[論文レビュー] FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
FedMKT は、サーバーサイド LLM と複数のクライアントサイド SLM の間で、トークン整列と選択的蒸留を用いて共同的にサーバーとクライアントの両方のモデルを改善する、連邦型の相互知識伝達フレームワークを提案します。
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate that FedMKT simultaneously boosts the performance of both LLMs and SLMs.
研究の動機と目的
- サーバーサイド LLM とクライアントサイド SLM の間のギャップを埋め、相互知識伝達を可能にする。
- 通信と計算コストを削減するために LoRA アダプターを用いたパラメータ効率の高い方法を開発する。
- トークン整列と選択的知識伝達によってモデルのヘテロジニティに対処し、双方の性能向上を保証する。
- 複数の NLP タスクで公的な LLM/SLM を用いて、ヘテロジニアス、ホモジニアス、ワン・ツー・ワンの設定における FedMKT を評価する。
提案手法
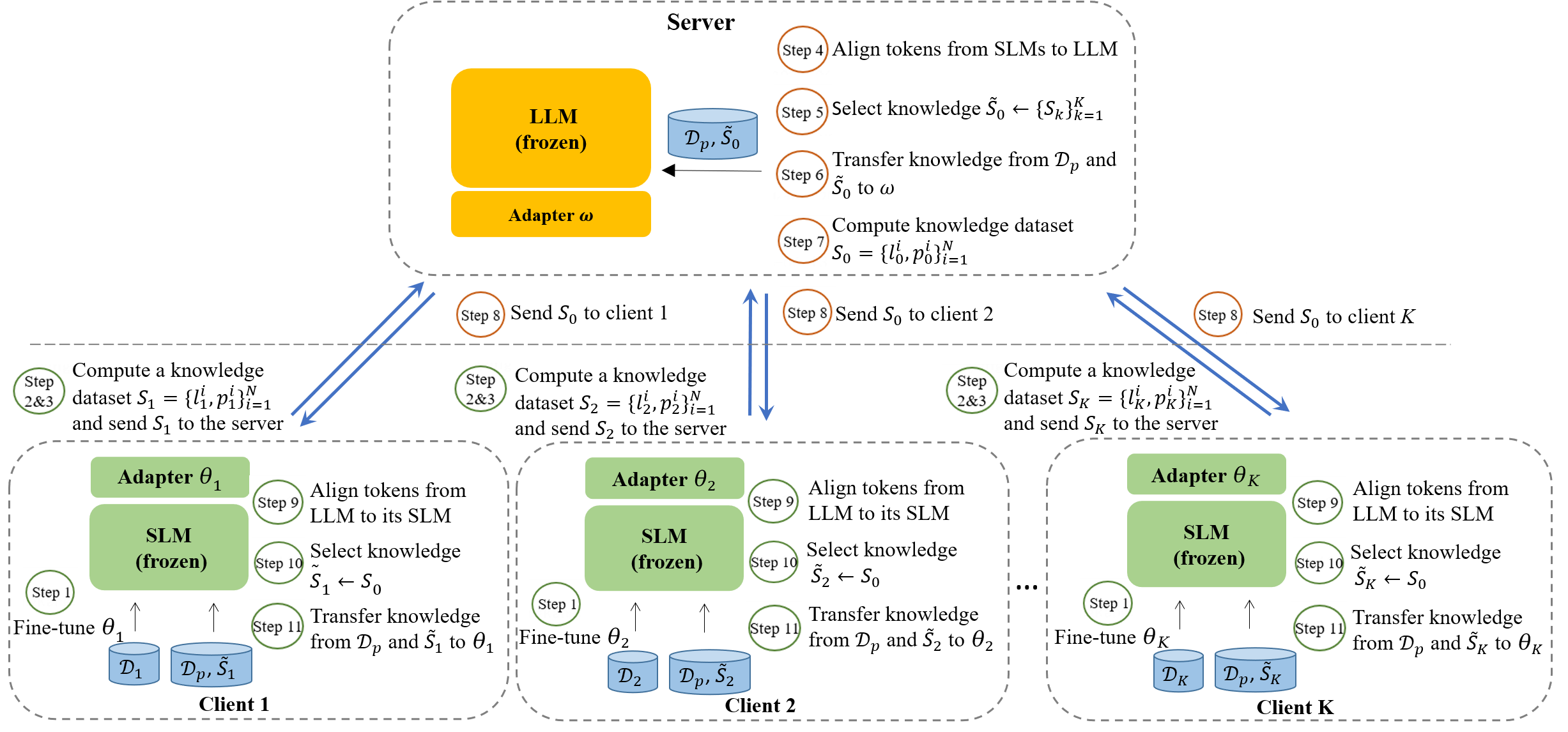
- 2つの主要モジュール: 双方向トークン整列と選択的相互知識伝達。
- LLMとSLMの語彙間のロジットを揃えるために、最小編集距離(MinED)に基づくトークンマッピングを用いる。
- パラメータ効率的な更新を可能にするため、サーバー(omega)とクライアント(theta)の両方に LoRA アダプターを用いる。
- 公的データセットに基づく集中型ダブル蒸留目的関数(DualMinCE)を用いて相互伝達の正の知識を選択する。
- 交互訓練: クライアントはプライベートデータで局所的にファインチューニングし、公開データ上でロジットを交換する。サーバーはクライアントのロジットから蒸留し、クライアントへ再分配する。
- 目的項L2とL3は、ファインチューニング損失と蒸留損失をバランスパラメータ lambda で結合する。
実験結果
リサーチクエスチョン
- RQ1連邦学習設定で、サーバー LLM とヘテロジニアスなクライアント SLM の間で効果的な相互知識伝達をどのように実現できるか。
- RQ2MinEDによるトークン整列は、ロジットベースの知識伝達におけるトークナイザの異種性を緩和できるか。
- RQ3選択的相互知識伝達は、ヘテロジニアス、ホモジニアス、ワン・ツー・ワン設定を含むベースラインと比較して、サーバー LLM とクライアント SLM の両方の性能を向上させるか。
主な発見
- FedMKT は、ヘテロ設定において、クライアントの SLM に対してゼロショットおよび独立ベースラインを一貫して上回る。8 タスクで。
- FedMKT を用いたサーバー LLM はいくつかのタスクで集中型微調整の性能に近づき、あるあるシナリオでは RTE で集中型パフォーマンスの約96% を達成する。
- ホモジニアス設定では、FedMKT はゼロショットを上回るサーバー LLM の利得を生み、集中型に対して競争力のある結果を示し、SLMs も向上させる。
- ワン・ツー・ワン設定では、FedMKT はゼロショットを上回り、サーバー LLM の集中型パフォーマンスに匹敵し、LLM からのガイダンスによって SLM の性能を改善する。
- 実験は複数のモデルペア(サーバー LLM と多様なクライアント SLM)と3つの設定を対象とし、フレームワークの汎用性を示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。