[論文レビュー] Fairness-guided Few-shot Prompting for Large Language Models
この論文は、プロンプトを評価する予測バイアス(フェアネス)指標を導入し、LLMsのコンテキスト内学習を改善するための T-fair-Prompting および G-fair-Prompting の二つのプロンプト探索戦略を提案します。
Large language models have demonstrated surprising ability to perform in-context learning, i.e., these models can be directly applied to solve numerous downstream tasks by conditioning on a prompt constructed by a few input-output examples. However, prior research has shown that in-context learning can suffer from high instability due to variations in training examples, example order, and prompt formats. Therefore, the construction of an appropriate prompt is essential for improving the performance of in-context learning. In this paper, we revisit this problem from the view of predictive bias. Specifically, we introduce a metric to evaluate the predictive bias of a fixed prompt against labels or a given attributes. Then we empirically show that prompts with higher bias always lead to unsatisfactory predictive quality. Based on this observation, we propose a novel search strategy based on the greedy search to identify the near-optimal prompt for improving the performance of in-context learning. We perform comprehensive experiments with state-of-the-art mainstream models such as GPT-3 on various downstream tasks. Our results indicate that our method can enhance the model's in-context learning performance in an effective and interpretable manner.
研究の動機と目的
- LLMsにおけるプロンプト誘発の予測バイアスに対処することにより、コンテキスト内学習(ICL)の改善を動機づける。
- 開発セットを用いない指標(予測バイアス)を導入してプロンプト品質を評価する。
- ほぼ最適なプロンプトを見つけるための二つの効率的なプロンプト探索戦略(T-fair-Prompting と G-fair-Prompting)を提案する。
- 複数のLLMと下流のテキスト分類タスクにわたってアプローチを検証する。
- モデル微調整なしでバイアス指向のプロンプトの解釈性と実用性を強調する。
提案手法
- コンテンツフリー入力を定義し、予測分布を測定してエントロピー(Eq. 2)によりフェアネススコアを計算する。
- より高いプロンプトバイアスが予測品質の低下と相関することを示し、バイアスベースのプロンプト探索を動機づける。
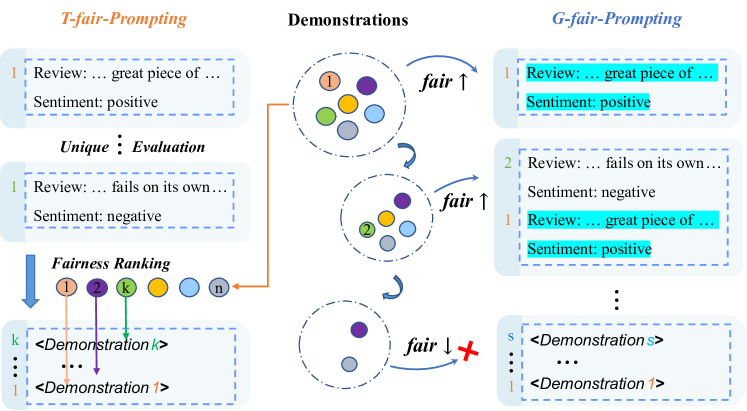
- 二つの探索戦略を提案する:T-fair-Prompting(線形時間、最も公平な単一デモを上位k個選択)と G-fair-Prompting(貪欲法、改善された探索品質を伴い O(N^2))
- 公正指標を fair(ρ) = - sum_y p(y|ρ ⊕ η) log p(y|ρ ⊕ η) と形式化する。
- 開発セットを用いずにプロンプトを評価するためにコンテンツフリー入力を使用し、開発セットに依存しない評価を可能にする。
- 各ステップで公正性を高めるデモンストレーションを挿入することにより、局所的から全体へバイアス削減を実証する。
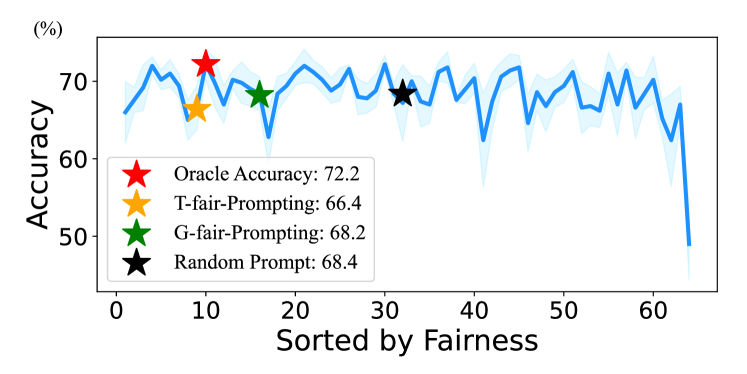
実験結果
リサーチクエスチョン
- RQ1固定プロンプトの予測バイアス(フェアネス)は、タスクとモデルを問わず下流のICL性能と相関するか?
- RQ2微調整なしに元の(テキスト)空間でバイアス指向探索戦略がほぼ最適なプロンプトを効率的に特定できるか?
- RQ3T-fair-Prompting および G-fair-Prompting は、既存の多様性/類似性ベースのプロンプト探索法やキャリブレーションベースのアプローチとどのように比較されるか?
- RQ4複数のLLMに対して提案手法の探索コストと性能向上のトレードオフはどうなるか?
主な発見
- コンテンツフリー入力から算出されたフェアネススコアは、モデルとデータセット全体でより高いタスク性能と相関する。
- G-fair-Prompting は全てのプロンプトの列挙をほぼ近似し、一貫して T-fair-Prompting を上回る。
- G-fair-Prompting と、より限定的だが T-fair-Prompting は、複数のタスクとモデルで多様性・類似性ガイドのベースラインを上回る。
- ポストキャリブレーションは一部のプロンプトには役立つが、質の低いプロンプトでは性能を損なう可能性があり、バイアス指向のプロンプト探索の価値を強調する。
- 提案手法は、GPTシリーズとLLaMAファミリーモデルにわたり、SOTAプロンプティング戦略を一貫して相対的に改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。