[論文レビュー] FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation
FETV はオープンドメインの Text-to-Video 生成のための細粒度・多面的・時系列認識ベンチマークを導入し、自動指標の信頼性を人間の判断と比較して分析し、UMT に基づく改善指標を提案する。
Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability in different scenarios. We find that existing automatic metrics (e.g., CLIPScore and FVD) correlate poorly with human evaluation. To address this problem, we explore several solutions to improve CLIPScore and FVD, and develop two automatic metrics that exhibit significant higher correlation with humans than existing metrics. Benchmark page: https://github.com/llyx97/FETV.
研究の動機と目的
- 複数のプロンプトカテゴリにわたるオープンドメイン T2V モデルの細粒度評価フレームワークを提供する。
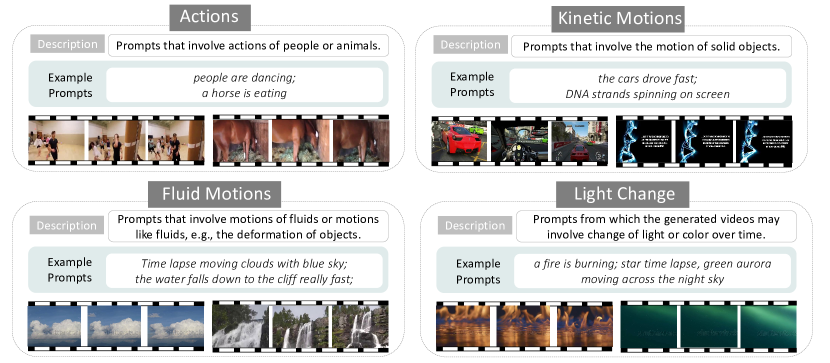
- T2V 生成における動画固有の課題を捉えるために時系列認識を組み込む。
- 既存の自動評価指標の人間の判断に対する信頼性を評価する。
- 高度なビジョン-言語モデルを用いて人間の評価に合わせた改善された自動指標を提供する。
提案手法
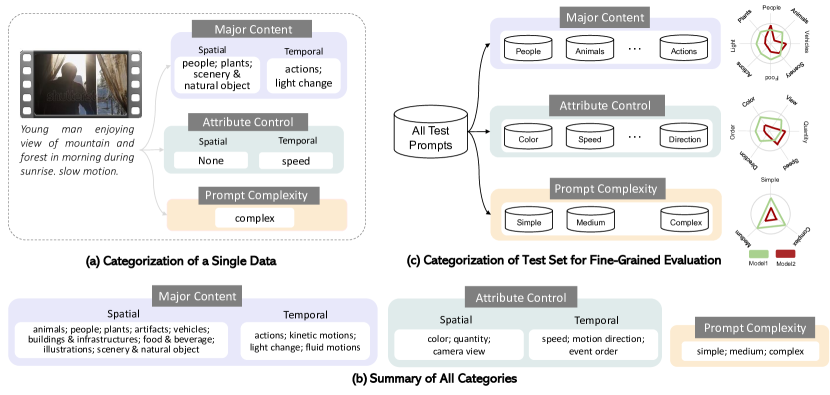
- FETV を提案する。主要な内容、属性制御、プロンプトの複雑さで分類されたプロンプトを備え、動画生成のための時系列カテゴリを追加したベンチマーク。
- MSR-VTT、WebVid からの 619 個のカテゴリ分類済みプロンプトを収集し、手動で作成した珍しいプロンプトも含めて、カテゴリの自動ラベリングを行い、その後手動ラベリングを適用する。
- 4つのオープン T2V モデルを、静的品質、時間的品質、全体的一致、細粒度一致の4つの視点で manual 評価を実施し、動画ごとに各モデルにつき3名の人間採点者で評価する。
実験結果
リサーチクエスチョン
- RQ1オープンドメイン T2V モデルは、内容、属性、複雑さの細粒度カテゴリ全体でどのように性能を発揮するか?
- RQ2時間的内容が動画品質とプロンプトとの整合性にどう影響するか?
- RQ3自動 T2V 指標は人間の判断とどの程度相関するのか、改善可能か?
- RQ4高度なビジョン-言語モデルに基づく新しい指標は、カテゴリを横断して人間の評価とより良く一致するか?
- RQ5多様なプロンプトの下で代表的なオープン T2V モデルの長所と短所は何か?
主な発見
- 動画品質はアクション・運動の要素や空間的内容における人や動物に対して低下する。
- 量の制御、運動方向、イベント順序の制御においてモデルの能力は異なる;現行モデルはこれらの属性で苦労している。
- 自動指標 CLIPScore と FVD は人間の評価と相関が乏しい;UMTScore と FVD-UMT は人間との相関が高い。
- ファインチューニング済みまたは高度な VLM ベースの指標(UMTScore、FVD-UMT)は、従来の指標より人間のランキングとよりよく整合する。
- manual評価は、CogVideo、Text2Video-zero、ModelScopeT2V、ZeroScope のカテゴリ横断の実用的な長所と短所を明らかにする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。