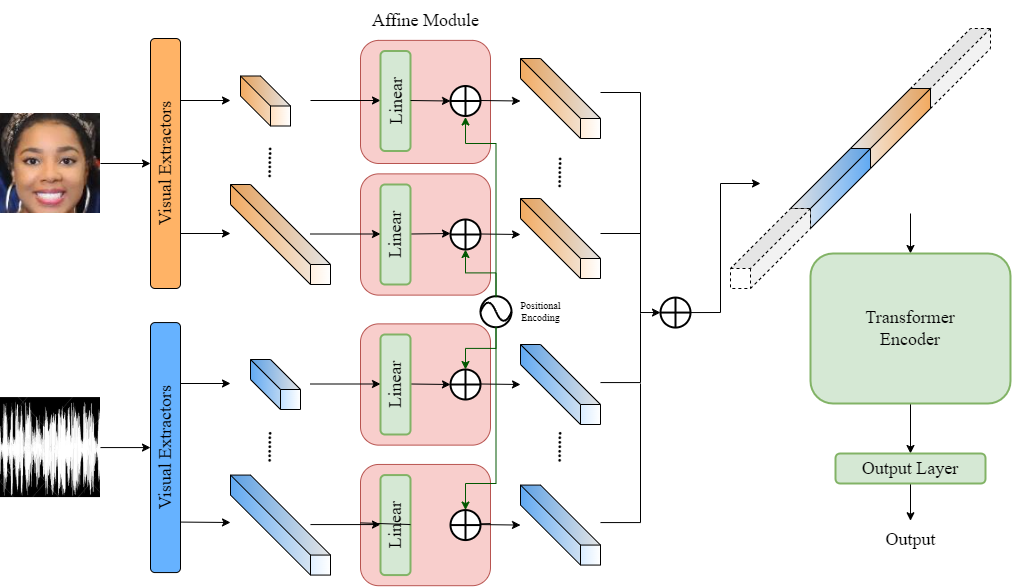
- 複数の音声エンコーダー(IS09, VGGish, eGeMAPS, DeepSpectrum, CNN14)を用いて音声特徴を抽出する。
- 複数のアーキテクチャ(EAC, ResNet18, POSTER, POSTER2, FAU, OPENFace FAU)から映像特徴を抽出する。
- Affine Moduleで異種特徴次元を揃え、位置エンコーディングを追加する。
- Affine整列特徴を連結し、Transformer Encoder(ERIにはTEMMA)で時系列関係をモデリングする。
- タスク固有の出力層で予測をデコードし、タスク適合の損失関数(VA/ERIはMSE、ExprはCE、AUは加重非対称損失)で最適化する。
- 視覚抽出器をRAF-DBとAffectNetで事前学習し、ABAW5データセット(Aff-Wild2バリアントとHume-Reaction)で学習・評価する。
実験結果
リサーチクエスチョン
- RQ1Transformerベースのエンコーダを介して統合した音声-映像特徴は、ABAW5のすべてのサブチャレンジの性能向上につながるか。
- RQ2Affine Moduleによる異種特徴次元の整列がフュージョンの有効性に与える影響は。
- RQ3TEMMAベースの時系列モデリングは、標準のTransformerエンコーダと比較してERI推定に利得があるか。
- RQ4VA、Expr、AU、ERIのタスクで最良の検証性能を生む特徴の組み合わせは何か。
主な発見
| Features | VA | 覚醒度 | 平均 |
|---|---|---|---|
| ベースライン | 0.24 | 0.20 | 0.22 |
| EAC | 0.4479 | 0.5878 | 0.5179 |
| POSTER | 0.3920 | 0.6317 | 0.5119 |
| ResNet18 | 0.4762 | 0.5671 | 0.5217 |
| POSTER2 | 0.5374 | 0.6297 | 0.5836 |
| ResNet18+VGGish | 0.4742 | 0.6220 | 0.5481 |
| ResNet18+POSTER2 | 0.5515 | 0.6429 | 0.5972 |
| ResNet18+POSTER2+FAU | 0.4868 | 0.6301 | 0.5585 |
| POSTER2+POSTER+VGGish | 0.5003 | 0.6946 | 0.5975 |
| EAC+ResNet18+POSTER2+VGGish | 0.5542 | 0.6590 | 0.6066 |
- VA推定では、最良の単一特徴はPOSTER2(Mean=0.5836)であり、最良の複数特徴組み合わせはResNet18+POSTER2+FAU(Mean=0.5585)、全体で最良のMean 0.6066はEAC, ResNet18, POSTER2, and VGGishの組み合わせ時。
- VAの検証平均 CCCは0.6066で、ベースラインを大幅に上回る強力な改善を示す。
- Expr分類はPOSTER2単独で最高のF1スコア(0.4055)を達成し、ResNet18とPOSTER2の組み合わせで0.3957–0.4055の範囲で改善。
- AU検出はPOSTER2とFAU特徴でF1スコアが高く(0.5296)、マルチモーダルフュージョンが有効であることを示す。
- ERI推定はResNet18とDeepSpectrumを組み合わせたとき最良の PCC(0.3968)を示し、音声・映像手が補完的であることを示唆。
- ABAW5全体で4サブチャレンジすべてがベースラインを大幅に上回る。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。