[論文レビュー] FeatUp: A Model-Agnostic Framework for Features at Any Resolution
FeatUpは深層特徴を意味を変えずに高い空間解像度へアップスケールします。高速なJBUベースのアップサンプラーまたは画像ごとに暗黙的なモデルのいずれかを用い、多視点の一貫性に導かれて動作します。
Deep features are a cornerstone of computer vision research, capturing image semantics and enabling the community to solve downstream tasks even in the zero- or few-shot regime. However, these features often lack the spatial resolution to directly perform dense prediction tasks like segmentation and depth prediction because models aggressively pool information over large areas. In this work, we introduce FeatUp, a task- and model-agnostic framework to restore lost spatial information in deep features. We introduce two variants of FeatUp: one that guides features with high-resolution signal in a single forward pass, and one that fits an implicit model to a single image to reconstruct features at any resolution. Both approaches use a multi-view consistency loss with deep analogies to NeRFs. Our features retain their original semantics and can be swapped into existing applications to yield resolution and performance gains even without re-training. We show that FeatUp significantly outperforms other feature upsampling and image super-resolution approaches in class activation map generation, transfer learning for segmentation and depth prediction, and end-to-end training for semantic segmentation.
研究の動機と目的
- 再学習や意味の変更を伴わず、深層特徴表現で失われた空間解像度を回復する必要性を喚起する。
- 低解像度のビューから高解像度の特徴を再構成するために多視点の一貫性を強制するフレームワークとしてFeatUpを提案する。
- 高速なフォワード型JBUベースのアップサンプラーと、画像ごとに暗黙的に扱うアップサンプラーの2つの変種を提示する。
- FeatUpが意味セマンティックセグメンテーション、深度推定、CAMの説明性などの下流タスクを改善することを示す。
提案手法
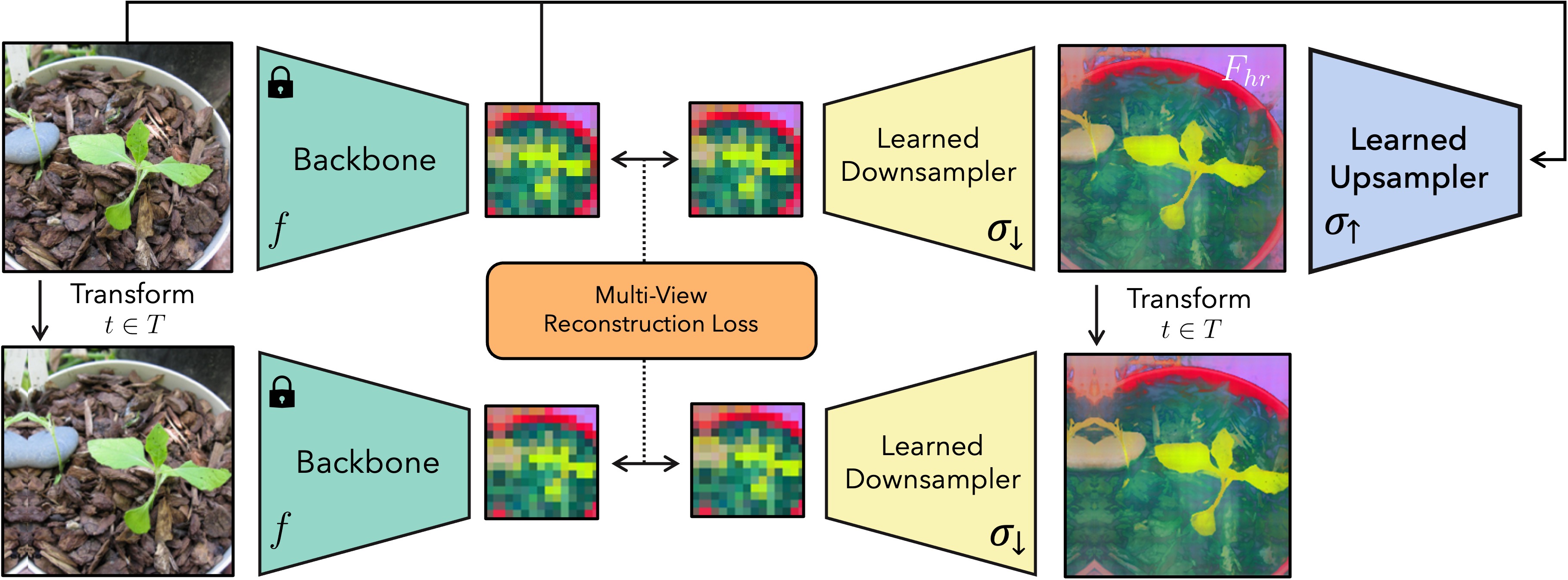
- パディング、スケール、反転などのジャittered入力変換を横断した多視点の一貫性を用いて深層特徴をアップサンプリングする。
- アップサンプリングアーキテクチャを2つ提供する: (i) 迅速なガイド付きフォワードモジュールとしてのJoint Bilateral Upsampler (JBU); (ii) 任意の解像度出力に対して単一画像にMLPを過適合させるImplicit FeatUp。
- 高解像度特徴を低解像度ビューへ写像する学習済みダウンサンプラー(単純なブラーまたは注意機構ベース)を導入する。
- 適応的不確実性項を用いて、高解像度特徴をダウンサンプルして低解像度バックボーン出力と一致させる多視点再構成損失を使用する。
- 効率のためのCUDA加速JBU実装を提供し、収束を高めるためにImplicitモデルにはフーリエベースの特徴を任意追加。
- Implicit特徴の大きさを安定化させるために小さな総変動(Total Variation)事前項を適用する。)
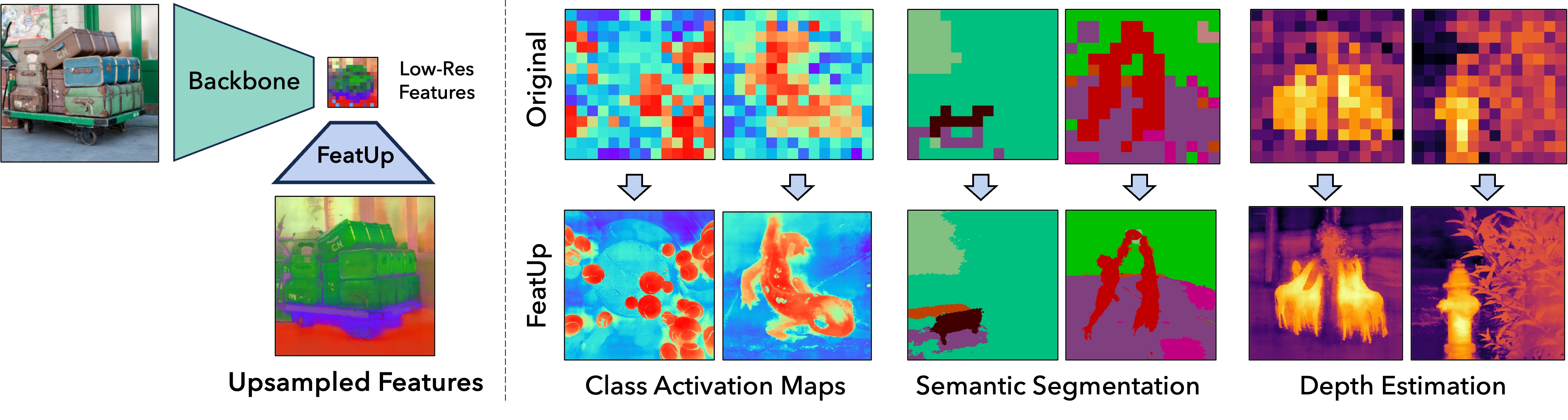
実験結果
リサーチクエスチョン
- RQ1深層特徴の空間解像度は、バックボーンを再学習させずに意味を変えずに大幅に向上させられるか?
- RQ2画像ジッター間の多視点一貫性は高解像度特徴の再構成に対して頑健な監視信号を提供するか?
- RQ3高速なJBUベースと暗黙的な画像ごとのアップサンプリングアプローチは、バックボーンやタスクを跨いで品質・速度・メモリフットプリントの点でどう比較されるか?
- RQ4FeatUp特徴はダウンストリームの密な予測とモデルの説明性を改善するドロップイン置換として機能するか?
- RQ5FeatUp由来の特徴はモデル解釈性のためのCAM品質に測定可能な向上をもたらすか?
主な発見
| 手法 | CAMスコア A.D.↓ | CAMスコア A.I.↑ | 意味セグメンテーション mIoU↑ | 意味セグメンテーション 精度↑ | Depth RMSE↓ | Depth δ>1.25↑ |
|---|---|---|---|---|---|---|
| Low-res | 10.69 | 4.81 | 65.17 | 40.65 | 1.25 | 0.894 |
| Bilinear | 10.24 | 4.91 | 66.95 | 42.40 | 1.19 | 0.910 |
| Resize-conv | 11.02 | 4.95 | 67.72 | 42.95 | 1.14 | 0.917 |
| DIP | 10.57 | 5.16 | 63.78 | 39.86 | 1.19 | 0.907 |
| Strided | 11.48 | 4.97 | 64.44 | 40.54 | 2.62 | 0.900 |
| Large image | 13.66 | 3.95 | 58.98 | 36.44 | 2.33 | 0.896 |
| CARAFE | 10.24 | 4.96 | 67.10 | 42.39 | 1.09 | 0.920 |
| SAPA | 10.62 | 4.85 | 65.69 | 41.17 | 1.19 | 0.917 |
| FeatUp (JBU) | 9.83 | 5.24 | 68.77 | 43.41 | 1.09 | 0.938 |
| FeatUp (Implicit) | 8.84 | 5.60 | 71.58 | 47.37 | 1.04 | 0.927 |
- FeatUpはCAMの忠実性、意味セグメンテーション、深度推定のすべてにおいて、ベースラインのアップサンプリング手法(バイリニア、リサイズ-畳み込み、DIP等)を一貫して上回る。
- FeatUpの2つの変種(JBUとImplicit)は、より高品質な高解像度特徴を提供し、いくつかの指標でImplicit変種が下流タスクで最も強い改善を達成する。
- 転移学習実験において、FeatUp特徴は意味セグメンテーションのリニアプローブ性能(mIoU)と深度推定(RMSE、delta>1.25)を改善する。
- FeatsUpアップサンプリングはエンドツーエンドのセグメンテーションモデルのドロップイン置換として使用でき、平均IoU、平均精度、ピクセル精度を改善しつつFLOPs/パラメータは競合的。
- CUDA加速のJBU実装は、素朴な実装と比較して最大約10倍の速度向上と大幅なメモリ使用量削減を提供。
- Implicit FeatUpはフーリエカラー特徴の恩恵を受け、収束速度と高周波のディテール捕捉を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。