[論文レビュー] FICE: Text-Conditioned Fashion Image Editing With Guided GAN Inversion
FICE編集はテキスト記述を用いてGAN逆変換を導きファッション画像を編集し、姿勢と同一性を保持しつつ、CLIPベースの意味論と画像継ぎ目処理によって新しい衣服を統合します。
Fashion-image editing represents a challenging computer vision task, where the goal is to incorporate selected apparel into a given input image. Most existing techniques, known as Virtual Try-On methods, deal with this task by first selecting an example image of the desired apparel and then transferring the clothing onto the target person. Conversely, in this paper, we consider editing fashion images with text descriptions. Such an approach has several advantages over example-based virtual try-on techniques, e.g.: (i) it does not require an image of the target fashion item, and (ii) it allows the expression of a wide variety of visual concepts through the use of natural language. Existing image-editing methods that work with language inputs are heavily constrained by their requirement for training sets with rich attribute annotations or they are only able to handle simple text descriptions. We address these constraints by proposing a novel text-conditioned editing model, called FICE (Fashion Image CLIP Editing), capable of handling a wide variety of diverse text descriptions to guide the editing procedure. Specifically with FICE, we augment the common GAN inversion process by including semantic, pose-related, and image-level constraints when generating images. We leverage the capabilities of the CLIP model to enforce the semantics, due to its impressive image-text association capabilities. We furthermore propose a latent-code regularization technique that provides the means to better control the fidelity of the synthesized images. We validate FICE through rigorous experiments on a combination of VITON images and Fashion-Gen text descriptions and in comparison with several state-of-the-art text-conditioned image editing approaches. Experimental results demonstrate FICE generates highly realistic fashion images and leads to stronger editing performance than existing competing approaches.
研究の動機と目的
- ターゲットとなる衣服画像を必要としない自然言語の説明でファッション画像の編集を促進・実現する。
- 被写体の姿勢・アイデンティティ・背景を保持しつつ、衣服領域のみを編集する。
- CLIPと補助の微分可能モデルを活用して、逆変換中に意味論・姿勢・画像の整合性制約を強制する。
- 潜在コード正則化を導入して現実感を高め、編集を明確に定義された潜在空間に制約する。
提案手法
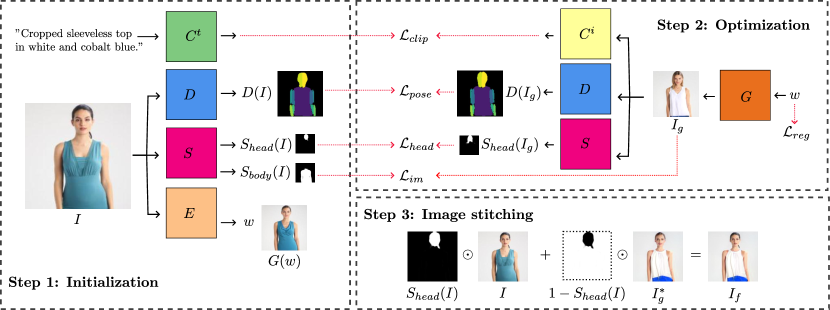
- 初期化、制約付きGAN逆変換、画像継ぎ目処理の3段階パイプラインを使用する。
- 事前学習済みのStyleGAN2ジェネレーターを編集のバックボーンとして用いる。
- テキスト記述と編集済み画像を整合させるためにCLIPベースの意味論的損失を使用する。
- 姿勢保持のためのDensePoseと領域認識編集のためのセグメンテーションモデルを組み込む。
- W+空間で拡張潜在コードを正則化し、空間間の分布ドリフトを低減する。
- 編集領域を元の画像と継ぎ合わせてアイデンティティを保持し、アーティファクトを最小化する。

実験結果
リサーチクエスチョン
- RQ1テキスト記述だけで、姿勢とアイデンティティを保持しつつ現実的なファッション画像編集を導くことができますか?
- RQ2CLIPベースの意味論・姿勢制約・領域認識損失は、汎用的なGAN編集と比べて優れたテキスト駆動編集を生み出しますか?
- RQ3StyleGANベースのファッション編集において、潜在コード正則化は現実感と編集の一貫性を向上させますか?
- RQ4VITONおよびFashion-Genデータセットの実世界ファッション画像とテキスト記述を組み合わせた場合、FICEはどのように機能しますか?
主な発見
- FICEは姿勢とアイデンティティを保持した高度に現実的なファッション編集を生成します。
- FICEは定性的・定量的評価の両面で競合するテキストベースの編集手法を上回ります。
- CLIP意味論・姿勢保持・画像領域損失の組み合わせは、説得力のある衣服統合を生み出します。
- 潜在コード正則化は、拡張されたW+コードを元の潜在空間と整合させることで画像の現実感を維持します。
- 画像継ぎ目処理はさらに忠実度を高め、領域境界のアーティファクトを減らします。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。