[論文レビュー] Fast Training of Diffusion Models with Masked Transformers
MaskDiT は入力パッチの50%をマスクし、DSM を未マスクパッチに適用する非対称エンコーダ–デコーダとマスク済みパッチの MAE 風再構成を組み合わせることで、DiT の約31%の訓練時間で競争力のある FID を達成します。
We propose an efficient approach to train large diffusion models with masked transformers. While masked transformers have been extensively explored for representation learning, their application to generative learning is less explored in the vision domain. Our work is the first to exploit masked training to reduce the training cost of diffusion models significantly. Specifically, we randomly mask out a high proportion (e.g., 50%) of patches in diffused input images during training. For masked training, we introduce an asymmetric encoder-decoder architecture consisting of a transformer encoder that operates only on unmasked patches and a lightweight transformer decoder on full patches. To promote a long-range understanding of full patches, we add an auxiliary task of reconstructing masked patches to the denoising score matching objective that learns the score of unmasked patches. Experiments on ImageNet-256x256 and ImageNet-512x512 show that our approach achieves competitive and even better generative performance than the state-of-the-art Diffusion Transformer (DiT) model, using only around 30% of its original training time. Thus, our method shows a promising way of efficiently training large transformer-based diffusion models without sacrificing the generative performance.
研究の動機と目的
- 大規模拡散モデルの訓練コストを生成品質を犠牲にせず削減する動機付け。
- 拡散モデルの逐次計算・メモリを削減するためのマスク付きトランスフォーマー訓練を活用。
- マスク入力を扱うための非対称エンコーダ–デコーダ骨格と二重目的を提案。
- ImageNet-256×256 で訓練時間を大幅に削減しつつ競争的な生成性能を示す。
提案手法
- エンコーダが未マスクパッチで動作し、軽量デコーダが全トークンを処理する非対称エンコーダ–デコーダ・トランスフォーマー骨格を採用。
- 拡散モデル訓練中に入力パッチの高割合(50%)をランダムにマスクし、1回あたりの計算を削減。
- 2 部分の訓練目的を導入:未マスクパッチでのノイズ除去スコア整合(DSM)、マスク済みパッチでの MAE風再構成損失。
- 同じマスク割合を timestep 全体で用い、訓練と推論のギャップを小さくする最小限のマスク解除調整を後で実施。
- マスク訓練後の CFG サンプリング性能を向上させるため、マスク解除調整スケジュール(ゼロ比、コサイン比)を使用。
- ImageNet-256×256 で FID などの指標を用いて評価し、DiT および MDT のベースラインと、クラス非依存指導(CFG)有無を比較。
![Figure 1 : A comparison of our MaskDiT architecture with DiT [ 33 ] . During training, we randomly mask a high proportion of input patches. The encoder operates on unmasked patches, and after adding learnable masked tokens (marked by gray), full patches are processed by a small decoder. The model is](https://ar5iv.labs.arxiv.org/html/2306.09305/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1マスク付きトランスフォーマー訓練は、生成性能を犠牲にすることなく拡散モデルの訓練コストを削減できるか。
- RQ2拡散モデルにおけるマスク入力を扱うための適切なアーキテクチャと訓練目的はどう設計すべきか。
- RQ3マスク割合、再構成損失のウェイト、マスク解除調整の組み合わせはモデル品質にどのようなトレードオフをもたらすか。
- RQ4MaskDiT は ImageNet-256×256 で最先端の拡散モデルと比較して効率とサンプル品質においてどの程度優位性を示すか。
- RQ5指導(CFG)とマスク解除調整が最終的な生成指標に与える影響はどの程度か。
主な発見
| Method | FID↓ | sFID↓ | IS↑ | Prec.↑ | Rec.↑ |
|---|---|---|---|---|---|
| MaskDiT | 5.69 | 10.34 | 177.99 | 0.74 | 0.60 |
| MaskDiT-G | 2.28 | 5.67 | 276.56 | 0.80 | 0.61 |
| DiT-XL/2 | 2.27 | 4.60 | 278.24 | 0.83 | 0.57 |
| MDT-XL/2-G | 1.79 | 4.57 | 283.01 | 0.81 | 0.61 |
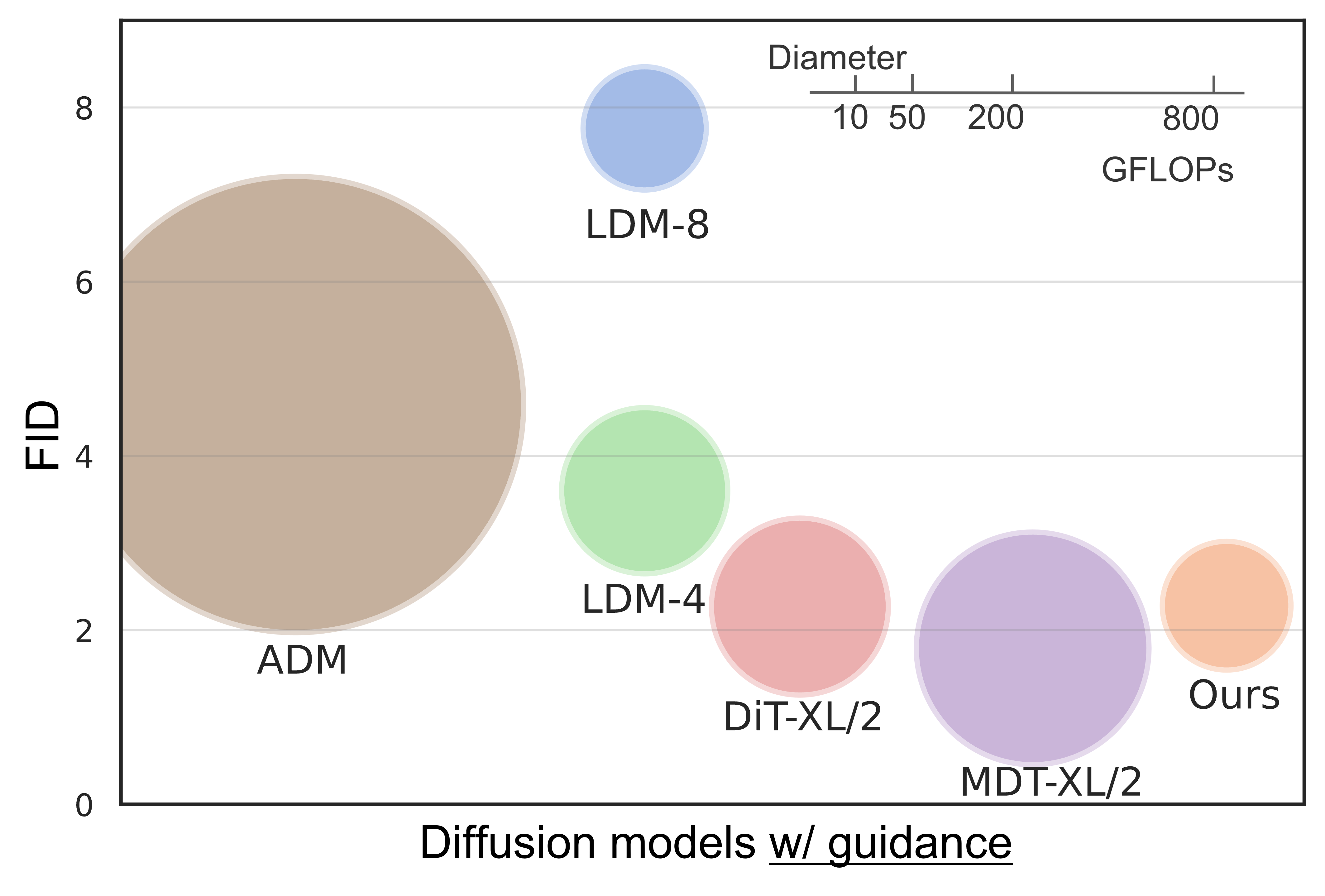
- MaskDiT は CFG なしで ImageNet-256×256 で 5.69 の FID を達成し、複数の非カスケード拡散モデルを上回り、指導付きで最先端に近づく。
- 分類子なしの指導を用いると MaskDiT は 2.28 の FID を達成し、DiT-XL/2-G(2.27)と同等程度ながら DiT-XL/2 に対する訓練時間を約31%に抑える。
- 1GPUあたりの訓練速度とメモリ使用量が大幅に削減され、前方伝搬あたり DiT の 54.0%、MDT の 31.7% の GFLOPs を使用し、特にバッチサイズ 1024 での実時間収束が速い。
- MaskDiT-G(指導付き)は最良の指導モデルに近い性能を、MDT-XL/2-G と比較して計算コストを抑えつつ達成。
- MAE 再構成損失(MAE 係数約 0.1)を DSM 損失と未マスクトークンに対する組み合わせで生成品質と安定性を改善。
- マスク解除調整は CFG 性能をさらに向上させ、調整ステップが増えるにつれて最適なガイダンススケールが上方に移動する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。