[論文レビュー] Fairness of ChatGPT and the Role Of Explainable-Guided Prompts
この論文は、プロンプト設計とドメイン知識を用いた OpenAI の GPT による信用リスク評価を検討し、従来の ML に比べてはるかに少ないデータで競争的な結果を示し、性別にかかわる公平性についての洞察を提供する。
Our research investigates the potential of Large-scale Language Models (LLMs), specifically OpenAI's GPT, in credit risk assessment-a binary classification task. Our findings suggest that LLMs, when directed by judiciously designed prompts and supplemented with domain-specific knowledge, can parallel the performance of traditional Machine Learning (ML) models. Intriguingly, they achieve this with significantly less data-40 times less, utilizing merely 20 data points compared to the ML's 800. LLMs particularly excel in minimizing false positives and enhancing fairness, both being vital aspects of risk analysis. While our results did not surpass those of classical ML models, they underscore the potential of LLMs in analogous tasks, laying a groundwork for future explorations into harnessing the capabilities of LLMs in diverse ML tasks.
研究の動機と目的
- ChatGPT のような LLM が限定的なデータで信用リスク分類を実行できるかを調査する。
- プロンプト設計とドメイン知識が予測精度にどう影響するかを評価する。
- ブートストラップに基づく真陽性率の比較と統計検定を用いて性別の公平性を検討する。
- LLM を用いた機械学習タスクを改善するための、ドメイン知識とプロンプト戦略の統合に関するガイドラインを提供する。
提案手法
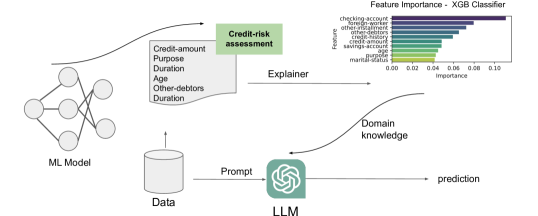
- Credit risk task を ChatGPT-3.5-Turbo を用いたチャットベースの予測問題へ変換する。
- タスク指示、インコンテキスト例、属性説明、ドメイン知識、および問題設定を含む複数部のプロンプトを設計する。
- ML由来の特徴重要度(MLFI)とその順序付けされた変種(MLFI-ord)を介してドメイン知識を組み込む。
- ドイツの信用データセットを用いた5分割交差検証で、古典的なMLモデルとOpenAIベースのモデルの性能を評価する。
- ブートストラップサンプリング(1000 回の再標本化)を用いて真陽性率の差を通じて性別の公平性を評価する。
- モデル間での精度、適合率、再現率、F1、偽陽性/偽陰性のコストを比較する。
実験結果
リサーチクエスチョン
- RQ1慎重に設計されたプロンプトとドメイン知識を用いた ChatGPT は、従来の ML よりはるかに少ないデータで競争力のある信用リスク予測を達成できるか?
- RQ2ドメイン知識と特徴順序を含むプロンプト設計が、OpenAI ベースの予測の精度と公平性にどのように影響するか?
- RQ3クレジットリスク評価において、OpenAI ベースのモデルは従来の ML モデルと比較して性別の公平性特性が異なるか?
- RQ4LLM を用いた機械学習タスクを改善するための、プロンプト設計とドメイン知識の統合に関する実践的ガイドラインは何か?
主な発見
| モデル | DKタイプ | MLモデル | Pre. | Rec. | F1 | FPコスト | FNコスト |
|---|---|---|---|---|---|---|---|
| RF | - | - | 0.8153 | 0.9078 | 0.8591 | 145.0 | 13.0 |
| LR | - | - | 0.7368 | 0.8936 | 0.8077 | 225.0 | 15.0 |
| MLP | - | - | 0.7654 | 0.8794 | 0.8185 | 190.0 | 17.0 |
| KNN | - | - | 0.7707 | 0.8582 | 0.8121 | 180.0 | 20.0 |
| XGB | - | - | 0.8077 | 0.8936 | 0.8485 | 150.0 | 15.0 |
| AdaBoost | - | - | 0.7875 | 0.8936 | 0.8372 | 170.0 | 15.0 |
| random | - | - | 0.7625 | 0.4326 | 0.5520 | 95.0 | 80.0 |
| Avg. | - | - | 0.7792 | 0.8822 | 0.8302 | 172.5 | 15.6 |
| prompt-0 | N/A | - | 0.7625 | 0.4326 | 0.5520 | 95.0 | 80.0 |
| prompt-1 | MLFI | XGB | 0.7083 | 0.7234 | 0.7158 | 210.0 | 39.0 |
| prompt-2 | MLFI-ord | XGB | 0.6842 | 0.5532 | 0.6118 | 180.0 | 63.0 |
| prompt-3 | MLFI | RF | 0.7206 | 0.6950 | 0.7076 | 190.0 | 43.0 |
| prompt-4 | MLFI-ord | RF | 0.7087 | 0.5177 | 0.5984 | 150.0 | 68.0 |
| prompt-5 | MLFI | Ada | 0.7305 | 0.7305 | 0.7305 | 190.0 | 38.0 |
| prompt-6 | MLFI-ord | Ada | 0.7404 | 0.5461 | 0.6286 | 135.0 | 64.0 |
| prompt-7 | MLFI | LR | 0.7154 | 0.6596 | 0.6863 | 185.0 | 48.0 |
| prompt-8 | MLFI-ord | LR | 0.6957 | 0.4539 | 0.5494 | 140.0 | 77.0 |
| prompt-9 | MLFI | ensemble | 0.7209 | 0.6596 | 0.6889 | 180.0 | 48.0 |
| prompt-10 | MLFI-ord | ensemble | 0.7037 | 0.5390 | 0.6104 | 160.0 | 65.0 |
- OpenAI ベースのモデルは、古典的な ML モデルの 800 件に対して訓練データが 20 サンプルのみで競争力のある結果を達成する。
- AdaBoost は MLFI プロンプトを用いた構成の中で高い適合率・再現率・F1(0.7305)を達成する。
- 従来の ML モデルは平均精度指標で OpenAI ベースのモデルを上回る(精度 0.7792 対 0.7129、リコール 0.8822 対 0.6078、F1 0.8302 対 0.6528)。
- OpenAI モデルは従来型 ML モデルと比べ偽陽性コストが低く、より慎重なクレジット承認傾向を示す。
- 公平性分析は、特定のプロンプト(例: Prompt-5、Prompt-7)が非有意な性別格差に接近する一方、他は有意差を示す。従来モデルは一般に公平性の帰無仮説を棄却(有意な差)である。
- プロンプトは時にはアウトカムの公平性を促進することがあり、LLM を用いた ML タスクにおけるプロンプトベースの公平性考慮の可能性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。